当前位置:网站首页>Huawei cloud database advanced learning
Huawei cloud database advanced learning
2022-06-24 07:12:00 【Chengsiyang】
Preface
This article is divided into 3 There are three chapters to introduce :
The first 1 Chapter How to achieve high availability
The first 2 Chapter performance optimization
The first 3 Chapter Introduction to solutions in various industries
I hope this article can let you understand the pain points of the industry and the technical parameters and functions of the database , Understand the technical parameters of the database , Cloud database operation and maintenance capabilities are helpful , And can give comprehensive solutions according to specific scenarios
1、 Interpretation and setting of database technical parameters
1. What is? RDS MySQL High availability
Real time monitoring through monitoring software HA The status of the primary and standby databases of the cluster , After discovering that the main library is down , Automatic switching between active and standby roles is realized by highly available components , And whether the consistency of data can be guaranteed , Effectively reduce the service unavailable time. A cluster with such capabilities is a highly available cluster , Such as RDS MySQL Of HA colony
2. RDS MySQL High availability level
• Same as AZ: Cross physical HA colony ( Physical machines deployed in different cabinets of independent power supply )
• Span AZ: Cross machine room HA colony
• Span region: Cross regional HA colony
3. RDS MySQL Highly available switching mechanism
• MySQLHA Cluster status is through Monitor Component real-time monitoring ,VIP Bind to the host , Data synchronization between master and slave is performed through master-slave replication
• When the host fails ,Monitor Will automatically initiate 3 Secondary connection to the host
• If 3 Times have failed ,Monitor Initiate active / standby switching , First the VIP Unbundling , Wait for the standby machine to replay
• Finish all relaylog After catching up with the host , The standby aircraft is upgraded to the main one ,VIP Bind to new host ( Original and standby machine )
• After the birth of the new host , If the original host has been restored , Re establish the master-slave relationship
• If the original host is not recoverable , It is necessary to solve the fault of the original host manually , Manually repeat the master-slave relationship





2、 performance optimization
1. Performance pressure test
1. The purpose of pressure measurement is
First of all, we need to understand why we need pressure measurement ?
Before pressure measurement, the purpose of pressure measurement shall be clarified. When the purpose of pressure measurement is different , We need to design different pressure measurement schemes. The common pressure measurement purposes are :
• Test the performance of the new version of the database
• Verify some DB/OS The parameters of the layer
• Test the impact of different storage on database performance
• Test the performance of the database in different scenarios
2. Influencing factors
Factors affecting database performance
Before performance pressure test , Due to a general understanding of the factors affecting database performance, it can be roughly divided into : Database level 、 System level 、 Storage level 、 Network level, etc
Common indicators at all levels are as follows :

3. Focus on indicators
Performance indicators that pressure measurement focuses on
Pay attention to the common performance indicators of the database at any time during the pressure measurement process , To find possible performance bottlenecks
The common performance indicators of database are mainly divided into the following categories :

4. Tool method
How do we choose pressure measuring tools and methods ?
in the light of MySQL for , There are many pressure measuring tools , Such as :sysbeno th、Tpcc-mysql、mysqlslap、tcpcopy Wait in a scenario without specific requirements , Generally, the most widely used in the industry sysbench As a pressure measurement tool, the specific pressure measurement process is as follows :

2. Index optimization
1. Index introduction
Heap
• What is? heap
heap It's just that one doesn't have clusteredindex One of the table One table without clustered index, So this one table The data is stored in heap On , We can also say this table It's a heap
• heap Characteristics
(1) Heap Logically, it is a flat structure , It has no intermediate/root pages
(2) Only through heap You can't do it yourself lookup operation , Only in heap Do on scan operation
(3) Heap Medium page Not between previouspage perhaps nextpage This link
(4) Heap You can create one or more nonclustered index
Clustered index
• What is? clustered index
stay heap I created one on clusteredindex, This table It becomes a clustered index
• Clustered index Characteristics
Clusteredindex Logically, it adopts tree structure
Clustered index Of leaflevel node Keep this table All in column The data of
Nonclustered index
• What is? nonclustered index
Nonclusterd index Is in heap perhaps clusteredindex An independent structure other than , It contains nonclusteredindexkey To the corresponding heap perhaps clusteredindex Data storage location in
• Nonclustered index Characteristics
(1) One table You can create one or more nonclustered index
(2) Nonclustered index Will improve select Performance of operation , But it will reduce... To a certain extent update、delete Performance of
(3) Nonclustered index Not more is better
(4) What kind of index, It depends on the of the application workload What does it look like
2. Index related DMV
• sys.indexes
(1) Every index(clustered perhaps nonclustered) And each heap stay sysindexes There is a row of corresponding data in
(2) Heap Of indexid yes 0
(3) Clustered index Of indexid yes 1
(4) Nonclustered index Of indexid Greater than 1
• sys.dm_db_index_physical_stats
(1) You can query index Of fragmentation Information
(2) You can see index Different level How many page
(3) You can see page What percentage of the space has been used
3. Slow query optimization
1. The impact of slow queries
• Why focus on slow queries ?
(1) The reason why we focus on slow query , This is because slow queries can lead to the following effects :
(2) database cpu High load
(3) IO High load causes the server to get stuck , Slow down database performance Sql The execution plan is inappropriate , Execution takes too long
(4) The increase of database locks , Affecting normal DDL and DML operation
2. View slow query log
• How to view slow query logs ?
(1) see my.cnf file , adopt slow_query_log_file Parameter to locate the location of the slow query log
(2) adopt vim Directly open the slow query log to perform a single slow query sq1 analysis
(3) adopt mysqldumpslow or pt-query-digest The tool summarizes and analyzes the slow query logs, as shown in the following figure
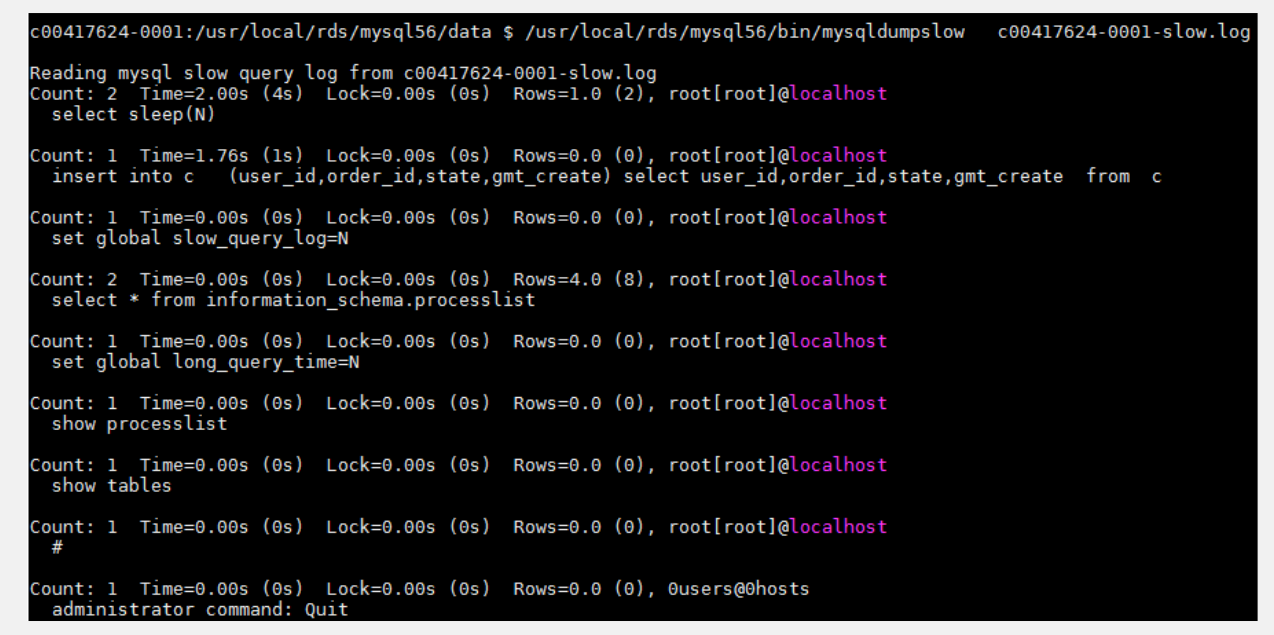
3. Slow query optimization steps
• For a particular slow sql How to optimize ?
For specific slow sql, Mainly through the following steps of analysis :
(1) see SQL Implementation plan :explain sql
(2) View the index of the table :show index from tb_name; View table structure :show create table tb_name;
(3) adopt profiling have a look sql Where is the time spent ?
(4) adopt Optimizer Trace Observe sql Implementation process of , Observe sql Basis for selection of execution plan
3、 Introduction to solutions in various industries
1. Huawei cloud logistics industry database solution
1.1 Huawei cloud database service product introduction
• Panorama of Huawei cloud database service
GaussDB Self research for government and enterprise customers , Meet the requirements of high reliability 、 High performance ; Open source for small and medium-sized enterprises , Best value for money

1.2 Development overview of logistics industry
• logistics 4.0, Intelligent upgrading is the inevitable development trend of logistics industry

• Main scenarios of logistics industry

• Overall architecture of logistics industry solutions

1.3 Logistics industry database best practices
• Intelligent logistics industry database solution

The customer is in pain :
• The transportation range of the route is large , It is difficult to monitor the transportation process , The health of the vehicle is not transparent , The path is not planned
• The loading performance of map service tile data is poor ,MongoDB The speed of loading basemap data in is slow
• A lot of information 、 There is a lot of video data , Fast update speed , Logistics efficiency and accuracy are difficult to guarantee
Huawei cloud database solution :
• Huawei cloud database GaussDB(forMongo) Storage computing separation architecture , No active / standby synchronization is required , The write speed is offline MongoDB(DDS) Of 2-4 times , nothing CPU100% problem
• Use a relational database PostgreSQL, Provide native location-based support
• Use of high-frequency unstructured monitoring status data influxDB or MongoDB(DDS), It is suitable for storing unstructured data with a large amount of writing
• Smaller video files can be used MongoDB(DDS) Non institutional database services for direct storage , Use your own GridFS Module stores files
• Case of express logistics customer database

Usage of domestic logistics customer database :
• Logistics companies focus on improving service quality , It has established a huge information collection system at home and abroad , market development , Logistics distribution , The service network of express delivery service organizations , There are many core business systems , The average daily order volume of large logistics companies can reach millions , The daily order volume can reach tens of millions during the peak period
• The core business system of domestic logistics companies uses a huge amount of database , Take the cloud project of express business of a logistics company as an example , Involving the system 100+, Number of database instances 300+, Data volume 20TB+
The customer is in pain :
• Coupling : Customer database architecture is a database shared by multiple businesses , Often because a certain business load is high , Affect the performance and stability of all businesses
• reliability : Customers use third-party highly available components , Poor stability , The switching time is in minutes , And easy to cause data loss , Unable to meet business requirements
• DBA Insufficient : The customer is operation and maintenance and database management , Lack of professional skills and platform for effective overall management of the database
Database solution :
• Split the database horizontally , Reduce the coupling performance impact between services ; Simultaneous utilization RDS proxy Read and write separation , Improve the performance of the overall database
• adopt RDS Distributed HA System , Reduce the database switching time to seconds , And guarantee data 0 The loss of , At the same time, according to the business scenario , Provide flexible switching strategies with reliability first and availability first
• Use a professional management and control platform to 200+ Instance for global management , Through slow query , Lock monitoring and other mechanisms provide timely early warning of database performance , Ensure the stability of the business system
• Real time Logistics database solution : Business complex , There are many kinds of databases

Industry background and business characteristics :
• High throughput and high concurrency : Data collection has many dimensions , The acquisition cycle is short, and the rider's track 、 Status and other data need to be
Report in real time , The amount of data increases exponentially with the number of riders
• The business flow changes greatly : The amount of concurrent data writing is closely related to the number of vehicles online ,
• Data types are miscellaneous : The demand for real-time logistics is complex , There are many kinds of data generated , There is no number
• The database can meet all needs , Multiple databases are required to cooperate , How to use the database well will be the key to business success or failure
The customer is in pain :
• There are many types of data , You need to maintain a variety of database systems by yourself , Maintenance costs are high
• There are security risks in traditional database deployment , There is a great risk of data leakage or tampering
• The increment of real-time logistics data is fast , High write concurrency , The cost of capacity expansion and the difficulty of implementation are huge, so it is necessary to solve the problem immediately
Take logistics as an example , hypothesis 100W A rider , Daily new data 28TB, Semi annual data stock 0.5PB;
• The fault data structure is not fixed , Write concurrency is large , The business query scenario is complex
Database solution :
• The products are rich : Huawei cloud database service includes :MySQL、PostgreSQLDDS, Meet the use of various database usage scenarios of customers
• Stretch and stretch : The full range of databases support elastic disk expansion , The business has no perception
• Ultra high performance (Gauss for MongoDB)
Use scenarios : Rider geographic location data , Unstructured data such as geofencing
• Fail over : A full range of database services support cross AZ High availability , It also supports high availability switching at the second level , The application configuration does not need to be changed
2. Huawei cloud automotive industry database solution
2.1. Database service product introduction
Panorama of Huawei cloud database service
GaussDB Self research for government and enterprise customers , Meet the high mouth 、 High performance ; Open source for small and medium-sized enterprises , Best value for money

2.2. Internet of vehicles database best practices
Internet of vehicles core data scenario
Data is the core asset of auto enterprises , Every car enterprise has a business scenario of Internet of vehicles


2.3. Mobile travel database best practices
Mobile travel business scenario
Traditional models have inherent advantages in the field of mobile travel segmentation

Huawei cloud provides a cloud host for JAC 、 Cloud database services, etc 160 A variety of rich cloud services , Let the functions of the new generation platform of JAC become stronger and stronger , The difficulty of operation and maintenance has been greatly reduced , The system performance has been greatly improved

Mobile travel database solution
Industry pain point :
• The scheme design is difficult : Traditional car factories have little involvement in this field , Lack of experience , Unable to reasonably combine and use databases
• Database reading and writing pressure is high : Flexibility and distribution are the core demands of customers , Traditional schemes are difficult to meet the requirements
• High data reliability is required : Mobile travel involves core transaction data and requires higher reliability of the database
Huawei cloud database solution :
• Extreme flexibility :GaussDB(for Mongo) Message data of the storage system , Locus data , Meet the writing scenario of large quantities of data, and the minute level elastic expansion ability greatly meets the horizontal expansion of business
• Financial grade data is highly reliable :GaussDB(for MySQL) Store payment data 、 Order data and other data with high consistency requirements , Solve the problem of data consistency and elastic expansion
边栏推荐
- JVM调试工具-jstack
- Implementation and usage analysis of static pod
- 年中了,准备了少量的自动化面试题,欢迎来自测
- Smart space 𞓜 visualization of operation of digital twin cargo spacecraft
- You have a chance, here is a stage
- . Net7 miniapi (special part):preview5 optimizes JWT verification (Part 1)
- Record the problem location experience when an application is suddenly killed
- Internet cafe management system and database
- Clickhouse source code note 6: exploring the sorting of columnar storage systems
- 【问题解决】虚拟机配置静态ip
猜你喜欢

Application of intelligent reservoir management based on 3D GIS system

应用配置管理,基础原理分析

数据同步工具 DataX 已经正式支持读写 TDengine

Interpreting top-level design of AI robot industry development
The data synchronization tool dataX has officially supported reading and writing tdengine
![[binary number learning] - Introduction to trees](/img/7d/c01bb58bc7ec9c88f857d21ed07a2d.png)
[binary number learning] - Introduction to trees

You have a chance, here is a stage
Application configuration management, basic principle analysis

setInterval里面的函数不能有括号

智能视觉组A4纸识别样例
随机推荐
Why use lock [readonly] object? Why not lock (this)?
[cloud based co creation] overview of the IOT of Huawei cloud HCIA IOT v2.5 training series
Database stored procedure begin end
One year since joining Tencent
What is the role of domain name websites? How to query domain name websites
Challenges brought by maker education to teacher development
展锐芯片之GPU频率
How to send SMS in groups? What are the reasons for the poor effect of SMS in groups?
多传感器融合track fusion
Spark accumulators and broadcast variables
如何低成本构建一个APP
【问题解决】虚拟机配置静态ip
How to register the cloud service platform and what are the advantages of cloud server
c#:互斥锁的使用
In the middle of the year, I have prepared a small number of automated interview questions. Welcome to the self-test
Smart space 𞓜 visualization of operation of digital twin cargo spacecraft
Localized operation on cloud, the sea going experience of kilimall, the largest e-commerce platform in East Africa
System design: partition or data partition
mysql中的 ON UPDATE CURRENT_TIMESTAMP
I failed to delete the database and run away