当前位置:网站首页>实时计算框架:Spark集群搭建与入门案例
实时计算框架:Spark集群搭建与入门案例
2022-06-24 00:33:00 【知了一笑】
一、Spark概述
1、Spark简介
Spark是专为大规模数据处理而设计的,基于内存快速通用,可扩展的集群计算引擎,实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流,运算速度相比于MapReduce得到了显著的提高。
2、运行结构

Driver
运行Spark的Applicaion中main()函数,会创建SparkContext,SparkContext负责和Cluster-Manager进行通信,并负责申请资源、任务分配和监控等。
ClusterManager
负责申请和管理在WorkerNode上运行应用所需的资源,可以高效地在一个计算节点到数千个计算节点之间伸缩计算,目前包括Spark原生的ClusterManager、ApacheMesos和HadoopYARN。
Executor
Application运行在WorkerNode上的一个进程,作为工作节点负责运行Task任务,并且负责将数据存在内存或者磁盘上,每个 Application都有各自独立的一批Executor,任务间相互独立。
二、环境部署
1、Scala环境
安装包管理
[[email protected] opt]# tar -zxvf scala-2.12.2.tgz
[[email protected] opt]# mv scala-2.12.2 scala2.12
配置变量
[ro[email protected] opt]# vim /etc/profile
export SCALA_HOME=/opt/scala2.12
export PATH=$PATH:$SCALA_HOME/bin
[[email protected] opt]# source /etc/profile
版本查看
[[email protected] opt]# scala -version
Scala环境需要部署在Spark运行的相关服务节点上。
2、Spark基础环境
安装包管理
[[email protected] opt]# tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz
[[email protected] opt]# mv spark-2.1.1-bin-hadoop2.7 spark2.1
配置变量
[[email protected] opt]# vim /etc/profile
export SPARK_HOME=/opt/spark2.1
export PATH=$PATH:$SPARK_HOME/bin
[[email protected] opt]# source /etc/profile
版本查看
[[email protected] opt]# spark-shell
3、Spark集群配置
服务节点
[[email protected] opt]# cd /opt/spark2.1/conf/
[[email protected] conf]# cp slaves.template slaves
[[email protected] conf]# vim slaves
hop01
hop02
hop03
环境配置
[[email protected] conf]# cp spark-env.sh.template spark-env.sh
[[email protected] conf]# vim spark-env.sh
export JAVA_HOME=/opt/jdk1.8
export SCALA_HOME=/opt/scala2.12
export SPARK_MASTER_IP=hop01
export SPARK_LOCAL_IP=安装节点IP
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/hadoop2.7/etc/hadoop
注意SPARK_LOCAL_IP的配置。
4、Spark启动
依赖Hadoop相关环境,所以要先启动。
启动:/opt/spark2.1/sbin/start-all.sh
停止:/opt/spark2.1/sbin/stop-all.sh
这里在主节点会启动两个进程:Master和Worker,其他节点只启动一个Worker进程。
5、访问Spark集群
默认端口是:8080。
http://hop01:8080/

运行基础案例:
[[email protected] spark2.1]# cd /opt/spark2.1/
[[email protected] spark2.1]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.1.1.jar
运行结果:Pi is roughly 3.1455357276786384
三、开发案例
1、核心依赖
依赖Spark2.1.1版本:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
引入Scala编译插件:
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
2、案例代码开发
读取指定位置的文件,并输出文件内容单词统计结果。
@RestController
public class WordWeb implements Serializable {
@GetMapping("/word/web")
public String getWeb (){
// 1、创建Spark的配置对象
SparkConf sparkConf = new SparkConf().setAppName("LocalCount")
.setMaster("local[*]");
// 2、创建SparkContext对象
JavaSparkContext sc = new JavaSparkContext(sparkConf);
sc.setLogLevel("WARN");
// 3、读取测试文件
JavaRDD lineRdd = sc.textFile("/var/spark/test/word.txt");
// 4、行内容进行切分
JavaRDD wordsRdd = lineRdd.flatMap(new FlatMapFunction() {
@Override
public Iterator call(Object obj) throws Exception {
String value = String.valueOf(obj);
String[] words = value.split(",");
return Arrays.asList(words).iterator();
}
});
// 5、切分的单词进行标注
JavaPairRDD wordAndOneRdd = wordsRdd.mapToPair(new PairFunction() {
@Override
public Tuple2 call(Object obj) throws Exception {
//将单词进行标记:
return new Tuple2(String.valueOf(obj), 1);
}
});
// 6、统计单词出现次数
JavaPairRDD wordAndCountRdd = wordAndOneRdd.reduceByKey(new Function2() {
@Override
public Object call(Object obj1, Object obj2) throws Exception {
return Integer.parseInt(obj1.toString()) + Integer.parseInt(obj2.toString());
}
});
// 7、排序
JavaPairRDD sortedRdd = wordAndCountRdd.sortByKey();
List<Tuple2> finalResult = sortedRdd.collect();
// 8、结果打印
for (Tuple2 tuple2 : finalResult) {
System.out.println(tuple2._1 + " ===> " + tuple2._2);
}
// 9、保存统计结果
sortedRdd.saveAsTextFile("/var/spark/output");
sc.stop();
return "success" ;
}
}
打包执行结果:

查看文件输出:
[[email protected] output]# vim /var/spark/output/part-00000
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent

阅读标签
【Java基础】【设计模式】【结构与算法】【Linux系统】【数据库】
【分布式架构】【微服务】【大数据组件】【SpringBoot进阶】【Spring&Boot基础】
技术系列
边栏推荐
- Throttling and anti shake
- C语言:结构体数组实现找出最低分学生记录
- 【数字信号】基于matlab模拟窗函数频谱细化【含Matlab源码 1906期】
- Summary of common register bit operation modes in MCU
- 2022考研经验分享【初试、择校、复试、调剂、校招与社招】
- Windows10 security mode entry cycle blue screen repair
- 【CVPR 2022】高分辨率小目标检测:Cascaded Sparse Query for Accelerating High-Resolution Smal Object Detection
- Usage of go in SQL Server
- Hackers can gain administrator privileges by invading Microsoft mail server and windows Zero Day vulnerability November 23 global network security hotspot
- ARM学习(7) symbol 符号表以及调试
猜你喜欢

Android 3年外包工面试笔记,有机会还是要去大厂学习提升,作为一个Android程序员

What are the two types of digital factories

小猫爪:PMSM之FOC控制15-MRAS法

Skywalking installation and deployment practice

Social order in the meta universe

钟珊珊:被爆锤后的工程师会起飞|OneFlow U
![[applet] realize the effect of double column commodities](/img/e3/b72955c1ae67ec124520ca46c22773.png)
[applet] realize the effect of double column commodities
【小程序】实现双列商品效果

牛学长周年庆活动:软件大促限时抢,注册码免费送!
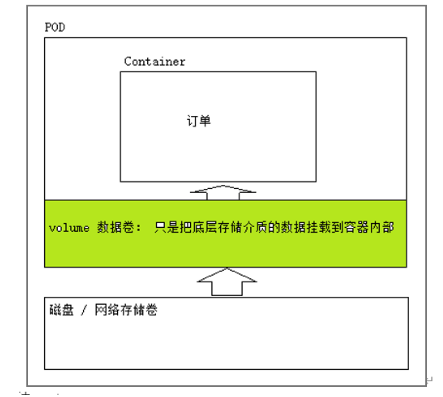
Common core resource objects of kubernetes
随机推荐
Android App Bundle探索,客户端开发面试题目
Salesforce Future method in salesforce – @future
Accompanist组件库中文指南 - Glide篇,劲爆
Version ` zlib 1.2.9 "not found (required by / lib64 / libpng16.so.16)
Usage of go in SQL Server
Google Earth engine (GEE) - verification results used by NDVI, NDWI and NDBI to increase classification accuracy (random forest and cart classification)
kubernetes之常用核心资源对象
Dependency Inversion Principle
解决base64压缩文件,经过post请求解压出来是空格的问题
同行评议论文怎么写
C语言:百马百担问题求驮法
阿里巴巴面试题:多线程相关
[Hongke case] how can 3D data become operable information Object detection and tracking
Learn PWN from CTF wiki - ret2text
NLP工程师是干什么的?工作内容是什么?
Common WebGIS Map Libraries
The first open-source MySQL HTAP database in China will be released soon, and the three highlights will be informed in advance that shiatomics technology will launch heavily
超标量处理器设计 姚永斌 第3章 虚拟存储器 --3.1~3.2 小节摘录
When the IOT network card device is connected to easycvr, how can I view the streaming IP and streaming time?
飞桨产业级开源模型库:加速企业AI任务开发与应用