当前位置:网站首页>Data Lake survey
Data Lake survey
2022-06-25 11:39:00 【Direction_ Wind】
Data Lake Research
1 What is a data Lake
Mention data Lake , You all have questions like this , What is a data Lake ? Why is the data lake so hot in the past two years ? Data lake is not a new concept , The earliest concept of data lake is 80 It has been proposed since the s , At that time, the definition of data lake was the original data layer , It can store all kinds of structured data 、 Semi structured or even unstructured data . Like machine learning 、 Many scenarios, such as real-time analysis, determine the data during query Schema.
Wikipedia : A data lake is a repository or system that stores data in its original format 、 It stores data as is , No need to structure the data in advance . A data lake can store structured data ( Such as tables in relational databases ), Semi-structured data ( Such as CSV、 journal 、XML、JSON), Unstructured data ( E-mail 、 file 、PDF) And binary data ( As in Figure 、 Audio 、 video ).
Amazon :“ The data lake is a centralized repository , Allows you to store all structured and unstructured data at any size . You can store the data as it is ( No need to process structured data ), And run different types of analysis - From control panel and visualization to big data processing 、 Real time analysis and machine learning , To guide better decisions .”
Microsoft's definition is vague : The data Lake contains everything that makes developers 、 Data scientist 、 Analysts can store it more easily 、 The ability to process data , These capabilities allow users to store any size 、 Any type 、 Any speed of data generation , And can cross platform 、 Do all types of analysis and processing across languages .
But whatever the definition is , The data lake is developed around the following two points :
- Storage capacity : Including a lot of data , And various structured and unstructured data storage , Keep the look of the original data , And the storage price is low
- Analytical ability : This includes but is not limited to batch processing 、 Flow computation 、 Interactive analysis and machine learning ; meanwhile , Also need to provide a certain task scheduling and management capabilities .
The ability to support :
- (1) It also supports stream batch processing
- (2) Support data update
- (3) Support transactions (ACID)
- (4) Extensible metadata
- (5) Support for multiple storage engines
- (6) Support multiple computing engines
Different companies choose different data Lake products according to different needs , For example, Alibaba cloud's DLA Team choice hudi As its underlying data Lake storage engine ; Tencent chose iceberg As their data Lake storage engine
It is generally believed that , Solving data islands is a major feature of the data lake , At present, the basic assumption of the data lake is , Centralized storage + Metadata services + Surrounding open and collaborative products (es, Calculation engine , Analysis engine, etc )
2 What problems can data Lake solve
Low storage cost 、 Features of high flexibility , It is very suitable for centralized storage of query scenarios . With the rise of cloud services in recent years , Especially the maturity of object storage , More and more enterprises choose to build storage services on the cloud . The storage and computing separation architecture of data lake is very suitable for the current cloud service architecture , By snapshot isolation , Providing the basis for acid Business , At the same time, it supports docking with a variety of analysis engines to adapt to different query scenarios , It can be said that lake storage has a great advantage in cost and openness .
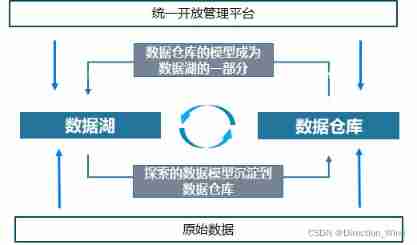
3 The relationship between data lake and data warehouse

4 Data Lake Ecology

As shown in the figure above , For a mature data Lake Ecology :
- First of all, we think it should have the ability of mass storage , The common ones are object storage , Public cloud storage and HDFS;
- On top of that , You also need to support rich data types , Including unstructured images and videos , Semi structured CSV、XML、Log, And structured database tables ;
- besides , Efficient and unified metadata management is needed , So that the computing engine can easily index to various types of data for analysis .
- Last , We need to support rich computing engines , Include Flink、Spark、Hive、Presto etc. , So as to facilitate the docking of some existing application architectures in enterprises .
5 The current common data Lake implementation scheme
The most important problem to be solved in the data lake is the problem of unstructured data storage , There are three popular data Lake formats , But according to the reports of big manufacturers , Now the Internet manufacturers use the most : be based on Hudi And based on Iceberg Two kinds of .
Different data Lake formats , The main problem to be solved is the problem of storage .
5.1 be based on Hudi
Hadoop Upserts and Incrementals:Hudi It's open source Spark Three party Library , It is an open source solution of data lake . It mainly has the following functions ,Hudi From the beginning of the project, it has been evolving towards the platform , It has relatively perfect data governance and table service, For example, users can optimize the layout of files concurrently when writing ,metadata table It can greatly optimize the file search efficiency of the query side when writing .
- Hudi Be able to ingest (Ingest) And management (Manage) be based on HDFS Large analysis data sets on top of , The main purpose is to efficiently reduce the warehousing delay .
- Hudi be based on Spark Come on HDFS Update the data on 、 Insert 、 Delete etc. .
- Hudi stay HDFS The data set is provided with such dirty primitives : Insert update ( How to change data sets ); Incremental pull ( How to get changed data ).
- Hudi It can be done to HDFS Upper parquet Format data for insertion / update operation .
- Hudi By customizing InputFormat And Hadoop The ecological system (Spark、Hive、Parquet) Integrate .
- Change flow :Hudi Provides flow support for getting data changes , You can get from a given point in time that has been in a given table updated / inserted / deleted Incremental flow of all records of , You can query the status data at different times , Personal understanding is , snapshot ;
- Hudi Can and Hive、Spark、Presto This kind of processing engine works together .Hudi Have your own data sheet , By way of Hudi Of Bundle Integration Hive、Spark、Presto In this kind of engine , So that these engines can query Hudi Table data , So as to have Hudi Provided by the Snapshot Query、Incremental Query、Read Optimized Query The ability of .

Baixin bank Hudi Data Lake Architecture :
5.2 be based on Iceberg
Iceberg As one of the emerging data Lake frameworks , A groundbreaking abstraction of “ Table format ”table format" This middle layer , It is independent of the upper computing engine ( Such as Spark and Flink) And the query engine ( Such as Hive and Presto), And the underlying file format ( Such as Parquet,ORC and Avro) Decouple each other . To put it simply :Iceberg Positioned under the computing engine , On top of storage , Organize data and metadata in a specific way , It is a data storage format 
Iceberg The architecture and implementation of is not tied to a particular engine , It implements a common data organization format , This format can be easily used with different engines ( Such as Flink、Hive、Spark) docking .
therefore Iceberg Our architecture is more elegant , For data formats 、 Type system has complete definition and evolvable design .
however Iceberg Line level update missing 、 Delete ability , These two capabilities are the biggest selling points of existing data organizations , The community is still optimizing .
5.2.1 Iceberg Application scenarios :
- Integrate Hive( Can pass Hive Create and delete iceberg surface , adopt HiveSQL Inquire about Iceberg Table data , be based on Spark Make data corrections )
- Streaming data warehousing , introduce iceberg As Flink Sink( Create real-time data warehouse )
- Data Lake ( Huge amounts of data , Quick search , Unified storage )
- Integrate Implala( The user can go through Impala newly build iceberg Inside and outside , And pass Impala Inquire about Iceberg Table data )
Iceberg Same as Hudi The same with ACID , Version snapshot and other capabilities
6 Industry cases
Tencent data Lake :

Alibaba cloud data lake :
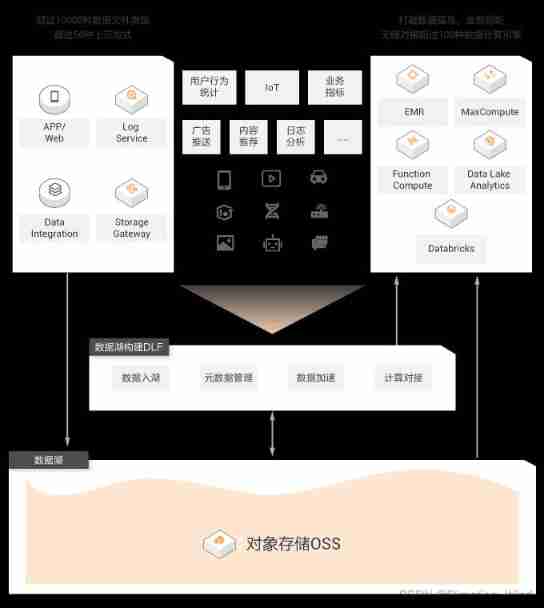

- (1) data storage : use OSS As the centralized storage of data Lake , Can support EB Scale data lake , Customers do not need to consider storage expansion , All types of data can be stored uniformly
- (2) Data Lake Management : face OSS Management and lake entry difficulties caused by data openness ,DLA Of Formation The component has the ability of metadata discovery and one click Lake building ,DLA Provide Meta data catalog The component manages the data assets in the data Lake in a unified way , Whether the data is in “ In the lake ” Still “ Outside the lake ”, For example, use the metadata crawling function , You can create... With one click OSS Metadata information on , Easy automatic recognition CSV/JSON/Parquet Equiform , Create the database table information , Convenient for subsequent calculation engines
- (3) Data analysis and calculation :DLA Provides SQL Computing engines and Spark There are two kinds of computing engines . Whether it's SQL still Spark engine , And all Meta data catalog Deep integration , It can easily obtain metadata information . be based on Spark The ability of ,DLA The solution supports batch processing 、 Computing models such as flow computing and machine learning
- (4) In data integration and development : Alibaba cloud's data Lake solution provides two options : One is to adopt dataworks complete ; The other is to adopt DMS To complete . Whatever you choose , Can provide visual process arrangement 、 Task scheduling 、 Task management capability . In data Lifecycle Management ,dataworks The ability of data mapping is relatively more mature .
Aws:

AWS Data Lake [8] be based on AWS Lake Formation structure ,AWS Lake Formation It's essentially a management component , It and others AWS The service is coordinated with each other , To complete the whole enterprise level data Lake construction function . The picture above is from left to right , It reflects the data precipitation 、 Data flow in 、 Data calculation 、 Data service and other steps .
- (1) Data precipitation : use Amazon S3 As the centralized storage of the whole data Lake , Contains structured and unstructured data , On demand expansion / Pay per use
- (2) Data flow in : Metadata capture 、ETL And data preparation AWS Abstract it separately , Formed a product called AWS GLUE,GLUE The basic calculation form is the combination of various batch processing modes ETL Mission , The departure mode of the task is divided into manual trigger 、 Timing trigger 、 Events trigger three types of events
- (3) Data processing : utilize AWS GLUE Outside the batch calculation mode , You can also use Amazon EMR Carry out advanced data processing and Analysis , Or based on Amazon EMR、Amazon Kinesis To complete the stream processing task
- (4) Data analysis : Data is passed through Athena/Redshift To provide services based on SQL Interactive batch processing capabilities , adopt Amazon Machine Learning、Amazon Lex、Amazon Rekognition Carry out deep processing
7 other
At present, some and some manufacturers are integrating Lake warehouse , It may also be a development trend
The concept of Lake Warehouse Integration proposed by Alibaba cloud is :
- (1) Lake and warehouse data / Seamless metadata , Complement each other , The model of data warehouse feeds back to the data lake ( Become part of the original data ), The structured application knowledge of the lake precipitates into the data warehouse
- (2) Lake and warehouse have a unified development experience , Data stored in different systems , Through a unified development / Management platform operation
- (3) Data lake and data warehouse , The system can decide which data to put in the data warehouse according to the automatic rules , What remains in the data Lake , And then form integration
边栏推荐
- Use of comparable (for arrays.sort)
- 牛客网:主持人调度
- Démarrer avec Apache shenyu
- Detailed explanation of spark specification
- 基于Minifilter框架的双缓冲透明加解密驱动 课程论文+项目源码
- JVM 原理简介
- What are the ways to simulate and burn programs? (including common tools and usage)
- Gaussdb others scenarios with high memory
- A difficult mathematical problem baffles two mathematicians
- Database Series: MySQL index optimization summary (comprehensive version)
猜你喜欢
基于超算平台气象预警并行计算架构研究

牛客网:主持人调度

CFCA安心签接入

Hangzhou / Beijing neitui Ali Dharma academy recruits academic interns in visual generation (talent plan)
Dragon Book tiger Book whale Book gnawing? Try the monkey book with Douban score of 9.5

按钮多次点击造成结果

Geographic location system based on openstreetmap+postgis paper documents + reference papers + project source code and database files

Apache ShenYu 入門
Démarrer avec Apache shenyu

TCP如何處理三次握手和四次揮手期間的异常
随机推荐
Dragon Book tiger Book whale Book gnawing? Try the monkey book with Douban score of 9.5
GaussDB 集群维护案例集-sql执行慢
推荐一款M1电脑可用的虚拟机软件
Countdownlatch source code analysis
西山科技冲刺科创板:拟募资6.6亿 郭毅军夫妇有60%表决权
Yisheng biological sprint scientific innovation board: 25% of the revenue comes from the sales of new crown products, and it is planned to raise 1.1 billion yuan
元素定位不到的 9 种情况
牛客网:分糖果问题
10.1. Oracle constraint deferred, not deferred, initially deferred and initially deferred
Vulnérabilité à l'injection SQL (contournement)
芯片的发展史和具体用途以及结构是什么样的
Customize to prevent repeated submission of annotations (using redis)
Explain websocket protocol in detail
过拟合原因及解决
Getting started with Apache Shenyu
基于C语言的图书信息管理系统 课程论文+代码及可执行exe文件
Multiple clicks of the button result in results
Semaphore source code analysis
[maintain cluster case set] gaussdb query user space usage
Handler、Message、Looper、MessageQueue