当前位置:网站首页>Model selection and optimization
Model selection and optimization
2022-06-23 20:39:00 【Mr. Dongye】
Cross validation ( All data sharing n Equal division )
The most commonly used is 10 Crossover verification
give an example :
4 Crossover verification ( Divide into 4 Equal time division ):
Finally, it is found that 4 Mean of accuracy
The grid search : Adjustable parameters
Preset several super parameter combinations for the model , Each group of super parameters was evaluated by cross validation , Select the optimal parameter combination to establish the model
API
from sklearn.model_selection import GridSearchCV
# coding=utf8
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 500)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_csv(
r'E:\Python machine learning \csv\datingTestSet.txt',
sep='\t',
header=None,
names=['flight', 'icecream', 'game', 'type']
)
df_value = df[['flight', 'icecream', 'game']].values
df_value = np.array(df_value)
# test_size=0.25 Means to choose 25% To verify the data
x_train, x_test, y_train, y_test = train_test_split(df_value, df['type'], test_size=0.25) # The cutting data
# Preprocessing : Data standardization ( The normal distribution is satisfied, i.e. the standard deviation is 1, The average value is 0 Array of )
# The processing formula is X=(x-x̅)/α
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# coding=utf8
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 500)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_csv(
r'E:\Python machine learning \csv\datingTestSet.txt',
sep='\t',
header=None,
names=['flight', 'icecream', 'game', 'type']
)
df_value = df[['flight', 'icecream', 'game']].values
df_value = np.array(df_value)
# test_size=0.25 Means to choose 25% To verify the data
x_train, x_test, y_train, y_test = train_test_split(df_value, df['type'], test_size=0.25) # The cutting data
# Preprocessing : Data standardization ( The normal distribution is satisfied, i.e. the standard deviation is 1, The average value is 0 Array of )
# The processing formula is X=(x-x̅)/α
scaler = StandardScaler()
x_train
example
# coding=utf8
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 500)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_csv(
r'E:\Python machine learning \csv\datingTestSet.txt',
sep='\t',
header=None,
names=['flight', 'icecream', 'game', 'type']
)
df_value = df[['flight', 'icecream', 'game']].values
df_value = np.array(df_value)
# test_size=0.25 Means to choose 25% To verify the data
x_train, x_test, y_train, y_test = train_test_split(df_value, df['type'], test_size=0.25) # The cutting data
# Preprocessing : Data standardization ( The normal distribution is satisfied, i.e. the standard deviation is 1, The average value is 0 Array of )
# The processing formula is X=(x-x̅)/α
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# coding=utf8
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 500)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_csv(
r'E:\Python machine learning \csv\datingTestSet.txt',
sep='\t',
header=None,
names=['flight', 'icecream', 'game', 'type']
)
df_value = df[['flight', 'icecream', 'game']].values
df_value = np.array(df_value)
# test_size=0.25 Means to choose 25% To verify the data
x_train, x_test, y_train, y_test = train_test_split(df_value, df['type'], test_size=0.25) # The cutting data
# Preprocessing : Data standardization ( The normal distribution is satisfied, i.e. the standard deviation is 1, The average value is 0 Array of )
# The processing formula is X=(x-x̅)/α
scaler = StandardScaler()
x_train
The grid search
# Use K Nearest neighbor algorithm
knn = KNeighborsClassifier()
# Construct the values of some parameters to search
param = {'n_neighbors':[3,5,10]}
# choose 2 Crossover verification
cv = 2
# Do a grid search
gc = GridSearchCV(knn, param_grid=param,cv=cv)
gc.fit(x_train,y_train)
gc_s = gc.score(x_test,y_test)
print(gc.best_score_) # Show the best results in cross validation
print(gc.best_estimator_) # Show the best model parameters
print(gc.cv_results_) # Display the results of each cross validation for each super parameter 边栏推荐
- [golang] how to clear slices gracefully
- [golang] follow the object pool sync Pool
- Emmet语法规范
- How to make a material identification sheet
- How to process the text of a picture into a table? Can the text in the picture be transferred to the document?
- The evolution of the "Rainbow Bridge" middleware platform for the acquisition database based on shardingsphere
- 【Golang】快速复习指南QuickReview(十)——goroutine池
- WinDbg loads mex DLL analysis DMP file
- Fortress deployment server setup operation guide for novices
- How do I open an account? Is it safe to open an account in Guohai Securities? What do you need to bring?
猜你喜欢

Kubernetes resource topology aware scheduling optimization

20 provinces and cities announce the road map of the meta universe

Interpreting the 2022 agile coaching industry status report

Implementation of microblog system based on SSM

Check four WiFi encryption standards: WEP, WPA, WPA2 and WPA3

Yaokui tower in Fengjie, Chongqing, after its completion, will be the safety tower for Sichuan river shipping with five local scholars in the company

Crise de 35 ans? Le volume intérieur est devenu synonyme de programmeur...

The evolution of the "Rainbow Bridge" middleware platform for the acquisition database based on shardingsphere
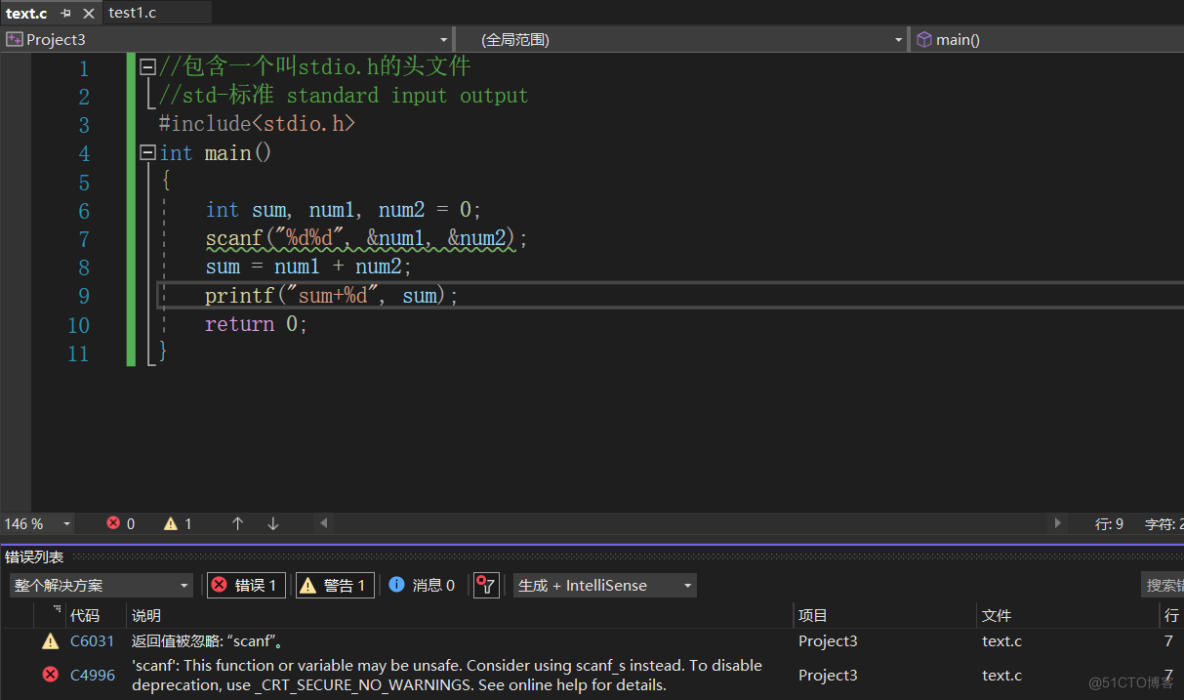
vs2022scanf函数的使用,使用scanf的报错-返回值被忽略:解决·方法

Technology sharing | wvp+zlmediakit realizes streaming playback of camera gb28181
随机推荐
How to dispose of the words on the picture? How do I add text to a picture?
What is the role of short video AI intelligent audit? Why do I need intelligent auditing?
Process injection
How to make a commodity price tag
Does the fortress machine need a server? Understand the architectural relationship between fortress machine and server
[golang] quick review guide quickreview (VII) -- Interface
[SAP ABAP] call API interface instance
[golang] how to realize real-time hot update of Go program
测试的重要性及目的
【Golang】快速复习指南QuickReview(一)——字符串string
[golang] use go language to operate etcd - configuration center
教你如何用网页开发APP
Open source SPL redefines OLAP server
The golden nine silver ten, depends on this detail, the offer obtains the soft hand!
Implementation of flashback query for PostgreSQL database compatible with Oracle Database
教你如何用网页开发桌面应用
国元期货交易软件正规吗?如何安全下载?
「开源摘星计划」Containerd拉取Harbor中的私有镜像,云原生进阶必备技能
WinDbg loads mex DLL analysis DMP file
Leaders of Hangcheng street, Bao'an District and their delegation visited lianchengfa for investigation