当前位置:网站首页>PaddleOCR User Guide
PaddleOCR User Guide
2022-08-05 14:17:00 【the name of the algorithm】
First install paddle, then install paddleocr
pip install "paddleocr>=2.0.1"Identify images
from paddleocr import PaddleOCR, draw_ocrfrom PIL import Imageif __name__ == '__main__': ocr = PaddleOCR(use_angle_cls=True, lang='ch') img_path = 'demo/demo_kie.jpeg' result = ocr.ocr(img_path, cls=True) for line in result: print(line) image = Image.open(img_path).convert('RGB') boxes = [line[0] for line in result] txts = [line[1][0] for line in result] scores = [line[1][1] for line in result] im_show = draw_ocr(image, boxes, txts, scores, font_path='data/chineseocr/labels/font.TTF') im_show= Image.fromarray(im_show) im_show.save('output/result5.jpg')The lang in the PaddleOCR(use_angle_cls=True, lang='ch') here can be many languages, such as `ch`, `en`, `fr`, `german`, `korean`, `japan`.
This includes both text detection and text recognition. The general results are as follows

But if it is a relatively simple text, such as

At this time, we only need to identify, no need to detect
from paddleocr import PaddleOCR, draw_ocrif __name__ == '__main__': ocr = PaddleOCR(use_angle_cls=True, lang='en') img_path = 'demo/demo_text_recog.jpg' result = ocr.ocr(img_path,cls=True, det=False) for line in result: print(line)Running Results (Partial)
('STAR', 0.8838256597518921)Paddle OCR framework download address: GitHub - PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition,provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
Model training
Here is still taking Kaggle verification code text recognition as an example. The data set format of PaddleOCR is somewhat different from that of MMOCR. It needs to put the images of the training data set and the test data set in two differentin the folder.The general style is as follows

Since they were all put together before, write a script to separate them
import shutilif __name__ == '__main__': with open('data/toy_dataset/test_label.txt', 'r') as f: for line in f: filename = line.split(' ')[0] shutil.move('data/toy_dataset/train/' + filename, 'data/toy_dataset/test/' + filename)In addition, its tag files are separated by tabs \t, while in MMOCR they are separated by spaces.
2wc38.png 2wc38y5n6d.png y5n6dmen4f.png men4f57b27.png 57b27x3deb.png x3debModify the configs/rec/rec_icdar15_train.yml file in the PaddleOCR main directory. Of course, this is only one of the recognition frameworks. Let's take this as an example, and the modified parts are as follows
Train: dataset: name: SimpleDataSet# data_dir: ./train_data/ic15_data/ data_dir: ./data/toy_dataset/train/# label_file_list: ["./train_data/ic15_data/rec_gt_train.txt"] label_file_list:["./data/toy_dataset/train_label.txt"] transforms: - DecodeImage: # load image img_mode: BGR channel_first: False - CTCLabelEncode: # Class handling label - RecResizeImg: image_shape: [3, 32, 100] # Chinese[3, 32, 320] - KeepKeys: keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order loader: shuffle: True batch_size_per_card: 256 drop_last: True num_workers: 8 use_shared_memory: FalseEval: dataset: name: SimpleDataSet# data_dir: ./train_data/ic15_data data_dir: ./data/toy_dataset/test/# label_file_list: ["./train_data/ic15_data/rec_gt_test.txt"] label_file_list: ["./data/toy_dataset/test_label.txt"] transforms: - DecodeImage: # load image img_mode: BGR channel_first: False - CTCLabelEncode: # Class handling label - RecResizeImg: image_shape: [3, 32, 100] - KeepKeys: keep_keys: ['image', 'label', 'length'] # dataloader will return list in thisorder loader: shuffle: False drop_last: False batch_size_per_card: 256 num_workers: 4 use_shared_memory: FalseCopy train.py in the tools folder to the PaddleOCR main folder and add parameters
--config=configs/rec/rec_icdar15_train.yml
Run, start training.
边栏推荐
猜你喜欢

Capacity upgrade helps computing power flow, the acceleration moment of China's digital economy

【Search box】General test case

块分配器SLAB的内核实现

选择排名靠前的期货公司开户

为什么鲜有炫富的程序员?

day13·魔术方法__ call__与__del__

深度学习之 11 空洞卷积的实现
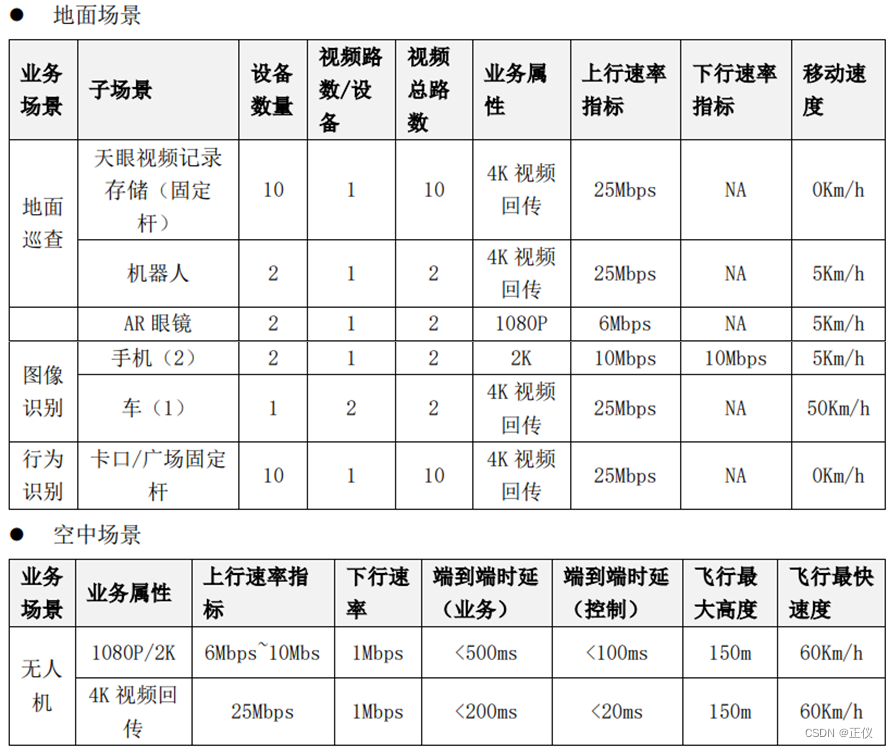
5G ToB业务介绍及时延需求
Docker study notes - cluster deployment based on example projects (5) Docker builds MySQL cluster | PXC cluster

@2023研考生:如何度过暑期研考备考“黄金期”
随机推荐
重视客户争取最大期货开户优惠
R语言ggplot2可视化:使用ggpubr包的ggsummarytable函数可视化dataframe数据的描述性统计量、ggtheme参数设置可视化图像使用的主题
day5·全局与局部变量
Kernel Implementation of Block Allocator SLAB
力扣解法汇总623-在二叉树中增加一行
荆棘与玫瑰:基础服务架构师的成⻓之路PPT
BOM学习
C#员工考勤管理系统源码 考勤工资管理系统源码
day6·动态导入模块
思科交换机命令大全,含巡检命令,网工建议收藏!
5G ToB业务介绍及时延需求
mmap内核实现及物理内存组织结构
1236288-25-7,DSPE-PEG-FA,Folic acid PEG DSPE,磷脂-聚乙二醇-叶酸脂质体形成材料
【Search box】General test case
day7·拆包与装包
获取淘宝/天猫购买到商品的订单详情——buyer_order_detail
Some understanding of multithreading
子网掩码和子网划分
day8·函数封装
Stuck at sill idealTree buildDeps when npm install