当前位置:网站首页>Practice of federal learning in Tencent micro vision advertising
Practice of federal learning in Tencent micro vision advertising
2022-06-26 16:00:00 【Tencent big data official】

Sharer : Song Kai Doctor
The arranger : Lin Yizhen
Reading guide :
From the perspective of advertisers , Share the experience and thinking of federal learning practice .
First introduce the background of business and technology selection : Team projects for user growth and cost control , The way is advertising channel , The launch target is divided into pull new 、 Pull two kinds of .
- When pulling new , The characteristics of users in the side end of micro vision are sparse , And advertising platforms accumulate a lot of information , But only limited oCPX Standardized data return .
- When pulling alive , The micro vision side has valuable portrait data such as user behavior sequence , It is complementary to the characteristics of advertising platform , But they can't share data directly and rudely with advertising platforms .
therefore , It is hoped that the micro vision side and the advertising platform side can use the data of both sides , Achieve win-win results , But ensure the security of data without going out of the domain . In this context, our team chose “ Federal learning ”, It provides a solution for multi-party security cooperation .
The article focuses on the following five points :
- Federal learning
- Tencent federal learning platform PowerFL
- The overall business of micro vision advertising
- Advertising federal learning architecture
- Modeling practice and details
One 、 Federal learning
First , Introduction to federal learning (Federated Learning,FL) Leading knowledge of .
1. Federal learning background
Machine learning models are data-driven, But in reality, the data are isolated islands : Between companies 、 Even data cannot be shared between departments ; Direct sharing will violate users' privacy , It also damages the interests of the company .2016 year Google The article is written in input method NLP In the background , A local update model with Android mobile terminal is proposed , This article is generally regarded as the beginning of federal learning . immediately , China's Weizhong bank 、 Tencent and other companies have also done a lot of pioneering work .
The basic definition of federal learning is : In the process of machine learning , All participants can conduct joint modeling with the help of data from other parties . Each party does not need to have direct access to other party's data resources , That is, when the data is not out of the local area , Conduct data joint training safely , Build a shared machine learning model .
2. Two structures of Federated learning
- Centralized federal architecture : Early development includes Google、 Small Banks , Are all such architectures . By a trusted third party ( Central server ) Responsible for encryption policy 、 Model distribution 、 Gradient polymerization, etc .
- Decentralized federal Architecture : Sometimes the two sides cooperate , Can't find a trusted third party , All parties need to participate in peer-to-peer calculation . This architecture requires more encryption and decryption and parameter transmission operations , such as :n When the parties are involved , To be carried out 2n(n-1) Secondary transmission . It can be considered that the encryption and decryption algorithm actually plays the role of a third party .
3. Three categories of federal learning
- Horizontal federal learning : Union of samples , It is applicable to multiple overlapping features , The scene when users overlap less . such as : Two companies with similar businesses , There are many orthogonal users, but the portraits are similar , Horizontal federal learning , It's more like distributed machine learning with data deformation .
- Longitudinal federal learning : The combination of features , Apply to users with more overlap , Scene with less feature overlap . such as : Advertisers and advertising platforms , Hope to combine the characteristics of both sides for training .
- Federal transfer learning : When there is little overlap of characteristics and samples between participants , Consider using , But it's more difficult .
The information of three kinds of federal learning interaction is different , The troubles are also different ; such as : When learning horizontally , The data of all participants is heterogeneous , Therefore, the data are not independent and identically distributed , It is also a research hotspot of federal learning .
At present, vertical federal learning has been implemented in our business , Also exploring federal transfer learning 、 Horizontal and vertical combination .

4. Comparison between federated learning and distributed machine learning
Upper bound of precision : Federated learning is not like optimizing other specific sorting 、 Recall model , It's more like under data security restrictions , To drive the whole modeling . therefore , In theory, share data into distributed machine learning (Distributed Machine Learning,DML) As the upper limit .
Federal learning (FL) And distributed machine learning (DML) Compare
Although some people regard federated learning as a special case of distributed machine learning , But with the general DML comparison , Federal learning still has the following differences :
- There is a restriction that data is not shared ;
- various server Node pair worker Node control is weak ;
- High communication frequency and cost .
Two 、 Tencent federal learning platform Angel PowerFL
Starting with the development of federal learning , Tencent's participation is very high . Include : Make a release 《 Federal learning white paper 2.0》、《 Tencent security federation learning application service white paper 》 etc. ; Infrastructure , Based on Tencent's open source intelligent learning platform Angel(https://github.com/Angel-ML/angel), structure PowerFL, At present, it is internally open source ; In practice , In Finance 、 advertisement 、 Recommended scenarios , There are many attempts and landing .
1. Engineering features
Tencent federal learning platform PowerFL Besides being easy to deploy 、 Good compatibility and other basic requirements of machine learning platform , There are also the following five engineering features :
- Learning architecture : Use a decentralized federated Architecture , Don't rely on third parties ;
- encryption algorithm : Various common homomorphic encryption methods are implemented and improved 、 Symmetric and asymmetric encryption algorithms ;
- Distributed computing : be based on Spark on Angel Distributed machine learning framework ;
- Cross network communication : utilize Pulsar Optimize cross network communication , Enhance stability , Provide multi-party cross network transmission interface ;
- Trusted execution environment :TEE(SGX etc. ) Exploration and support .
2. Algorithm optimization
in addition , Many optimizations have also been made for the algorithm side :
- Ciphertext operation rewriting : be based on C++ GMP Rewrite ciphertext operation Library ;
- Data intersection optimization : Optimize... On both sides and multiple sides respectively , In particular, the multi-party side has been transformed theoretically ( The improved FNP agreement );
- GPU Support : The ciphertext operation part can be used GPU parallel ;
- Model extension support : Support flexible model expansion , You can use Tensorflow、Pytorch Development DNN Model embedding .
It is worth mentioning that , In addition to homomorphic encryption schemes ,PowerFL It also supports secret sharing and differential privacy ( Noise disturbance ) And other federal neural network privacy protection schemes .
3、 ... and 、 The overall business of micro vision advertising
An overall goal of our team is to iteratively optimize the intelligent delivery system , We made efforts from the following three points :
1. Increase the channel of getting customers
Including outer canal purchase 、 Internal soft diversion 、 Self growth ; among , The realization form of outer canal purchase can be subdivided into Marketing API Create advertisements in batches 、RTA Crowd orientation 、sDPA/mDPA Commodity bank 、RTB Real time bidding, etc .
2. Increase material form
In order to undertake Marketing API、RTA, Continuously optimize advertising creativity ; In order to undertake RTB、sDPA/mDPA, Optimize native advertising content ; In order to share with the growing / The recruits echo , Optimized subsidies 、 Red envelopes 、 Strategies or models such as coupons .
3. Growth technology
No matter what RTA、RTB, The core is to optimize the accurate matching between users and materials . We focus on the material 、 user 、 The interaction between the two continues to explore :
- In terms of materials : Including making 、 mining 、 understand 、 The quality control , such as : Selection of content prone to negative feedback 、 Recognition and enhancement of clarity 、 Automatic uploading, downloading and bidding of materials .#
- User side : The portrait side continues to build user portraits , Such as crowd expansion (lookalike)、 User label ; On the operation side uplift、LTV Model propulsion ; Experience side pursues pull bearing integration .
- In terms of flow : The core of advertising decision-making is the management of traffic and cost , Develop a series of strategies here ; At present, reinforcement learning has been tried , To solve the dilemma between traffic and cost .

Four 、 Advertising federal learning architecture
The following describes the role of federal learning in the framework of micro vision advertising : Yes RTA Circle selection of crowd package .
1. Overview of advertising system
First , The following figure shows a simple and universal advertising system : From user equipment ID Your ad request , Reach the advertising system ; Recall through advertising 、 Ad directed filtering RTA、 Rough layout of advertisements 、 Ad detail 、 The advertisement was issued , Finally, the advertising exposure .

2. RTA Advertising structure
then , We put one of them RTA Zoom in on the side frame .RTA The purpose of is to pre judge the user value , Perform crowd orientation 、 Auxiliary quality bid .
- RTA Advertising request origination , User equipment ID Arrive at the experimental platform ;
- Through the distribution strategy of the channel and ID Mapping distinguish , Use the strategy of revitalizing historical users to undertake 、 Non historical users use the pull new strategy to undertake ;
- What federal learning decides is RTA-DMP Side , Import in the form of crowd package DMP, Conduct crowd orientation and stratification .
3. Federated learning coarse-grained framework
here , Let's introduce the coarse-grained framework of Federated learning :
- The micro vision side provides users with ID、 portrait 、Label, The advertising platform side provides users ID、 portrait ;
- Safety sample alignment (Private Set Intersection,PSI) Get user intersection , Start federal learning collaborative training ;
- After model evaluation , The two sides cooperate to extract the full amount of user features and export , And score all users ;
- Finally return the result to RTA-DMP.
In the fifth part, we will disassemble .
5、 ... and 、 Modeling practice and details
1. Pilot operation
Compared to pulling alive , Laxin is more eager to use federal learning , Because the features in the end are more sparse , Many users have only user devices ID; therefore , Give priority to cutting in and pulling new , The pilot work includes :
1.1 Fit the target : Four task model
- Main task : Primary startup and secondary retention rate , namely T Rilaxin ,T+1 Day active open micro vision APP Proportion of retained users .
- Deputy task : Primary startup and secondary retention costs 、 Effective new costs 、 Effective newly added proportion ; among , User addition effectiveness has been modeled , According to behavior such as residence time , Give a probability score .
1.2 Micro vision unilateral data exploration and feature engineering
- Sample and sampling : Find out the sample size , Determine the sampling strategy .
- Features and models :ID Class characteristics 、 Behavioral sequence characteristics ; Use DNN Model .
- Develop offline metrics consistent with online performance : After exploration ,Group-AUC Is a good offline indicator ,Group That is, user layering .Group-AUC Positively correlated with online performance , And AUC More sensitive .
2. model training
Finish the preparations , The micro vision side began to conduct joint federal learning modeling with the advertising platform side .
2.1 Iterative process of Federated model training
(1) Data alignment : Determine a common set of samples for collaborative training {id}, There are two ways
- Plaintext : Fast , Exchange between billion and billion levels , Just a few minutes ~ Ten minutes , But this method is not safe , Because both parties only want to confirm the public assembly part , I don't want to reveal my complement ; Use a trusted environment (TEE), Ensure security in clear text .
- Ciphertext : Slow speed , More expensive 10 More than times the time , Because it involves a lot of encryption and decryption operations and collisions ; We currently use this strategy , With the help of Since the research PowerFL Platform implementation .
(2) Multi feature engineering
- Longitudinal federal learning : The features on both sides are independent , Divide and rule , such as : Standardization of features 、 completion .
- Horizontal federal learning : Acquisition of partial statistics , We need to obtain the total distribution of the whole feature , Still use federated learning communication to solve data synchronization .
(3) Joint training
- Determine the computing environment 、 Storage resources .
- Communications ( What physical quantity carries , Like gradients 、embedding).
(4) Offline assessment
(5) Online assessment
2.2 be based on DNN Federal model of (FL-DNN)
Micro vision side and advertising platform AMS Side to side training multitasking DNN Model , Multi task structure from sample strategy 、 Modify simple implementation methods such as loss function , Evolve to MMoE ; Engineering is based on Horovod parallel .

2.3 FL-DNN Iterative process of model parameters
(1) initialization :A(host,AMS Side )、B(guest, Micro vision side ) Initialize their respective networks respectively ( Write it down as ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_19.jpg) and
and ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_16.jpg) ) Parameters of
) Parameters of ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_21.jpg) 、
、 ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_20.jpg) , Interaction layer parameters
, Interaction layer parameters ![[ The formula ]](http://img.inotgo.com/imagesLocal/202105/24/20210524154428540y_10.jpg) , Record the learning rate as
, Record the learning rate as ![[ The formula ]](http://img.inotgo.com/imagesLocal/202106/13/20210613010200891c_19.jpg) , Record the noise as
, Record the noise as ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_0.jpg) 、
、 ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_1.jpg) 、
、 ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_17.jpg) ;
;
(2) Forward propagation :( ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_42.jpg) Indicates homomorphic encryption )
Indicates homomorphic encryption )
- A Side calculation : Calculation
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_34.jpg) ; Encrypted to get
; Encrypted to get ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_10.jpg) ( That is to say A Side output embedding), Send it to B.
( That is to say A Side output embedding), Send it to B. - B Side calculation : Do the same embedding Compute to generate
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_36.jpg) , Is symbolic symmetry , remember
, Is symbolic symmetry , remember ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_23.jpg) ; receive , And calculate
; receive , And calculate ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_41.jpg) , And then calculate
, And then calculate ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_29.jpg) And send it to A.
And send it to A. - A Side receiving
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_11.jpg) , Decryption is
, Decryption is ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_44.jpg%2B%5Cepsilon%5EB) ; Calculation
; Calculation ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_3.jpg) And send it to B
And send it to B - B Side receiving , subtract
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_1.jpg) , obtain
, obtain ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_32.jpg) . In interactive networks
. In interactive networks ![[ The formula ]](//img.inotgo.com/imagesLocal/202201/06/202201062323304663_3.jpg) Next spread , obtain
Next spread , obtain ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_22.jpg) , Calculate the loss function
, Calculate the loss function ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_5.jpg) .
.
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_34.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_10.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_36.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_23.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_41.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_29.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_11.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_44.jpg%2B%5Cepsilon%5EB)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_3.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_32.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202201/06/202201062323304663_3.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_22.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_5.jpg)
(3) Back propagation
- B Side calculation : Loss function versus parameter
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_44.jpg) 、
、 ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_49.jpg) Derivation , Get the gradient
Derivation , Get the gradient ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_26.jpg) 、
、 ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_25.jpg) ; Calculation
; Calculation ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_47.jpg) , And send it to A.
, And send it to A. - A Side receiving And decrypt ; Calculation
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_26.jpg%5Ccdot+X%5EA%2B%5Cepsilon%5EB%2B%5Cepsilon%5EA%2F%5Ceta) , encryption
, encryption ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_46.jpg) , Send two quantities to B.
, Send two quantities to B. - B Side receiving and ; Calculate the relative gradient of the loss function
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_2.jpg+%3D+%5B%5Bg%5EA%5Ccdot+%28I%2B%5Cepsilon%5E%7Bacc%7D%29%5D%5D) , And will
, And will ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_2.jpg) Send to A.
Send to A. - A Side receiving And decrypt .
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_44.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_49.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_26.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_25.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_47.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_26.jpg%5Ccdot+X%5EA%2B%5Cepsilon%5EB%2B%5Cepsilon%5EA%2F%5Ceta)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_46.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_2.jpg+%3D+%5B%5Bg%5EA%5Ccdot+%28I%2B%5Cepsilon%5E%7Bacc%7D%29%5D%5D)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_2.jpg)
(4) Gradient update :A、B、I Update the gradient respectively , Complete a round of iterations :
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_21.jpg+%2B%3D+%5Cdelta+W%5EA)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_20.jpg+%2B%3D+%5Cdelta+W%5EB)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202105/24/20210524154428540y_10.jpg+%2B%3D+%5Ceta%28g%5EA%5Ccdot+W%5EA+%2B+%5Cepsilon%5EA%2F%5Ceta%29)
This structure is similar to recall 、 The twin towers commonly used for rough row seem similar , But in fact, the design principles are not the same . The twin tower structure is often criticized embedding It's too late to interact , So there are many improved versions , such as MVKE Model ( tencent ), hold embedding The interaction time is early . In longitudinal federal learning ,A On the side ![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_6.jpg) It can be on the first floor , It didn't even change ( That is, only feature encryption ) Hand over to B Side , In this way, in principle, there is no problem of interaction timing .
It can be on the first floor , It didn't even change ( That is, only feature encryption ) Hand over to B Side , In this way, in principle, there is no problem of interaction timing .
2.4 FL-DNN Special case of model parameter iteration : Unilateral features
B(guest Side ) With no or too weak characteristics , Only user equipment can be provided ID、label, The iterative process of the above parameters degenerates to no The situation of , Readers can try to write down the parameter update process .
In the actual , Because of the amount of data 、 Feature coverage 、 Cross loss and other problems , To guarantee DNN Well trained , The following two cases are superimposed :
- B No features on the side :<id,label>+ <id, features>;
- B Side features :<id,label,features> + <id, features>.
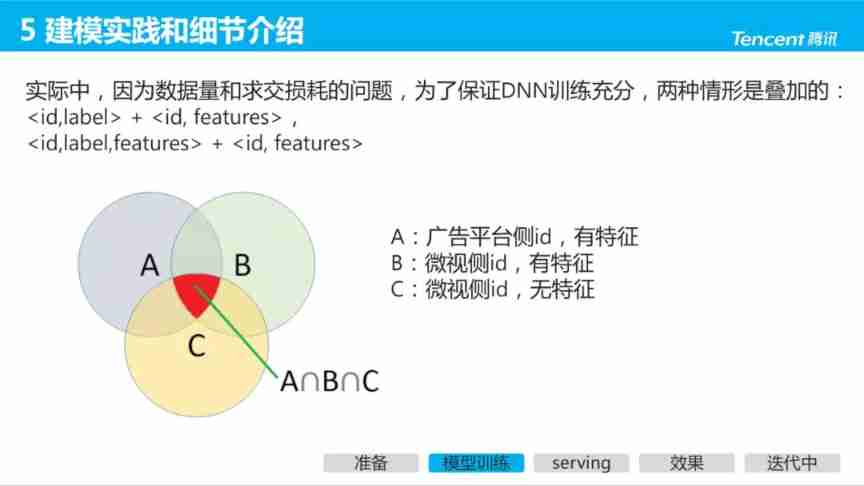
3. Online services
All participants can only get their own model parameters , The prediction needs the cooperation of all parties :
(1) Send a request : User equipment ID, Touch... Respectively A、B;
(2)embedding Calculation
- A Side calculation
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_15.jpg) , encryption
, encryption ![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_9.jpg) ;
; - B Side calculation
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_16.jpg%28x%5EB%2C%5Comega%5EB%29) ;
;
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_15.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_9.jpg)
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_16.jpg%28x%5EB%2C%5Comega%5EB%29)
(3)label Calculation
- A The side will issue B Side ;
- B Side calculation label
![[ The formula ]](//img.inotgo.com/imagesLocal/202202/17/202202170506472444_43.jpg) ;
; - B Side decryption gets y.
![[ The formula ]](http://img.inotgo.com/imagesLocal/202202/17/202202170506472444_43.jpg)
4. Effect display
In connection with Tencent guangdiantong AMS In cooperation with , Relative micro vision training alone , Federal learning makes Group-AUC +0.025; The main objective is 3 All sub goals are positively correlated and improved . The main target is the primary startup and secondary retention rate ( After conversion of coverage ) promote +4.7PP. After the first edition went online, all indicators were significantly improved , Full volume has been released . The second version of the iteration also achieved GAUC Significant improvement , Is experimenting with small traffic .

The following figure shows the effective reduction of primary startup and secondary retention costs ( Orange ):

5. In iteration
5.1 Pull a new model
Promote federal collaboration with other channels , But the team is unable to maintain a federated model on every launch platform . Preliminary attempts will be made with AMS Model of platform joint training , Put it on other platforms and pull it new . But because the data is heterogeneous ( Sample distribution deviation ) Wait for a reason , This model is inferior to base Model ( One side of micro vision ) good ; In addition, there is a conflict of interest among the delivery platforms , We all hope that advertisers will focus on their own traffic , therefore , We are trying to combine horizontal and vertical : Micro vision and advertising platform are vertical , Advertising platforms are horizontal , It is expected to start from the tripartite Federation cooperation , Currently, the idea of Federated migration is being iterated .
5.2 Pull live model
And AMS Platform cooperation , After the federal model gets through , We want to reuse it on the pull live model . Because user activation is multi-objective 、 How interested 、 The case of a sequence of different behaviors , We focus on timeliness and model innovation , Based on MMoE-Mind-transformer Exploration of model .
5.3 Iteration is difficult
(1) Efficiency and stability
- Improve data alignment speed : To increase the speed of ciphertext intersection , Hash bucket division to achieve simple parallelism and speed up .
- Compress training time : Incremental training to do finetune; Similar results to full training , Half the time .
(2) Interpretability and debug difficult : Neither side of the Federation can see each other's raw data , Even sometimes both sides hide their neural network structures . This ensures the security of certificate data ; But from an iterative perspective , Problem location is more difficult .
(3) The difficulty of multi-party Federation modeling
- Joint modeling with multiple cooperative advertising platforms , There is a conflict of interest , And Google FedAvg The scene is different .
- Joint modeling with other business units , Such as WeChat 、 Search has strong and powerful features , But the other person has no motive .
- There are technologies / Network stability / Communication costs .
6、 ... and 、Q&A
Q1. TEE( Trusted execution environment ) Is it necessary in federal learning tasks ? What scenario will be based on TEE To complete the task ? The project currently introduced is based on TEE Calculated ?
A1. Not currently used TEE Environmental Science , If you use TEE You can directly operate in plaintext , No need for a lot of encryption operations ; because TEE In the environment, even if plaintext operation is guaranteed , Data is also secure and invisible to each other ; At present, no matter the data is handed over 、 model training ( gradient 、embedding) All ciphertext operations .
Q2. The first step in federated learning is data alignment , Do you need to maintain the mapping table ?
A2: No need to maintain the mapping table , Factor one billion users plus characteristics , The amount of mapping table data reaches hundreds G Level , In fact, it is a waste of resources ; The actual operation of sample alignment is in sequence , From the advertising platform side ID, It's in the agreed order from top to bottom , That is, there is no need to maintain kv The mapping relation of .
Q3. Serving( Online services ) when , Need to take each other ( Advertising platform ) Characteristics of , How about this delay ?
A3. Serving The delay is caused by communication , The advertising platform trains the model on the side of the advertising platform on its own machine , The micro vision side trains the model of the micro vision side on its own machine , The final interaction is also interaction embedding.
Q4. In all cases ,B Side (guest Side ) Provide label Are they all necessary ?
A4. B Side (guest Side , Micro vision side ), Because the data cannot be out of the field, it will not provide label Give each other , see “FL-DNN Iterative process of model parameters ” The formula in this chapter shows that , The gradient is at B Side calculation completed , The other party cannot know label.
Q5. After using federal learning Group-AUC increase +0.025, Not used before federal learning Group-AUC How much is the ?
A5. The value is not very direct , Sample definitions in different scenarios 、 The fitting target changes, that is, change ; Originally from 0.70 Level , mention 0.72-0.73 Level .
Q6. Tencent sent it some time ago MKVE The full name of the paper is ?
A6. 2021-tencent-Mixture of Virtual-Kernel Experts for Multi-Objective User Profile Modeling.
Q7. FL-DNN Modeling requires a third party , How to trust third parties ?
A7. In fact, according to the decentralized architecture, there is no need for a third party , It can be undertaken by a series of encryption and decryption algorithms .
Q8. If both sides are TEE Execution environment , Are all the data exchanged in the network in clear text ?
A8. Yes , In plain text .
Q9. Federal framework and RTA combination , It's an offline crowd package , Or online real-time estimation ?
A9. After exploration , The real-time importance of pulling the new side is not high , Is to import the offline crowd package into DMP, Give again RTA docking ; Pull the active side because you want to catch the user's interest change in a short time , There are real-time requirements , At present, we are studying .
边栏推荐
- 手写数字体识别,用保存的模型跑自己的图片
- Why are encoder and decoder structures often used in image segmentation tasks?
- 【leetcode】331. 验证二叉树的前序序列化
- svg上升的彩色气泡动画
- Have you ever had a Kindle with a keyboard?
- 5000字解析:实战化场景下的容器安全攻防之道
- JS simple deepcopy (Introduction recursion)
- 基于 MATLAB的自然过渡配音处理方案探究
- Svg animation around the earth JS special effects
- 9 Tensorboard的使用
猜你喜欢

Solana capacity expansion mechanism analysis (2): an extreme attempt to sacrifice availability for efficiency | catchervc research

js创意图标导航菜单切换背景色

canvas三个圆点闪烁动画

svg canvas画布拖拽

Nanopi duo2 connection WiFi

Anaconda3 installation tensorflow version 2.0 CPU and GPU installation, win10 system

李飞飞团队将ViT用在机器人身上,规划推理最高提速512倍,还cue了何恺明的MAE...

如何配置使用新的单线激光雷达

如何辨别合约问题
Svg canvas canvas drag
随机推荐
(一)keras手写数字体识别并识别自己写的数字
Audio and video learning (I) -- PTZ control principle
Svg animation around the earth JS special effects
[problem solving] the loading / downloading time of the new version of webots texture and other resource files is too long
音视频学习(一)——PTZ控制原理
零知识 QAP 问题的转化
HW安全响应
反射修改final
【leetcode】48. Rotate image
现在券商的优惠开户政策是什么?现在在线开户安全么?
查词翻译类应用使用数据接口api总结
Beijing Fangshan District specialized special new small giant enterprise recognition conditions, with a subsidy of 500000 yuan
JVM notes
[thinking] what were you buying when you bought NFT?
Binding method of multiple sub control signal slots under QT
PCIe Capabilities List
When a project with cmake is cross compiled to a link, an error cannot be found So dynamic library file
Development, deployment and online process of NFT project (2)
Canvas three dot flashing animation
JS text scrolling scattered animation JS special effect