当前位置:网站首页>Improving deep neural networks: hyperparametric debugging, regularization and optimization (III) - hyperparametric debugging, batch regularization and program framework
Improving deep neural networks: hyperparametric debugging, regularization and optimization (III) - hyperparametric debugging, batch regularization and program framework
2022-06-27 22:36:00 【997and】
This study note mainly records various records during in-depth study , Including teacher Wu Enda's video learning 、 Flower Book . The author's ability is limited , If there are errors, etc , Please contact us for modification , Thank you very much !
Improve deep neural networks : Super parameter debugging 、 Regularization and optimization ( 3、 ... and )- Super parameter debugging 、Batch Regularization and program framework
- One 、 Debug processing (Tuning process)
- Two 、 Select the appropriate range for the hyperparameter (Using an appropriate scale to pick hyperparaqmeters)
- 3、 ... and 、 Super parameter debugging practice :Pandas vs Caviar(Hyper)
- Four 、 Activation function of normalized network (Normalizing activations in a network)
- 5、 ... and 、 take Batch Norm Fit into neural networks (Fitting Batch Norm into a neural network)
- 6、 ... and 、Batch Norm Why does it work (Why does Batch Norm work?)
- 7、 ... and 、 During the test Batch Norm(Batch Norm at test time)
- 8、 ... and 、softmax Return to (softmax regression)
- Nine 、 Train one softmax classifier (Training a softmax classfier)
- Ten 、 Deep learning framework (Deep Learning frameworks)
- 11、 ... and 、TensorFlow
The first edition 2022-05-23 first draft
One 、 Debug processing (Tuning process)

The most important thing is the learning rate α, Next, the yellow box , Then there is the purple box ,β1,β2,ε Selected as 0.9、0.999 and 10-8
In deep learning , Common practice is to randomly select points , Because the problem to be solved , It's hard to know which super parameter is more important .
Suppose three super parameters , The search is for a cube , To test more values .
From rough to fine strategy :
Take the value in the two-dimensional example , Will find the best point , Maybe the surrounding effect is also good , Zoom in on this area , In which more intensive values or random values , Gather more resources . If you doubt the effect of the hyperparameter in this region , After a rough search of the whole square , Should be clustered into smaller squares .
Two 、 Select the appropriate range for the hyperparameter (Using an appropriate scale to pick hyperparaqmeters)

Random values improve the search efficiency , But it is not a random uniform value within the effective range , It's about choosing the right scale .
or Select the layer number of neural network , be called L
Suppose you are searching α, from 0.0001 To 1 The number axis of , Yes 90% The value of will fall at 0.1 To 1 Between .
Instead, it is more reasonable to search with a ruler , Take..., respectively 0.0001,0.001,0.01,0.1,1.
summary :
Take value in logarithmic coordinates , Take the logarithm of the minimum value to get a Value , Take the logarithm of the maximum and you get b value , So now on the logarithmic axis 10a To 10b Interval values , stay a,b Choose randomly and evenly r value , Set the super parameter to 10r, This is the process of taking values on the logarithmic axis .
Finally, to β Value , Used to calculate the weighted average of the index . Assume that 0.9 To 0.999 Between ,0.9 similar 10 The values are averaged .
Why the linear axis is not a good idea ? Because when β near 1 when , The sensitivity of the results will vary .
3、 ... and 、 Super parameter debugging practice :Pandas vs Caviar(Hyper)

Maybe the data center has updated the server , The original parameter setting may not be easy to use , At least every few months .
1. A model , There are usually huge data sets , But not many computing resources or enough CPU and GPU, Only a small number of models , It can be improved gradually , such as : The first 0 God , Random parameter initialization , Observe the curve , The first 1 You may learn well at the end of the day , Then try to increase the learning rate , Two days later, it was still good , Observe the model every day .
2. Test multiple models at the same time , Finally, choose the one that works best
Four 、 Activation function of normalized network (Normalizing activations in a network)

Batch normalization ,μ Average , Training set subtraction average , Calculate the variance and then normalize the data set according to the variance .
For deeper networks , Such as normalization a[2] Value , Train faster w[3],b[3], Strictly speaking , The real normalization is z[2],
Suppose there are some hidden cell values , The figure is for l layer , But save l.
We don't want hidden cells to always contain averages 0 And variance 1, Maybe it makes sense to have different distributions of hidden units , call z{i}, Will update with gradient descent γ and β.
Such as , Yes sigmoid Activation function , I don't want the total set of values to be here , Want them to have a larger variance , Or not 0 Average value , To take advantage of nonlinearity sigmoid function . therefore ,γ and β The real effect is to standardize the mean and variance of hidden unit values ,
5、 ... and 、 take Batch Norm Fit into neural networks (Fitting Batch Norm into a neural network)

It can be said that each unit is responsible for calculating two things , First, calculate z, Then it is applied to the activation function to calculate a.
Batch Normalization is to normalize z[1] Value for Batch normalization , abbreviation BN, from β and γ control .
And then there's the a Calculation z, Do something similar to the first layer …
here β And the previous calculation of the exponentially weighted average β It doesn't matter , to update dβ, It can be used Adam or RMSprop or Momentum To update β and γ.
In the framework of deep learning , One line of code can handle Batch normalization .
First mini-batchX[1], And then calculate z[1]…
Pay attention to the calculation z The way , but Batch What normalization does is , It depends on this mini-batch, First the z normalization , The result is the mean 0 And standard deviation , Again by β and γ Rescale , But that means , No matter what b What's the value of , Are to be subtracted , Because in Batch In the process of normalization , You have to calculate z The average of , Subtract the average , In this case mini-batch Add any constant to , The values will not change , Because any constant added will be offset by subtracting the mean . So in Batchguiyihua Can eliminate b Or set to 0.

summary : About how to use Batch Normalization to apply the gradient descent method
Suppose you are using mini-batch Gradient descent method , You run t =1 To batch In quantity for loop , Will you be in mini-batch X{t} Apply forward prop, Every hidden layer applies forward prop, use Batch Normalization replaces z by z hat . Next , It ensures that in this mini-batch in ,z Values have normalized mean and variance , After normalizing the mean and variance, it's z hat , then , You use reverse prop Calculation dw and db, And all l All parameters of the layer ,dβ and dγ. Although strictly speaking , To get rid of db. Last , You update these parameters :W、β、γ
6、 ... and 、Batch Norm Why does it work (Why does Batch Norm work?)

1. Normalization is not just for the input values here , And the value of the hidden unit , You can go from 0 To 1, Speed up learning
2. It can make weights lag or go deeper than your network , As an example , The idea of changing the distribution of data , be known as “Cobariate shift”, If you have learned x To y Mapping ,x Distribution changes , It may be necessary to retrain the learning algorithm .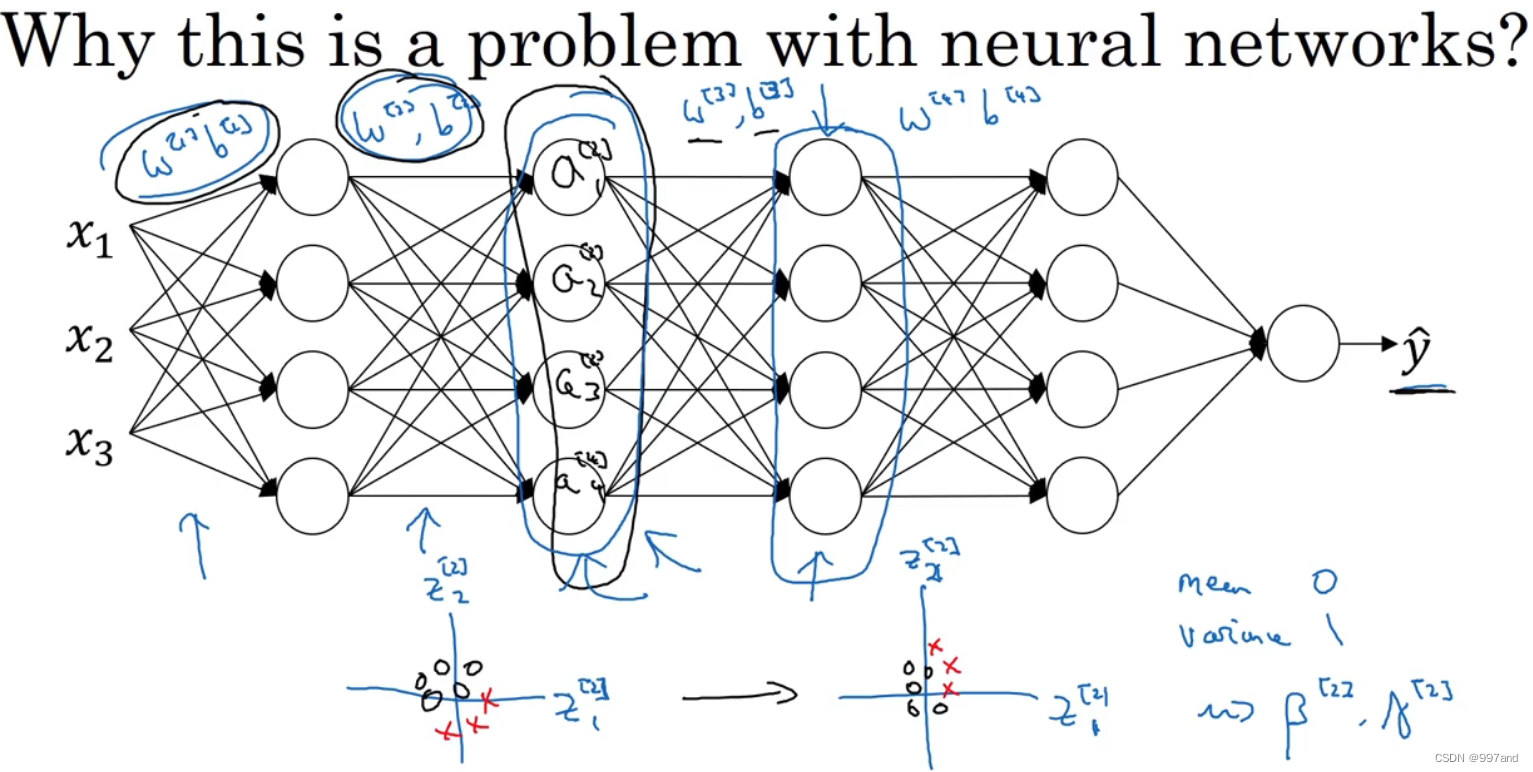
Looking at the learning process from the third level , The parameters have been learned w[3] and b[3], What is needed next to make y The cap is close to the true value y. From the perspective of the third hidden layer , The values of these hidden cells are constantly changing .
batch What normalization does is , Reduces the number of changes in the distribution of these hidden values . As shown below , It's about z1,z2 The value of can be changed ,batch Normalization ensures that whatever changes ,z1,z2 The mean and variance of are kept constant . The mean and variance can be forced , But it limits the parameter update of the previous layer , Will affect the degree of numerical distribution .
batch Normalization reduces the problem of changing input values . What it does is keep learning in the current layer , When the change , Force the back layer to adapt less .
batch Normalization also has a slight regularization effect ,mini-batch There will be some small noise in the upper mean and variance .
1.batch Normalization contains several layers of noise , Because of the scaling of the standard deviation and the extra noise caused by subtracting the mean . Can be batch Normalization and dropout Use it together .
2. If a larger mini-batch, Reduced noise , Therefore, the regularization effect is reduced , yes dropout A strange property .
7、 ... and 、 During the test Batch Norm(Batch Norm at test time)

m Express this mini-batch Number of samples in . add ε For numerical stability .
In order to apply neural network to test , The mean and variance need to be estimated separately ,batch Normalization requires an exponential weighted average to estimate .
Finally, in the test , Normalized z.
8、 ... and 、softmax Return to (softmax regression)

There are only two possible markers for dichotomy 0 or 1, and softmax There are many possibilities for regression . cat 1, Dog 2, Chick 3, other 0.
use C Indicates the total number of categories that the input will be classified into .
As shown in the figure, neural network , The output layer has 4 individual , We want these four layers to tell us the probability of each of the four types .
Take a look softmax Write the formula and see , Temporary variable t. On the right is an example .
softmax The activation function is special in that , Because all possible outputs need to be normalized , You need to input a vector , Finally, I'll output a vector .
The top three are 3 A linear decision boundary .
C=4、C=5、C=6, Shows softmax What a classifier can do without a hidden layer .
Nine 、 Train one softmax classifier (Training a softmax classfier)

Notice that the largest element is 5, And the maximum probability is also the first probability .
softmax The name comes from hardmax.C=2,softmax Regression actually turns back to logistic Return to .
Gradient descent method is used to reduce the loss of training set , The only way to make it smaller is to make it smaller -logy Cap becomes smaller , You need to y Cap as large as possible , But no better than 1 Big .
The output layer calculates z[l], It is C x 1 Dimensional .
Ten 、 Deep learning framework (Deep Learning frameworks)

Choose a deep learning framework :
1. Easy to program
2. Running speed
11、 ... and 、TensorFlow

The loss function shown in the figure , use TensorFlow To minimize the 
Learning rate 0.01
边栏推荐
- 关于davwa的SQL注入时报错:Illegal mix of collations for operation ‘UNION‘原因剖析与验证
- 解决本地连接不上虚拟机的问题
- Oracle obtains the beginning and end of the month time, and obtains the beginning and end of the previous month time
- The problem of minimum modification cost in two-dimensional array [conversion question + shortest path] (dijkstra+01bfs)
- Educational Codeforces Round 108 (Rated for Div. 2)
- Summary of gbase 8A database user password security related parameters
- Acwing weekly contest 57- digital operation - (thinking + decomposition of prime factor)
- The create database of gbase 8A takes a long time to query and is suspected to be stuck
- 百万年薪独家专访,开发人员不修复bug怎么办?
- 年薪50W+的测试大鸟都在用这个:Jmeter 脚本开发之——扩展函数
猜你喜欢
【微服务】(十六)—— 分布式事务Seata

管理系統-ITclub(下)

Go from introduction to practice -- shared memory concurrency mechanism (notes)

Crawler notes (3) -selenium and requests

Summary of Web testing and app testing by bat testing experts
Test birds with an annual salary of 50w+ are using this: JMeter script development -- extension function
BAT测试专家对web测试和APP测试的总结
Conversion between flat array and JSON tree

《7天学会Go并发编程》第7天 go语言并发编程Atomic原子实战操作含ABA问题

百万年薪独家专访,开发人员不修复bug怎么办?

随机推荐
Go from introduction to practice -- shared memory concurrency mechanism (notes)
Codeforces Round #716 (Div. 2)
Which method is called for OSS upload
Go from introduction to actual combat - only any task is required to complete (notes)
This set of steps for performance testing using JMeter includes two salary increases and one promotion
How to do function test well? Are you sure you don't want to know?
Codeforces Round #722 (Div. 2)
年薪50W+的测试大鸟都在用这个:Jmeter 脚本开发之——扩展函数
The "business and Application Security Development Forum" held by the ICT Institute was re recognized for the security capability of Tianyi cloud
[MySQL practice] query statement demonstration
Remote invocation of microservices
The karsonzhang/fastadmin addons provided by the system reports an error
The create database of gbase 8A takes a long time to query and is suspected to be stuck
《7天學會Go並發編程》第7天 go語言並發編程Atomic原子實戰操作含ABA問題
OpenSSL Programming II: building CA
正则表达式
AQS SOS AQS with me
解决本地连接不上虚拟机的问题
A method of go accessing gbase 8A database
渗透学习-靶场篇-dvwa靶场详细攻略(持续更新中-目前只更新sql注入部分)