当前位置:网站首页>Mujoco+spinningup for intensive learning training quick start
Mujoco+spinningup for intensive learning training quick start
2022-07-25 13:20:00 【Hurry up and don't let it rot】
List of articles
1、 build env
The goal is : Use reinforcement learning to do force control , Make the robot (UR5) Move smoothly to the designated position , And keep this state .
env Several elements of *:
The necessary methods :step(action)、reset()、render()
Necessary elements :action_space、observation_space
The environment we are writing is the process of realizing these basic elements
(1) initialization MuJoCo Related components
self.model = mp.load_model_from_path('ur5.xml') # Load model from path .
self.sim = mp.MjSim(self.model) # MjSim Represents a running simulation , Including its status .
self.viewer = mp.MjViewer(self.sim) # Monitor
(2) Set the action and state space
self.action_high = np.array([2, 2, 2, 1, 1, 1], dtype=np.float32)
self.action_space = spaces.Box(-self.action_high, self.action_high, dtype=np.float32)
self.observation_high = np.array([np.finfo(np.float32).max] * 12)
self.observation_space = spaces.Box(-self.observation_high, self.observation_high, dtype=np.float32)
action_space It is directly determined by the range of the controller , We hope to do a force control , That is to input the action directly to the controller .
action_high Three -2 To 2, Three -1 To 1, symmetrical
Six joints are observed , common 12 Quantity , That is to observe the position and speed information of each joint
(3) step Realization
about step The implementation of the , Direct will action Output to the interface of force control
self.sim.data.ctrl[i] = action[i]
reward Set as the sum of joint position deviation . The bigger the deviation ,reward The smaller the value of , On the contrary, the bigger
r -= abs(self.sim.data.qpos[i] - self.target[i])
state Set as the vector composed of the position and speed of each joint
self.state[i] = self.sim.data.qpos[i]
self.state[i + 6] = self.sim.data.qvel[i]
(4) render
self.viewer.render()
(5) reset
The joint position speed returns to zero
self.sim.data.qpos[i] = 0
self.sim.data.qvel[i] = 0
self.state = [0] * 12
(6) Complete environment code
# UR5_Controller.py
import mujoco_py as mp
import numpy as np
from gym import spaces
class UR5_Controller(object):
def __init__(self, target): # Pass in the target location
self.model = mp.load_model_from_path('ur5.xml') # Load model from path .
self.sim = mp.MjSim(self.model) # MjSim Represents a running simulation , Including its status .
self.viewer = mp.MjViewer(self.sim) # Monitor
self.state = [0] * 12
self.action_high = np.array([2, 2, 2, 1, 1, 1], dtype=np.float32)
self.action_space = spaces.Box(-self.action_high, self.action_high, dtype=np.float32)
self.observation_high = np.array([np.finfo(np.float32).max] * 12)
self.observation_space = spaces.Box(-self.observation_high, self.observation_high, dtype=np.float32)
self.target = target
def step(self, action):
for i in range(6):
self.sim.data.ctrl[i] = action[i] # Direct will action Output to the controller interface
self.sim.step() # step Call to
r = 0
for i in range(6):
r -= abs(self.sim.data.qpos[i] - self.target[i]) # 6 The deviations of joints are accumulated
# r -= abs(self.sim.data.qvel[i])
self.state[i] = self.sim.data.qpos[i] # state Update to each speed and position
self.state[i + 6] = self.sim.data.qvel[i]
done = False
# if r < -50:
# done = True
# print(r)
return np.array(self.state, dtype=np.float32), r, done, {
} # Return to status (observaton Something observed ),reward, A mark of whether the process is completed , Return to one info( Include some information , Generally, it is in the form of self inspection . For example, whether you want to return to a high-speed state , You can write some specific information in it , Self defined , Generally, it can be used on the output ))
def render(self):
self.viewer.render()
def reset(self): # Render the view from the camera , And take the image as numpy.ndarray return .
self.sim.reset()
for i in range(6):
self.sim.data.qpos[i] = 0
self.sim.data.qvel[i] = 0
self.state = [0] * 12
return np.array(self.state, dtype=np.float32) # return reset After the state of the
def close(self):
pass
2、spinning up The framework is introduced
This is a reinforcement learning framework with excellent performance , Its experimental details are better than baseline Much better .spinningup The training efficiency is also better than baseline Much better .
Support mpi Multithreading
Ubuntu: sudo apt-get update && sudp apt-get install libopenmpi-dev
Mac OSX: brew install openmpi
Be careful : It is not recommended here conda, Something could go wrong
install spinningup
git clone https://github.com/openai/spinningup.git
cd spinningup
pip install -e .
Install the test
python -m spinup.run ppo --hid "[32,32]"--env LunarLander-v2 --exp_name installtest --gamma 0.999
python -m spinup.run test_policy data/installtest/installtest_s0
python -m spinup.run plot data/installtest/installtest_so
3、 Training + function
Use spinningup The running program written by reinforcement learning algorithm library
# main.py
from spinup import ppo_pytorch as ppo
from UR5_Controller import UR5_Controller
from spinup.utils.test_policy import load_policy_and_env, run_policy
import torch
TRAIN = 0 # 0: Run existing information 1: Training mode
target = [0, -1.57, 1.57, 0, 0, 0] # Target location
env = lambda : UR5_Controller(target) # Create an environment
if TRAIN:
ac_kwargs = dict(hidden_sizes=[64,64], activation=torch.nn.ReLU) # Network parameters : Hidden layer , Activation function
logger_kwargs = dict(output_dir='log', exp_name='ur5_goToTarget')# Functions that record and output information
ppo(env, ac_kwargs=ac_kwargs, logger_kwargs=logger_kwargs,
steps_per_epoch=5000, epochs=4000)
else:
_, get_action = load_policy_and_env('log') # Read log Information in
env_test = UR5_Controller(target)
run_policy(env_test, get_action)
边栏推荐
- 好友让我看这段代码
- 0710RHCSA
- Shell common script: get the IP address of the network card
- Online Learning and Pricing with Reusable Resources: Linear Bandits with Sub-Exponential Rewards: Li
- 面试官问我:Mysql的存储引擎你了解多少?
- 0716RHCSA
- Discussion on principle and application technology of MLIR
- 0717RHCSA
- Design and principle of thread pool
- QingChuang technology joined dragon lizard community to build a new ecosystem of intelligent operation and maintenance platform
猜你喜欢

0716RHCSA
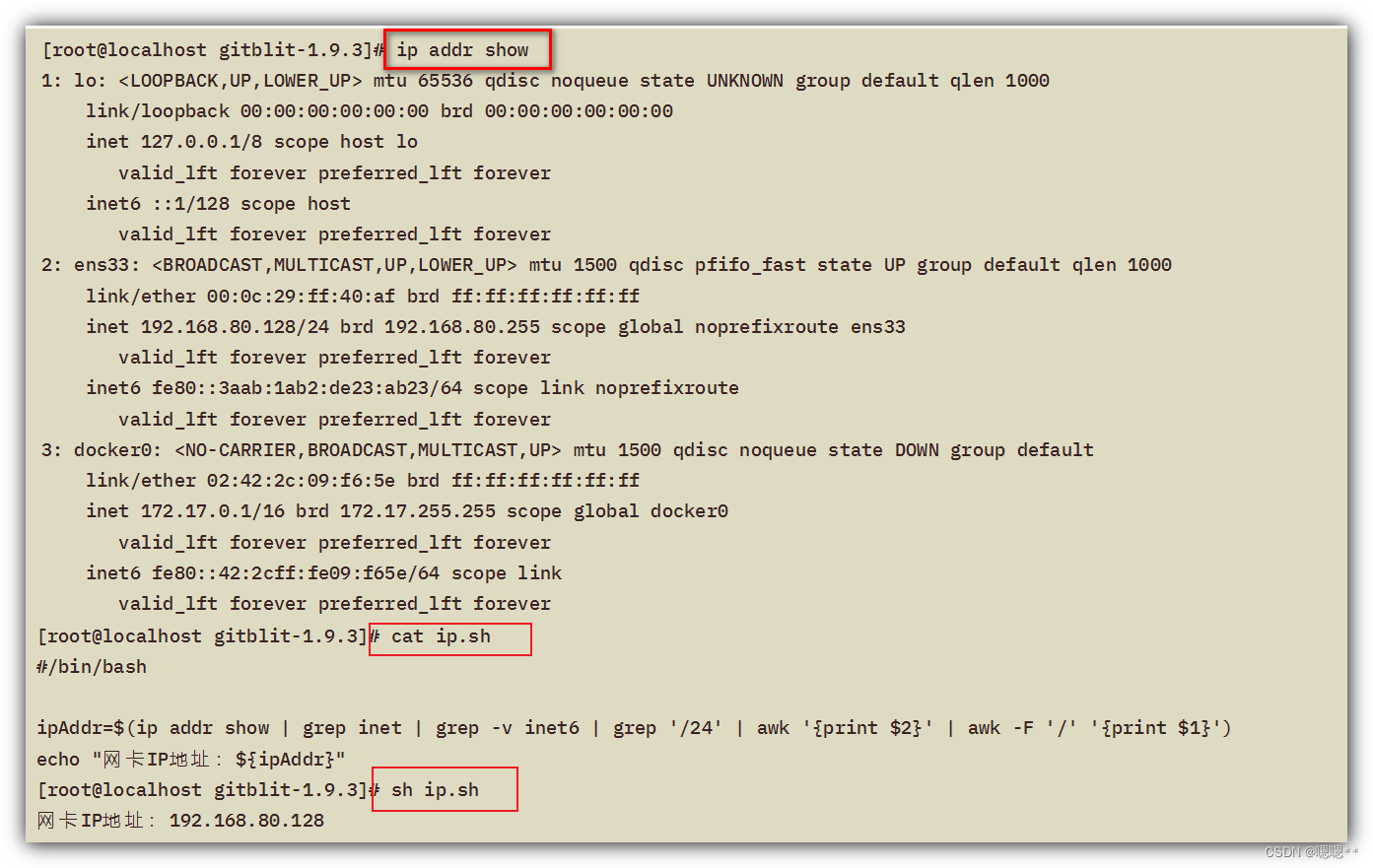
Shell常用脚本:获取网卡IP地址

Introduction to web security UDP testing and defense

Introduction to jupyter notebook

VIM tip: always show line numbers

The migration of arm architecture to alsa lib and alsa utils is smooth

Cyberspace Security penetration attack and defense 9 (PKI)

【重温SSM框架系列】15 - SSM系列博文总结【SSM杀青篇】

The programmer's father made his own AI breast feeding detector to predict that the baby is hungry and not let the crying affect his wife's sleep

Generate SQL script file by initializing the latest warehousing time of vehicle attributes
随机推荐
二叉树基本知识
0719RHCSA
[figure attack and Defense] backdoor attacks to graph neural networks (sacmat '21)
Online Learning and Pricing with Reusable Resources: Linear Bandits with Sub-Exponential Rewards: Li
VIM tip: always show line numbers
0715RHCSA
Friends let me see this code
面试官问我:Mysql的存储引擎你了解多少?
Shell common script: judge whether the file of the remote host exists
mysql函数汇总之日期和时间函数
【GCN-RS】Region or Global? A Principle for Negative Sampling in Graph-based Recommendation (TKDE‘22)
The programmer's father made his own AI breast feeding detector to predict that the baby is hungry and not let the crying affect his wife's sleep
Discussion on principle and application technology of MLIR
Brpc source code analysis (III) -- the mechanism of requesting other servers and writing data to sockets
手写jdbc的使用步骤?
Design and principle of thread pool
基于百问网IMX6ULL_PRO开发板驱动AP3216实验
简单了解流
C#基础学习(二十三)_窗体与事件
Programmer growth chapter 27: how to evaluate requirements priorities?