当前位置:网站首页>从 join on 和 where 执行顺序认识T-sql查询执行顺序
从 join on 和 where 执行顺序认识T-sql查询执行顺序
2022-07-25 15:10:00 【南风知我意丿】
示例代码
CREATE TABLE "SCOTT"."A" (
"PERSON_ID" NUMBER(5) NULL ,
"PERSON_NAME" VARCHAR2(255 BYTE) NULL
);
-- ----------------------------
-- Records of A
-- ----------------------------
INSERT INTO "SCOTT"."A" VALUES ('1', '张三');
INSERT INTO "SCOTT"."A" VALUES ('2', '李四');
INSERT INTO "SCOTT"."A" VALUES ('3', '王五');
INSERT INTO "SCOTT"."A" VALUES ('4', '赵六');
INSERT INTO "SCOTT"."A" VALUES ('5', '周七');
CREATE TABLE "SCOTT"."B" (
"PERSON_ID" NUMBER(5) NULL ,
"LOVE_FRUIT" VARCHAR2(255 BYTE) NULL
);
-- ----------------------------
-- Records of B
-- ----------------------------
INSERT INTO "SCOTT"."B" VALUES ('1', '香蕉');
INSERT INTO "SCOTT"."B" VALUES ('2', '苹果');
INSERT INTO "SCOTT"."B" VALUES ('3', '橘子');
INSERT INTO "SCOTT"."B" VALUES ('4', '梨');
INSERT INTO "SCOTT"."B" VALUES ('8', '桃');
1.join on
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID AND A.PERSON_ID=1;

2.where
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID WHERE A.PERSON_ID=1;

为什么结果不同呢? 可以从查询逻辑处理的过程解释
SQL执行顺序
(1)FROM <left_table> <join_type> JOIN <right_table> ON <on_predicate>
(2)WHERE <where_predicate>
(3)GROUP BY <group_by_specification>
(4)HAVING <having_predicate>
(5)SELECT DISTINCT TOP(<top_specification>) <select_list>
(6)ORDER BY <order_by_list>
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- WITH CUBE or WITH ROLLUP
- HAVING
- SELECT
- DISTINCT ORDER BY TOP
·
这些步骤执行时,每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回给调用者。如果没有在查询中指定某一子句,将跳过相应的步骤
SELECT 各个阶段都干了什么?
(1)FROM 阶段
FROM阶段标识出查询的来源表,并处理表运算符。在涉及到联接运算的查询中(各种join),主要有以下几个步骤:
a.求笛卡尔积。不论是什么类型的联接运算,首先都是执行交叉连接(cross join),求笛卡儿积,生成虚拟表VT1-J1。
b.ON筛选器。这个阶段对上个步骤生成的VT1-J1进行筛选,根据ON子句中出现的谓词进行筛选,让谓词取值为true的行通过了考验,插入到VT1-J2。
c.添加外部行。如果指定了outer join,还需要将VT1-J2中没有找到匹配的行,作为外部行添加到VT1-J2中,生成VT1-J3。
经过以上步骤,FROM阶段就完成了。概括地讲,FROM阶段就是进行预处理的,根据提供的运算符对语句中提到的各个表进行处理(除了join,还有apply,pivot,unpivot)
(2)WHERE阶段
WHERE阶段是根据<where_predicate>中条件对VT1中的行进行筛选,让条件成立的行才会插入到VT2中。
(3)GROUP BY阶段
GROUP阶段按照指定的列名列表,将VT2中的行进行分组,生成VT3。最后每个分组只有一行。
(4)HAVING阶段
该阶段根据HAVING子句中出现的谓词对VT3的分组进行筛选,并将符合条件的组插入到VT4中。
(5)SELECT阶段
这个阶段是投影的过程,处理SELECT子句提到的元素,产生VT5。这个步骤一般按下列顺序进行
a.计算SELECT列表中的表达式,生成VT5-1。
b.若有DISTINCT,则删除VT5-1中的重复行,生成VT5-2
c.若有TOP,则根据ORDER BY子句定义的逻辑顺序,从VT5-2中选择签名指定数量或者百分比的行,生成VT5-3
(6)ORDER BY阶段
根据ORDER BY子句中指定的列明列表,对VT5-3中的行,进行排序,生成游标VC6.
例子解释
1.join on 执行过程
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID AND A.PERSON_ID=1;
求笛卡尔积,产生5*5=25条记录
ON筛选器(A.PERSON_ID=B.PERSON_ID AND A.PERSON_ID=1)
添加外部行
2.where执行过程
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID WHERE A.PERSON_ID=1;
求笛卡尔积,产生5*5=25条记录ON筛选器 (A.PERSON_ID=B.PERSON_ID )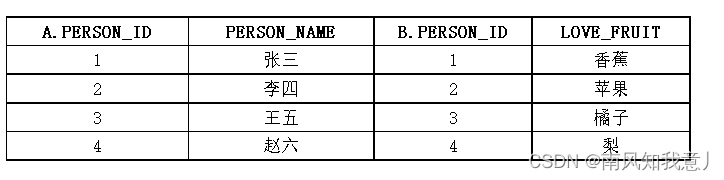
添加外部行
WHERE阶段 (A.PERSON_ID=1)
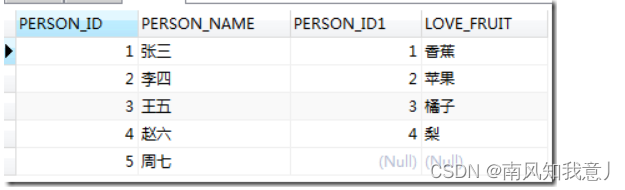
3.下面这条sql的执行结果
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID
边栏推荐
- LeetCode_ String_ Medium_ 151. Reverse the words in the string
- [Android] recyclerview caching mechanism, is it really difficult to understand? What level of cache is it?
- 43 box model
- Boosting之GBDT源码分析
- Promise对象与宏任务、微任务
- 继承的实现过程及ES5和ES6实现的区别
- JS 同步、异步,宏任务、微任务概述
- 剑指Offer | 二进制中1的个数
- LeetCode_字符串_中等_151.颠倒字符串中的单词
- Vs2010添加wap移动窗体模板
猜你喜欢
System.AccessViolationException: 尝试读取或写入受保护的内存。这通常指示其他内存已损坏

SPI传输出现数据与时钟不匹配延后问题分析与解决

什么是物联网

瀑布流布局

String type time comparison method with error string.compareto

"How to use" decorator mode

Splice a field of the list set into a single string

延迟加载源码剖析:

Raft of distributed consistency protocol

VS2010 add WAP mobile form template
随机推荐
About RDBMS and non RDBMS [database system]
Leetcode combination sum + pruning
args参数解析
js URLEncode函数
ES5写继承的思路
Application of object detection based on OpenCV and yolov3
瀑布流布局
[C topic] force buckle 876. Intermediate node of linked list
打开虚拟机时出现VMware Workstation 未能启动 VMware Authorization Service
图片裁剪cropper 示例
【JS高级】js之正则相关函数以及正则对象_02
我的创作纪念日
sql server强行断开连接
npm的nexus私服 E401 E500错误处理记录
继承的实现过程及ES5和ES6实现的区别
MeanShift聚类-01原理分析
Cmake specify opencv version
反射-笔记
[C题目]力扣206. 反转链表
MySql的安装配置超详细教程与简单的建库建表方法