当前位置:网站首页>【CVPR 2019】Semantic Image Synthesis with Spatially-Adaptive Normalization(SPADE)
【CVPR 2019】Semantic Image Synthesis with Spatially-Adaptive Normalization(SPADE)
2022-06-26 09:24:00 【_ Summer tree】
List of articles

# Spatial adaptive regularization
We propose spatially-adaptive normalization, a simplebut effective layer for synthesizing photorealistic images given an input semantic layout. we propose usingthe input layout for modulating the activations in normal-ization layers through a spatially-adaptive, learned trans-formation.
Experiments on several challenging datasetsdemonstrate the advantage of the proposed method over ex-isting approaches, regarding both visual fidelity and align-ment with input layouts. Finally, our model allows usercontrol over both semantic and style.
Introduction
In this paper, we show that the conventional net-work architecture [22, 48], which is built by stacking con-volutional, normalization, and nonlinearity layers, is at best suboptimal because their normalization layers tend to “washaway” information contained in the input semantic masks. // In this paper , We proved the traditional network architecture [22,48], It's made up of convolution layers 、 The normalized layer and the nonlinear layer are superimposed , In the best case, it is suboptimal , Because their normalized layers tend to “ Eliminate ” Information contained in the input semantic mask .
To address the issue, we proposespatially-adaptive normal-ization, a conditional normalization layer that modulates theactivations using input semantic layouts through a spatially-adaptive, learned transformation and can effectively propa-gate the semantic information throughout the network. // To solve this problem , We propose a spatial adaptive standardization , It is a conditional normalization layer , The activation of input semantic layout is adjusted through spatial adaptive learning transformation , And it can effectively spread semantic information throughout the network .
This passage is like abstract.

Figure 1: Our model allows user control over both semantic and style as synthesizing an image. The semantic (e.g., theexistence of a tree) is controlled via a label map (the top row), while the style is controlled via the reference style image (theleftmost column). Please visit our website for interactive image synthesis demos. // chart 1: Our model allows users to control the semantics and style of synthetic images . semantics ( for example , The existence of trees ) Is mapped by tags ( The top row ) Controlled , And the style is by referring to the style image ( The leftmost column ) Controlled . Please visit our website for interactive image synthesis demonstration .
our goal is to design a generator forstyle and semantics disentanglement. We focus on provid-ing the semantic information in the context of modulatingnormalized activations. We use semantic maps in differentscales, which enables coarse-to-fine generation. The readeris encouraged to review their work for more details. // Our goal is to design a generator for style and semantic decomposition . We focus on providing semantic information in the context of regulating canonical activation . We use semantic mapping at different scales , This makes coarse to fine generation possible . Readers are encouraged to review their work for more details .
3. Semantic Image Synthesis
Our goal is to learn a mapping function , It can split an input mask Convert to realistic images
Spatially-adaptive denormalization.
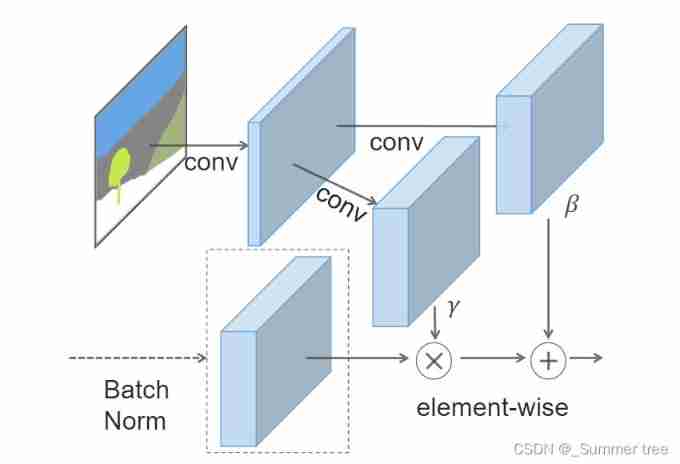
Figure 2: In the SPADE, the mask is first projected onto anembedding space and then convolved to produce the modu-lation parametersγandβ. Unlike prior conditional normal-ization methods,γandβare not vectors, but tensors withspatial dimensions. The producedγandβare multipliedand added to the normalized activation element-wise // chart 2: stay SPADE in , The mask is first projected into the embedding space , Then convolution generates modulation parameters γ and β. Different from the prior conditional normalization method ,γ and β It's not a vector , It's a tensor with a spatial dimension . The generated γ and β Multiply and add to the normalized active elements .
The activation value at site(n∈N,c∈Ci,y∈Hi,x∈Wi)is

\gamma and \beta are thelearned modulation parameters of the normalization layer/
In contrast to the BatchNorm [21], they depend on the in-put segmentation mask and vary with respect to the location(y,x).


Figure 3: Comparing results given uniform segmentationmaps: while the SPADE generator produces plausible tex-tures, the pix2pixHD generator [48] produces two identicaloutputs due to the loss of the semantic information after thenormalization layer.
SPADE generator.
Figure 4: In the SPADE generator, each normalization layer uses the segmentation mask to modulate the layer activations.(left)Structure of one residual block with the SPADE.(right)The generator contains a series of the SPADE residual blockswith upsampling layers. Our architecture achieves better performance with a smaller number of parameters by removing thedownsampling layers of leading image-to-image translation networks such as the pix2pixHD model [48].
conclusion
We propose spatial adaptive normalization , Layout with input semantics , Affine transformation is performed in the normalization layer . The proposed normalization leads to the first semantic image synthesis model , The model can be generated including indoor 、 Outside 、 Realistic output of various scenes including landscape and street scenes . We further demonstrate its application in multimodal synthesis and guided image synthesis .
边栏推荐
- MATLAB basic operation command
- Introduction to common classes on the runtime side
- 如何编译构建
- Course paper: Copula modeling code of portfolio risk VaR
- Edge computing is the sinking and extension of cloud computing capabilities to the edge and user sides
- Phpcms V9 remove the phpsso module
- Unity webgl publishing cannot run problem
- Cookie session and token
- How to solve the problem that NVIDIA model cannot be viewed by inputting NVIDIA SMI and quickly view NVIDIA model information of computer graphics card
- Classified catalogue of high quality sci-tech periodicals in the field of computing
猜你喜欢

Phpcms V9 mall module (fix the Alipay interface Bug)
How to view the data mini map quickly and conveniently after importing data in origin

Merrill Lynch data tempoai is new!

Spark based distributed parallel processing optimization strategy - Merrill Lynch data

Super data processing operator helps you finish data processing quickly

"One week's data collection" -- combinational logic circuit

Edge computing is the sinking and extension of cloud computing capabilities to the edge and user sides

《一周搞定数电》——编码器和译码器
What is optimistic lock and what is pessimistic lock

"One week to finish the model electricity" - 55 timer
随机推荐
《單片機原理及應用》——概述
Param in the paper
Modify coco evaluation index maxdets=[10,15,20]
【开源】使用PhenoCV-WeedCam进行更智能、更精确的杂草管理
How to solve the sample imbalance problem in machine learning?
Pycharm [debug] process stuck
Runtimeerror: object has no attribute NMS error record when using detectron2
首期Techo Day腾讯技术开放日,628等你
PD fast magnetization mobile power supply scheme
Phpcms applet plug-in version 4.0 was officially launched
thinkphp5手动报错
Construction practice of bank intelligent analysis and decision-making platform
【C】青蛙跳台阶和汉诺塔问题(递归)
Is it safe to dig up money and make new debts
Course paper: Copula modeling code of portfolio risk VaR
《一周搞定数电》——组合逻辑电路
运行时端常用类的介绍
"One week's work on Analog Electronics" - power amplifier
板端电源硬件调试BUG
Fix the problem that the rich text component of the applet does not support the properties of video cover, autoplay, controls, etc