当前位置:网站首页>Huawei Cloud Database Advanced Learning
Huawei Cloud Database Advanced Learning
2022-06-24 07:11:00 【Cheng Siyang】
Préface
Cet article est divisé en3Introduction de chapitres:
No1Chapitre Comment atteindre une disponibilité élevée
No2Chapitre Optimisation des performances
No3Chapitre Introduction de solutions pour chaque industrie
J'espère que cet article vous permettra de comprendre les points de douleur de l'industrie et les paramètres et fonctions techniques de la base de données,Pour comprendre les paramètres techniques de la base de données,Les capacités d'exploitation et de maintenance de la base de données Cloud sont utiles,Et peut fournir des solutions complètes selon des scénarios spécifiques
1、 Interprétation et réglage des paramètres techniques de la base de données
1. Qu'est - ce queRDS MySQLHaute disponibilité
Surveillance en temps réel grâce à un logiciel de surveillanceHAÉtat des bibliothèques primaires et secondaires du cluster,Après avoir découvert que la bibliothèque principale était en panne,Commutation automatique des rôles primaire et secondaire par des composants hautement disponibles,Et la cohérence des données,Réduire efficacement le temps d'indisponibilité des services les grappes qui ont cette capacité sont des grappes très disponibles,Par exemple:RDS MySQLDeHACluster
2. RDS MySQLHaut niveau de disponibilité
• Même chose.AZ:Cross - physical machineHACluster(Machines physiques déployées dans différentes armoires avec alimentation électrique indépendante)
• CrossAZ:De l'autre côté de la salle des machinesHACluster
• Crossregion:TransrégionaleHACluster
3. RDS MySQLMécanisme de commutation très disponible
• MySQLHAL'état du cluster passe parMonitorComposants surveillés en temps réel,VIPLié à l'hôte,.Synchronisation des données entre maître et esclave par réplication maître - esclave
• En cas de défaillance de l'hôte,MonitorSera automatiquement lancé3Connexion secondaire à l'hôte
• Si3Tous ont échoué.,MonitorLe commutateur de secours principal sera lancé,D'abord.VIPDégroupage,À rejouer par la machine de secours
• C'est tout.relaylog Après avoir rattrapé l'ordinateur central , Ascenseur de secours ,VIP Se lier au nouvel hôte ( Machine de secours d'origine )
• Après la naissance du nouvel hôte , Si l'hôte original a été restauré , Rétablir la relation maître - esclave
• Si l'hôte d'origine n'est pas récupérable , La défaillance de l'hôte d'origine doit être résolue manuellement. , Répéter manuellement la relation maître - esclave





2、 Optimisation des performances
1. Mesure de la pression de performance
1. Objet de l'essai de pression
.Tout d'abord, nous devons comprendre pourquoi la mesure de pression ?
.Avant l'essai de pression, assurez - vous que le but de l'essai de pression est différent , Il est nécessaire de concevoir différents systèmes de mesure de la pression les objectifs communs de la mesure de la pression sont :
• Tester les performances de la nouvelle version de la base de données
• Vérifier certains DB/OSParamètres du niveau
• Tester l'impact des différents magasins sur la performance de la base de données
• Tester la performance de la base de données dans différents scénarios
2. Facteurs d'influence
Facteurs influant sur le rendement de la base de données
Avant l'essai de pression de performance , En raison d'une compréhension approximative des facteurs qui influent sur le rendement de la base de données, il est généralement divisé en :Niveau de la base de données、Niveau du système、Niveau de stockage、 Au niveau du réseau, etc
Les indicateurs communs à tous les niveaux sont les suivants: :

3. Indicateurs de concentration
Indicateurs de performance pour les préoccupations piézométriques
Les indicateurs de performance communs de la base de données doivent être pris en considération à tout moment pendant le processus de mesure de la pression , Identifier les goulets d'étranglement potentiels en matière de performance
Les indicateurs de rendement communs à la base de données sont principalement classés dans les catégories suivantes :

4. Outils et méthodes
Comment choisir les outils et les méthodes de mesure de la pression ?
PourMySQLEn termes, Il y a beaucoup d'outils de mesure de pression ,Par exemple::sysbeno th、Tpcc-mysql、mysqlslap、tcpcopy .Attendre dans un scénario où il n'y a pas d'exigences spécifiques , En général, choisissez parmi les sysbench En tant qu'outil de mesure de pression, le processus de mesure de pression spécifique est le suivant: :

2. Optimisation de l'index
1. Introduction à l'index
Heap
• Qu'est - ce queheap
heapC'est juste un qui n'a pasclusteredindexUntableUntableSi ce n'est pas le casclustered index,Celui - là.tableLes données deheapAllez., On pourrait aussi dire ça tableC'est unheap
• heapCaractéristiques
(1) Heap Est logiquement une structure plate ,C'est faux.intermediate/root pages
(2) Uniquement parheap Je ne peux pas le faire seul lookupFonctionnement,Seulement dansheapVas - y.scanFonctionnement
(3) HeapDanspageIl n'y en a pas.previouspageOunextpageCe lien
(4) Heap Peut créer un ou plusieurs nonclustered index
Clustered index
• Qu'est - ce queclustered index
InheapCréation d'unclusteredindex,C'esttableC'est devenu unclustered index
• Clustered indexCaractéristiques
Clusteredindex Structure arborescente logiquement adoptée
Clustered indexDeleaflevel nodeGarde ça.tableTouscolumnDonnées
Nonclustered index
• Qu'est - ce quenonclustered index
Nonclusterd indexOui.heapOuclusteredindex Une autre structure indépendante , Il contient nonclusteredindexkey Pour correspondre à heapOuclusteredindex Emplacement du stockage des données dans
• Nonclustered indexCaractéristiques
(1) Untable Vous pouvez créer un ou plusieurs nonclustered index
(2) Nonclustered indexÇa va s'améliorer.selectPerformance de l'opération, Mais ça va baisser dans une certaine mesure update、deletePerformance
(3) Nonclustered indexPas plus, mieux c'est.
(4) Quel genre de index, Selon la demande workloadA quoi ça ressemble?
2. IndexationDMV
• sys.indexes
(1) Chaqueindex(clusteredOunonclustered)Et chaqueheapInsysindexes Il y a une ligne de données correspondante dans
(2) HeapDeindexid- Oui.0
(3) Clustered indexDeindexid- Oui.1
(4) Nonclustered indexDeindexidPlus grand que1
• sys.dm_db_index_physical_stats
(1) Peut être interrogéindexDefragmentationInformation
(2) Vous pouvez voirindexLa différence entrelevelCombien?page
(3) Vous pouvez voirpage Quel pourcentage de l'espace a été utilisé
3. Optimisation lente des requêtes
1. Effets des requêtes lentes
• Pourquoi se concentrer sur les requêtes lentes ?
(1) Pourquoi se concentrer sur les requêtes lentes , C'est parce qu'une requête lente provoque les effets suivants :
(2) Base de donnéescpuCharge élevée
(3) IO Serveur coincé en raison d'une charge élevée , Ralentir les performances de la base de données Sql Plan d'exécution inapproprié , L'exécution prend trop de temps
(4) Augmentation des serrures de base de données ,NormalDDLEtDMLFonctionnement
2. Afficher le Journal des requêtes lentes
• Comment afficher les journaux de requêtes lentes?
(1) Voirmy.cnfDocumentation,Adoptionslow_query_log_file Le paramètre localise l'emplacement du Journal de requête lent
(2) Adoptionvim Ouvrez directement le Journal des requêtes lentes et faites - le un seul slow sq1Analyse
(3) AdoptionmysqldumpslowOupt-query-digest L'outil résume et analyse les journaux de requêtes lentes comme le montre la figure suivante
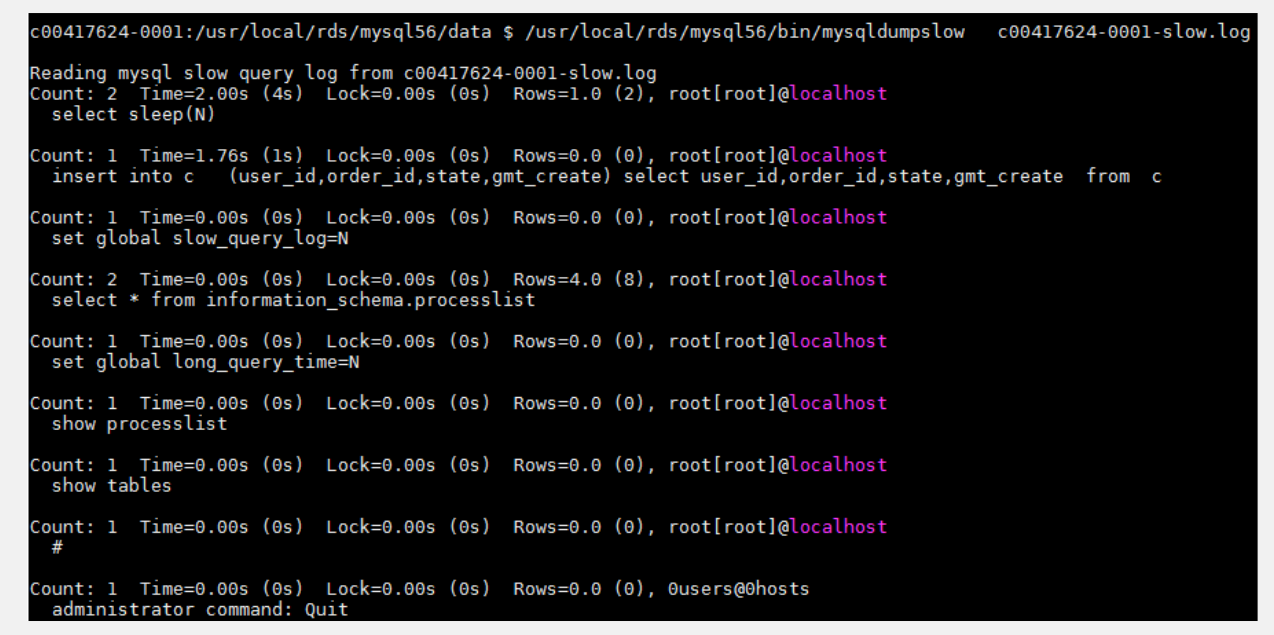
3. Étapes d'optimisation des requêtes lentes
• Pour un ralentissement particulier sqlComment optimiser?
Pour des ralentissements spécifiques sql, Les principales étapes de l'analyse sont les suivantes :
(1) VoirSQLPlan de mise en œuvre:explain sql
(2) Voir l'index du tableau:show index from tb_name;Voir la structure du tableau:show create table tb_name;
(3) AdoptionprofilingRegarde ça.sql Où est passé le plus de temps ?
(4) AdoptionOptimizer TraceObservationsqlProcessus de mise en œuvre,Observationsql Base de sélection du plan d'exécution
3、 Introduction de solutions pour chaque industrie
1. Huawei Cloud Logistics Industry Database Solution
1.1 Huawei Cloud Database Service Product Introduction
• Huawei Cloud Database Service Panorama
GaussDB Auto - recherche pour les clients du Gouvernement et des entreprises , Haute fiabilité 、 Haute performance ; Open source pour les PME ,Excellent rapport qualité - prix

1.2 Aperçu du développement de l'industrie de la logistique
• Logistique4.0, .La modernisation intelligente est une tendance in évitable dans l'industrie de la logistique

• Principaux scénarios de l'industrie de la logistique

• Architecture générale des solutions pour l'industrie de la logistique

1.3 Meilleures pratiques en matière de bases de données de l'industrie de la logistique
• Solutions de base de données pour l'industrie de la logistique intelligente

Le client souffre un peu:
• Grande portée du transport par route , La surveillance du processus de transport est difficile , L'état de santé du véhicule est opaque , Le chemin n'est pas prévu
• Les performances de chargement des tuiles de service de carte sont médiocres ,MongoDB Chargement lent des données sous - jacentes
• Grande quantité d'informations、 Il y a beaucoup de données vidéo ,Mise à jour rapide, L'efficacité et l'exactitude de la logistique sont difficiles à garantir
Huawei Cloud Database Solutions:
• Huawei Cloud DatabaseGaussDB(forMongo)Architecture de séparation des calculs de stockage, Aucune synchronisation primaire / de secours n'est nécessaire , La vitesse d'écriture est hors ligne MongoDB(DDS)De2-4X,AucuneCPU100%Questions
• Utiliser une base de données relationnelle PostgreSQL, Fournir un soutien géographique natif
• Utilisation de données d'état de surveillance non structurées à haute fréquence influxDBOu MongoDB(DDS), Convient à l'enregistrement de données non structurées avec une grande quantité d'écriture
• Des fichiers vidéo plus petits sont disponibles MongoDB(DDS) Services de base de données non institutionnels pour le stockage direct ,Utilisez votre propre GridFS Le module stocke les fichiers
• Cas de base de données des clients de la logistique Express

Utilisation de la base de données des clients de la logistique nationale :
• .Les entreprises de logistique se concentrent sur l'amélioration de la qualité du Service , Une vaste collection d'informations a été établie au pays et à l'étranger. ,Développement du marché,Logistique et distribution, Service Network of Express receiving and Dispatching Equivalent Express Service Organization , Les systèmes opérationnels de base sont nombreux , Les grandes entreprises de logistique ont des commandes quotidiennes moyennes jusqu'à un million de niveaux , Les commandes quotidiennes de pointe peuvent atteindre des dizaines de millions de niveaux
• L'utilisation de la base de données par les systèmes d'affaires de base des entreprises nationales de logistique est énorme , Prenons l'exemple d'un projet Cloud dans le secteur du transport express d'une société de logistique ,Systèmes impliqués100+, Suite d'instances de base de données 300+,Volume des données20TB+
Le client souffre un peu:
• Couplage: Le schéma de base de données client est un ensemble de bases de données partagées par plusieurs entreprises , .Souvent en raison d'une charge de travail élevée , Impact sur la stabilité du rendement de toutes les entreprises
• Fiabilité: Les clients utilisent des composants tiers très disponibles ,Mauvaise stabilité, Temps de commutation minutes , Et facile à perdre des données ,Incapacité de répondre aux besoins opérationnels
• DBAPas assez: Le client est o & M et gestion de base de données , Manque d'expertise et de plate - forme pour une gestion globale efficace de la base de données
Solutions de base de données:
• Effectuer un fractionnement horizontal de la base de données , Réduire l'impact des performances de couplage entre les entreprises ;Utilisation simultanéeRDS proxySéparation lecture - écriture, Améliorer la performance globale de la base de données
• AdoptionRDS DistribuéHASystème, Réduire le temps de commutation de la base de données en secondes , Et les données garanties 0Perdu, En même temps, selon le scénario d'affaires , Fournir une stratégie de commutation flexible qui donne la priorité à la fiabilité et à la disponibilité
• Utiliser une plate - forme de contrôle professionnelle 200+ Instance pour la gestion globale , Grâce à une requête lente , Mécanisme de surveillance des serrures ,Assurer la stabilité du système d'affaires
• Solution de base de données logistique instantanée :Complexité des opérations,Une grande variété de bases de données

Contexte de l'industrie et caractéristiques de l'entreprise :
• Hyperdébit hypersimultané: La collecte de données comporte de nombreuses dimensions , Acquisition de pistes de cyclistes courtes 、 Les données telles que l'état doivent être
Pour signaler en temps réel , .La croissance du volume de données est exponentielle avec la croissance du nombre de coureurs
• Les flux d'affaires ont beaucoup changé : Le nombre d'écritures simultanées de données est étroitement lié au nombre de véhicules en ligne ,
• Types de données divers : Les besoins logistiques immédiats sont complexes , Les types de données produites sont également plus nombreux , Aucun nombre
• La base de données peut répondre à toutes les exigences , Nécessite une coopération multi - bases de données , Comment utiliser la base de données est la clé du succès de l'entreprise
Le client souffre un peu:
• Différents types de données, Besoin de tenir à jour plusieurs systèmes de base de données par soi - même ,Coûts d'entretien élevés
• Le déploiement traditionnel de la base de données présente des risques potentiels pour la sécurité , Risque élevé de fuite ou de falsification des données
• Augmentation rapide des données logistiques en temps réel , Haute concurrence d'écriture , Les coûts d'expansion et les difficultés de mise en oeuvre sont énormes
Logistique, par exemple ,Hypothèses100WCavaliers,Nouvelles données quotidiennes28TB, Inventaire semestriel des données 0.5PB;
• La structure des données de défaillance n'est pas fixe , Grande concurrence d'écriture , Les scénarios d'interrogation des entreprises sont complexes
Solutions de base de données:
• Produits riches: Le Service de base de données Cloud de Huawei comprend: :MySQL、PostgreSQLDDS, Satisfaire les clients à l'utilisation de scénarios d'utilisation de bases de données multiples
• Elastoscopie: La gamme complète de bases de données prend en charge l'expansion élastique du disque ,Business not aware
• Très haute performance(Gauss for MongoDB)
Utiliser le scénario: Données de localisation géographique du Cavalier , Données non structurées telles que les géoclôtures
• FAILOVER: Une gamme complète de services de base de données prend en charge AZHaute disponibilité, Et prend en charge le commutateur haute disponibilité en secondes , La configuration de l'application n'a pas besoin d'être modifiée
2. Huawei Cloud Automobile Industry Database Solution
2.1. Introduction aux produits des services de base de données
Huawei Cloud Database Service Panorama
GaussDB Auto - recherche pour les clients du Gouvernement et des entreprises , Pour satisfaire la bouche haute 、Haute performance; Open source pour les PME ,Excellent rapport qualité - prix

2.2. Meilleures pratiques en matière de bases de données sur l'Internet des véhicules
Scénario de données de base pour l'interconnexion des véhicules
Les données sont l'actif de base des entreprises automobiles , Chaque entreprise automobile a un scénario d'affaires pour l'interconnexion des véhicules


2.3. Meilleures pratiques pour les bases de données mobiles sur les voyages
Mobile Travel Business scenario
Les modèles traditionnels ont un avantage congénital dans le segment des déplacements mobiles

Huawei Cloud fournit une machine virtuelle pour les voitures jianghuai 、 Services de base de données Cloud, etc 160 Une grande variété de services Cloud , La nouvelle génération de plate - forme de Jianghuai Automobile devient de plus en plus puissante , Réduire considérablement les difficultés d'exploitation et d'entretien , Amélioration significative des performances du système

Solutions de base de données mobiles sur les voyages
Point de douleur de l'industrie:
• La conception du schéma est difficile : Les constructeurs automobiles traditionnels sont peu impliqués dans ce domaine ,Manque d'expérience, Impossible d'utiliser la base de données avec une combinaison raisonnable
• La lecture et l'écriture de la base de données sont stressantes: La flexibilité et la distribution sont les principales exigences des clients , Les systèmes traditionnels sont plus difficiles à satisfaire
• Exigences élevées en matière de fiabilité des données : Les voyages mobiles impliquent des données commerciales de base qui exigent une plus grande fiabilité de la base de données
Huawei Cloud Database Solutions:
• Très élastique :GaussDB(for Mongo) Données du message pour le système de stockage , Données du site , La capacité d'expansion élastique au niveau des minutes pour les scénarios d'écriture de données en vrac répond grandement à l'expansion horizontale de l'entreprise
• Données financières très fiables :GaussDB(for MySQL) Stockage des données de paiement 、 Données de commande et autres données nécessitant une grande cohérence , Résoudre les problèmes de cohérence et d'extensibilité élastique des données
边栏推荐
- Virtual file system
- 树莓派4B开发板入门
- Typora收费?搭建VS Code MarkDown写作环境
- Arduino raised $32million to enter the enterprise market
- Kaseya of the United States was attacked by hackers, and 1500 downstream enterprises were damaged. How can small and medium-sized enterprises prevent extortion virus?
- 潞晨科技获邀加入NVIDIA初创加速计划
- JVM调试工具-jvisualvm
- The third session of freshman engineering education seminar is under registration
- Spark parameter tuning practice
- Are internal consultants and external consultants in SAP implementation projects difficult or successful? [English version]
猜你喜欢
.NET7之MiniAPI(特别篇) :Preview5优化了JWT验证(上)

2022蓝队HW初级面试题总结

C language student management system - can check the legitimacy of user input, two-way leading circular linked list

Intelligent Vision Group A4 paper recognition example

Open source and innovation

Maui uses Masa blazor component library

The data synchronization tool dataX has officially supported reading and writing tdengine

JVM調試工具-Arthas

文件系统笔记

Virtual file system
随机推荐
Go operation SQLite code error
The data synchronization tool dataX has officially supported reading and writing tdengine
毕业季进击的技术
在js中正则表达式验证小时分钟,将输入的字符串转换为对应的小时和分钟
With a goal of 50million days' living, pwnk wants to build a "Disneyland" for the next generation of young people
Computing power and intelligence of robot fog
Open source and innovation
Leetcode概率题面试突击系列11~15
[binary tree] - middle order traversal of binary tree
leetcode:85. Max rectangle
内网学习笔记(4)
SAP实施项目上的内部顾问与外部顾问,相互为难还是相互成就?【英文版】
潞晨科技获邀加入NVIDIA初创加速计划
Stop looking! The most complete data analysis strategy of the whole network is here
文件系统笔记
What is JSP technology? Advantages of JSP technology
Le système de surveillance du nuage hertzbeat v1.1.0 a été publié, une commande pour démarrer le voyage de surveillance!
年中了,准备了少量的自动化面试题,欢迎来自测
华为云数据库进阶学习
【问题解决】The connection to the server localhost:8080 was refused