当前位置:网站首页>Redis+caffeine two-level cache enables smooth access speed
Redis+caffeine two-level cache enables smooth access speed
2022-06-24 21:56:00 【InfoQ】
RedisMemCacheRedisGuava cacheCaffeine
Advantages and problems
- Local cache is based on the memory of the local environment , Very fast access , For some changes, the frequency is low 、 Data with low real-time requirements , Can be put in the local cache , Improve access speed
- Using local caching can reduce and
RedisData interaction between remote caches of classes , Reduce network I/O expenses , Reduce the time-consuming of network communication in this process
preparation
CaffeineRedis<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.8.1</version>
</dependency>
application.ymlRedisspring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 10000ms
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
RedisTemplateredisRedisTemplateConnectionFactoryV1.0 edition
CaffeineCacheMapkeyvalueCache@Configuration
public class CaffeineConfig {
@Bean
public Cache<String,Object> caffeineCache(){
return Caffeine.newBuilder()
.initialCapacity(128)// Initial size
.maximumSize(1024)// The largest number
.expireAfterWrite(60, TimeUnit.SECONDS)// Expiration time
.build();
}
}
CacheinitialCapacity: Initial cache empty size
maximumSize: The maximum number of caches , Setting this value can avoid memory overflow
expireAfterWrite: Specify the expiration time of the cache , Is the time after the last write operation , here
expireAfterAccessrefreshAfterWriteCacheService@Service
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;
@Override
public Order getOrderById(Long id) {
Order order = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return order;
}
@Override
public void updateOrder(Order order) {
orderMapper.updateById(order);
}
@Override
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
}
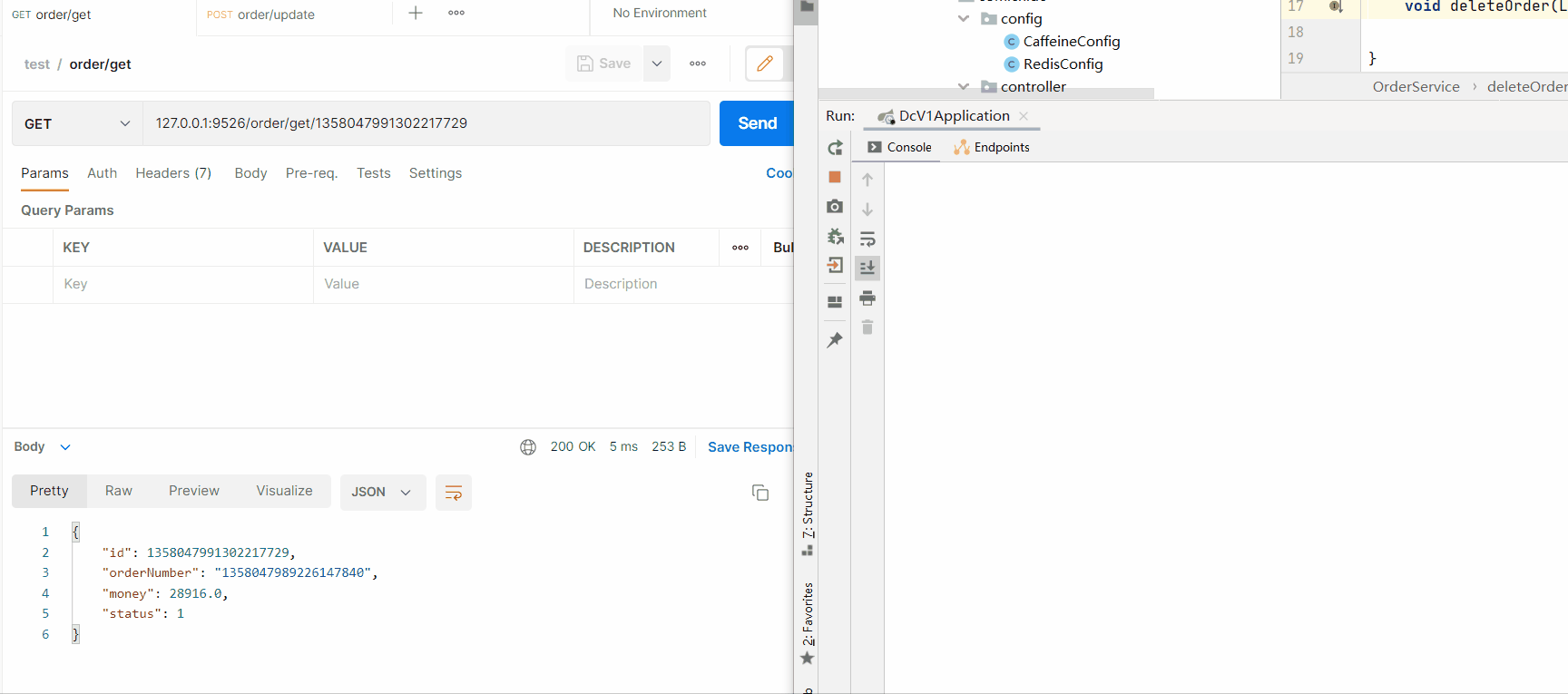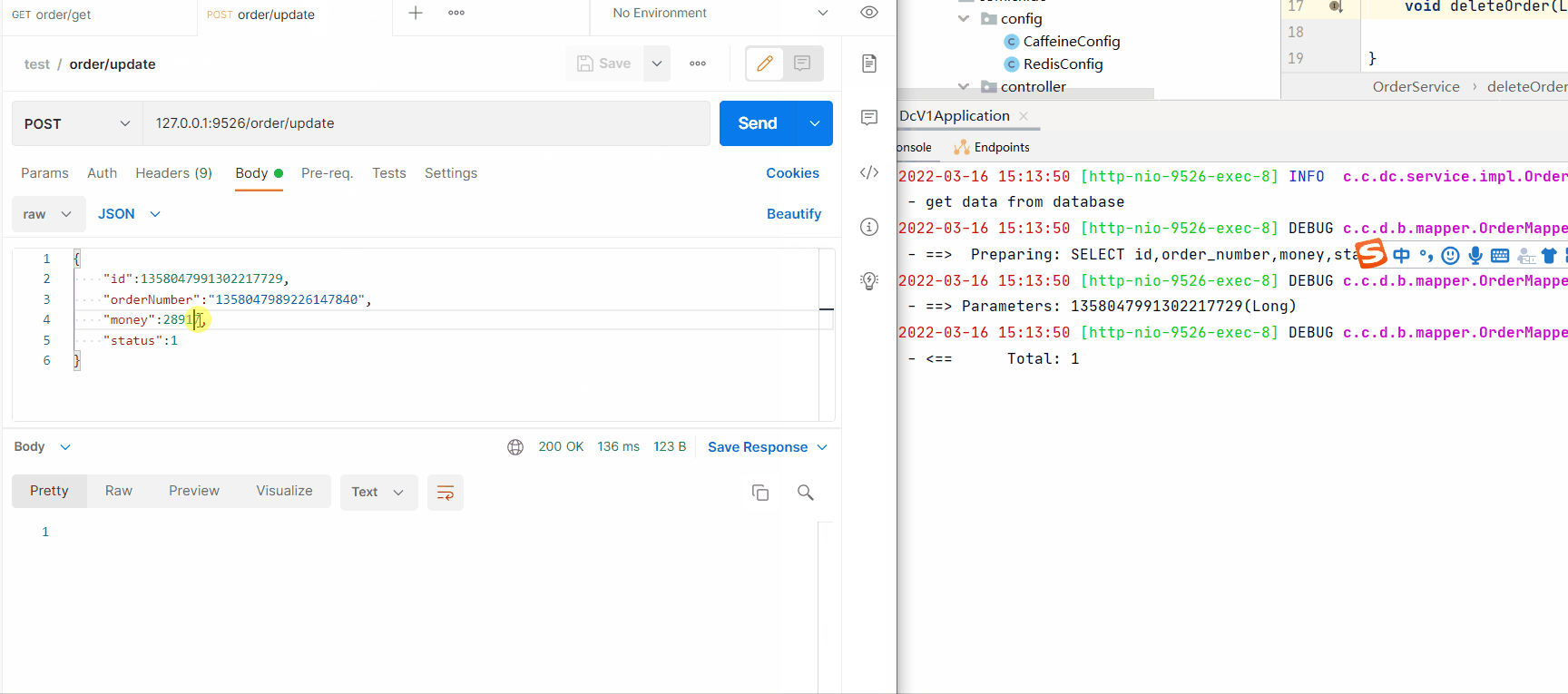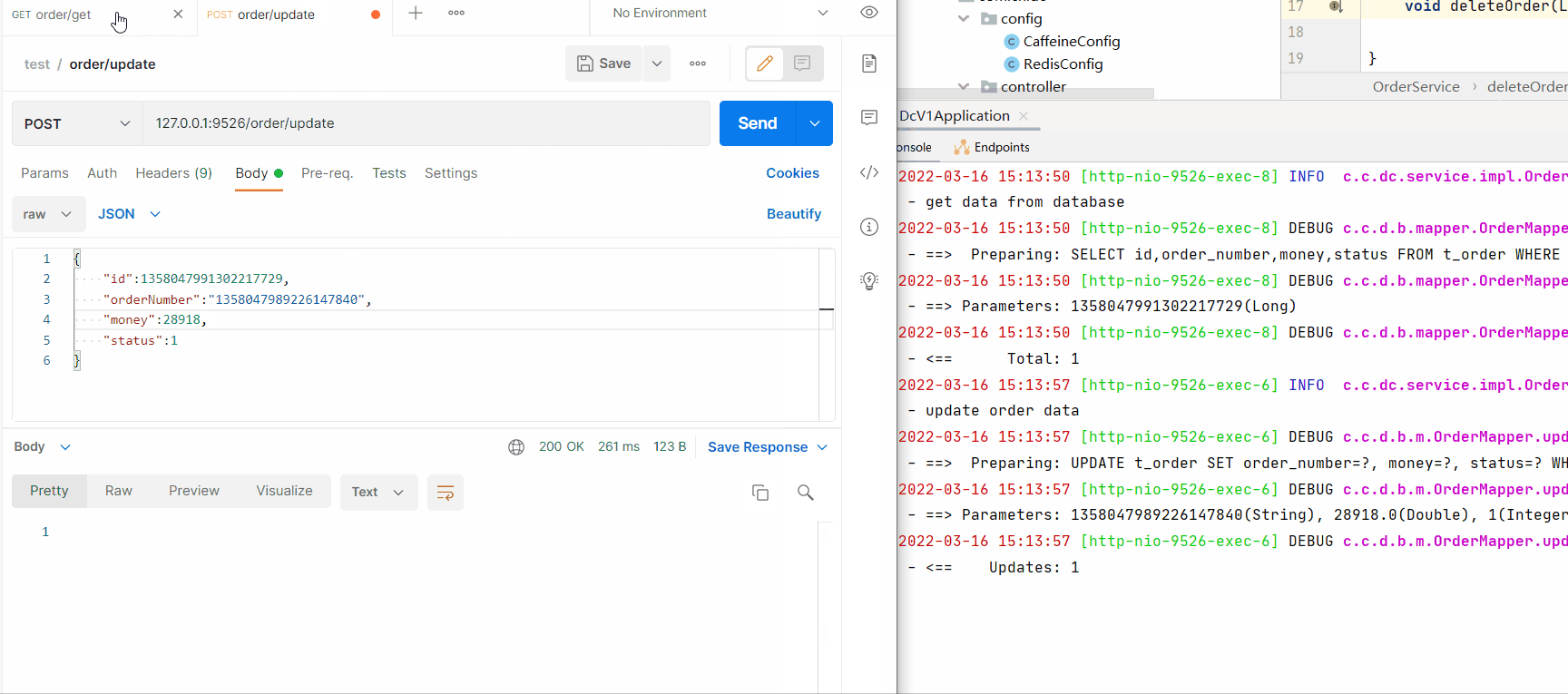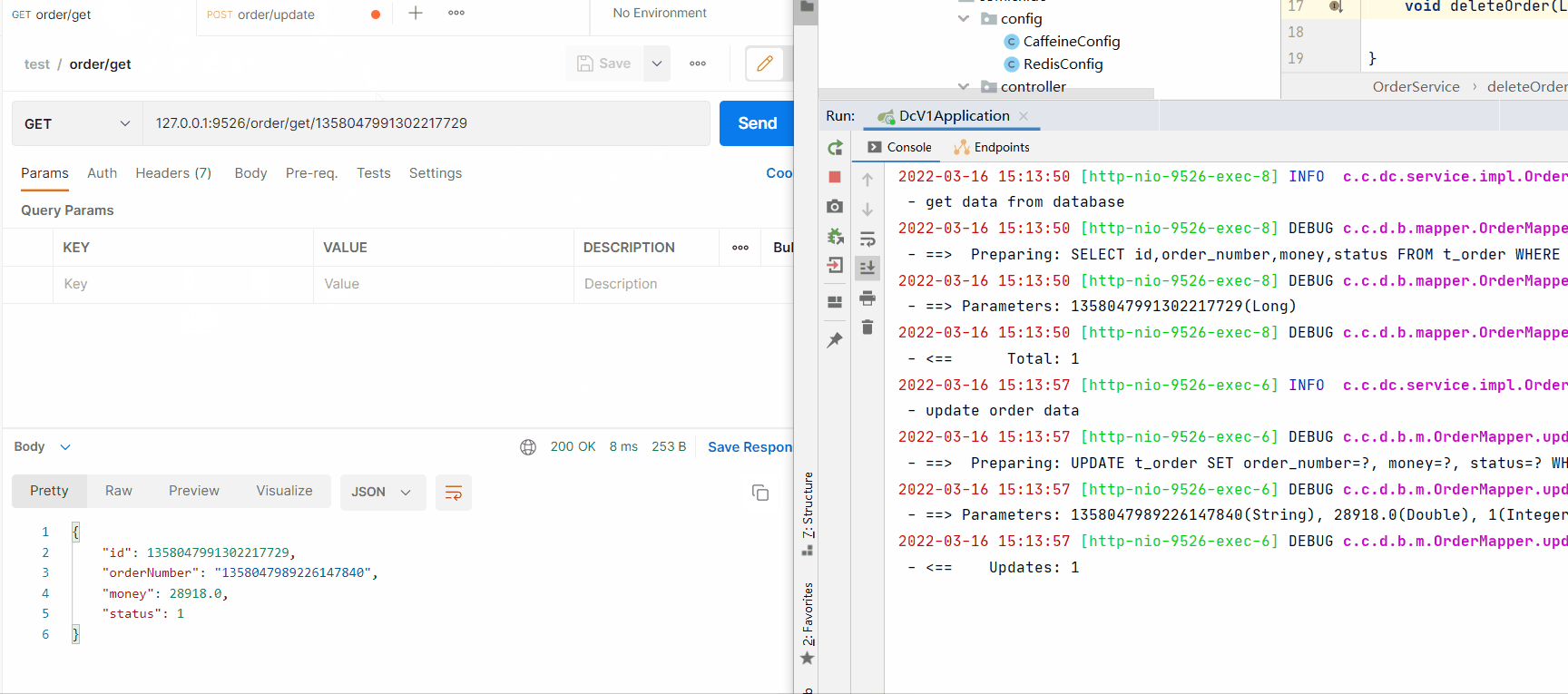
OrderServicepublic Order getOrderById(Long id) {
String key = CacheConstant.ORDER + id;
Order order = (Order) cache.get(key,
k -> {
// First query Redis
Object obj = redisTemplate.opsForValue().get(k);
if (Objects.nonNull(obj)) {
log.info("get data from redis");
return obj;
}
// Redis If not, query DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(k, myOrder, 120, TimeUnit.SECONDS);
return myOrder;
});
return order;
}
CachegetCaffeineRedisRedisRedisCaffeinegetCaffeineRedis
RedisCaffeine
RedisCaffeineRedisRedisCaffeinepublic void updateOrder(Order order) {
log.info("update order data");
String key=CacheConstant.ORDER + order.getId();
orderMapper.updateById(order);
// modify Redis
redisTemplate.opsForValue().set(key,order,120, TimeUnit.SECONDS);
// Modify local cache
cache.put(key,order);
}
ReidsCaffeinepublic void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
String key= CacheConstant.ORDER + id;
redisTemplate.delete(key);
cache.invalidate(key);
}

V2.0 edition
springCacheManager@Cacheable: Take value from cache according to key , If the cache exists , After the cache is successfully obtained , Directly return the cached results . If the cache does not exist , Then the execution method , And put the results in the cache .
@CachePut: Regardless of whether the cache corresponding to the previous key exists , All execution methods , And force the results into the cache
@CacheEvict: After executing the method , Will remove the data from the cache .
CacheBeanspringCacheManager@Configuration
public class CacheManagerConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager=new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.initialCapacity(128)
.maximumSize(1024)
.expireAfterWrite(60, TimeUnit.SECONDS));
return cacheManager;
}
}
@EnableCachingCaffeineService@Cacheable@Cacheable(value = "order",key = "#id")
//@Cacheable(cacheNames = "order",key = "#p0")
public Order getOrderById(Long id) {
String key= CacheConstant.ORDER + id;
// First query Redis
Object obj = redisTemplate.opsForValue().get(key);
if (Objects.nonNull(obj)){
log.info("get data from redis");
return (Order) obj;
}
// Redis If not, query DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(key,myOrder,120, TimeUnit.SECONDS);
return myOrder;
}
@CacheablevaluecacheNamesCachecacheNameCachecacheNameCachevaluecacheNamesCachekeykeySpringELkey# Parameter name
# Parameter object . Property name
#p The parameter corresponds to the subscript
@CacheableRedisCaffeine@CachePutCache@CachePut(cacheNames = "order",key = "#order.id")
public Order updateOrder(Order order) {
log.info("update order data");
orderMapper.updateById(order);
// modify Redis
redisTemplate.opsForValue().set(CacheConstant.ORDER + order.getId(),
order, 120, TimeUnit.SECONDS);
return order;
}
voidkeyRedis@CacheEvictRedis@CacheEvict(cacheNames = "order",key = "#id")
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
redisTemplate.delete(CacheConstant.ORDER + id);
}
springCacheManagerCachespringRedisV3.0 edition
spring@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DoubleCache {
String cacheName();
String key(); // Support springEl expression
long l2TimeOut() default 120;
CacheType type() default CacheType.FULL;
}
cacheName + keykeyCacheCacheNamel2TimeOutRedistypepublic enum CacheType {
FULL, // access
PUT, // Only exist
DELETE // Delete
}
keyspringElpublic static String parse(String elString, TreeMap<String,Object> map){
elString=String.format("#{%s}",elString);
// Create an expression parser
ExpressionParser parser = new SpelExpressionParser();
// adopt evaluationContext.setVariable Variables can be set in context .
EvaluationContext context = new StandardEvaluationContext();
map.entrySet().forEach(entry->
context.setVariable(entry.getKey(),entry.getValue())
);
// Analytic expression
Expression expression = parser.parseExpression(elString, new TemplateParserContext());
// Use Expression.getValue() Get the value of the expression , Here comes Evaluation Context
String value = expression.getValue(context, String.class);
return value;
}
elStringkeymappublic void test() {
String elString="#order.money";
String elString2="#user";
String elString3="#p0";
TreeMap<String,Object> map=new TreeMap<>();
Order order = new Order();
order.setId(111L);
order.setMoney(123D);
map.put("order",order);
map.put("user","Hydra");
String val = parse(elString, map);
String val2 = parse(elString2, map);
String val3 = parse(elString3, map);
System.out.println(val);
System.out.println(val2);
System.out.println(val3);
}
123.0
Hydra
null
CacheCacheCaffeineRedisTemplateRedis@Slf4j @Component @Aspect
@AllArgsConstructor
public class CacheAspect {
private final Cache cache;
private final RedisTemplate redisTemplate;
@Pointcut("@annotation(com.cn.dc.annotation.DoubleCache)")
public void cacheAspect() {
}
@Around("cacheAspect()")
public Object doAround(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
// Splicing analysis springEl Of expression map
String[] paramNames = signature.getParameterNames();
Object[] args = point.getArgs();
TreeMap<String, Object> treeMap = new TreeMap<>();
for (int i = 0; i < paramNames.length; i++) {
treeMap.put(paramNames[i],args[i]);
}
DoubleCache annotation = method.getAnnotation(DoubleCache.class);
String elResult = ElParser.parse(annotation.key(), treeMap);
String realKey = annotation.cacheName() + CacheConstant.COLON + elResult;
// Force update
if (annotation.type()== CacheType.PUT){
Object object = point.proceed();
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
cache.put(realKey, object);
return object;
}
// Delete
else if (annotation.type()== CacheType.DELETE){
redisTemplate.delete(realKey);
cache.invalidate(realKey);
return point.proceed();
}
// Reading and writing , Inquire about Caffeine
Object caffeineCache = cache.getIfPresent(realKey);
if (Objects.nonNull(caffeineCache)) {
log.info("get data from caffeine");
return caffeineCache;
}
// Inquire about Redis
Object redisCache = redisTemplate.opsForValue().get(realKey);
if (Objects.nonNull(redisCache)) {
log.info("get data from redis");
cache.put(realKey, redisCache);
return redisCache;
}
log.info("get data from database");
Object object = point.proceed();
if (Objects.nonNull(object)){
// write in Redis
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
// write in Caffeine
cache.put(realKey, object);
}
return object;
}
}
- Through the parameters of the method , Parsing comments
keyOfspringElexpression , Assemble the real cachekey
- Depending on the type of operation cache , Handle access separately 、 Only exist 、 Delete cache operation
- Delete and force update of cache , All need to execute the original method , And perform corresponding cache deletion or update operations
- Before access , First check if there is data in the cache , Direct return if any , If not, execute the original method , And cache the results
Service@DoubleCache(cacheName = "order", key = "#id",
type = CacheType.FULL)
public Order getOrderById(Long id) {
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return myOrder;
}
@DoubleCache(cacheName = "order",key = "#order.id",
type = CacheType.PUT)
public Order updateOrder(Order order) {
orderMapper.updateById(order);
return order;
}
@DoubleCache(cacheName = "order",key = "#id",
type = CacheType.DELETE)
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
Servicesummary
Manongshen 边栏推荐
- 降低pip到指定版本(通過PyCharm昇級pip,在降低到原來版本)
- Multi task model of recommended model: esmm, MMOE
- How to resolve the 35 year old crisis? Sharing of 20 years' technical experience of chief architect of Huawei cloud database
- Transport layer UDP & TCP
- Graduation summary of phase 6 of the construction practice camp
- 基于 KubeSphere 的分级管理实践
- Multithreaded finalization
- Prompt that the device has no permission when using ADB to connect to the device
- Excel layout
- leetcode_1365
猜你喜欢

Installing Oracle without graphical interface in virtual machine centos7 (nanny level installation)
![[camera Foundation (II)] camera driving principle and Development & v4l2 subsystem driving architecture](/img/b5/23e3aed317ca262ebd8ff4579a41a9.png)
[camera Foundation (II)] camera driving principle and Development & v4l2 subsystem driving architecture

EasyBypass

传输层 udp && tcp

Blender FAQs

权限想要细化到按钮,怎么做?

SAP接口debug设置外部断点

煮茶论英雄!福建省发改委、市营商办领导一行莅临育润大健康事业部交流指导

Why are life science enterprises on the cloud in succession?

Multi task model of recommended model: esmm, MMOE
随机推荐
机器学习:梯度下降法
滤波数据分析
How to resolve the 35 year old crisis? Sharing of 20 years' technical experience of chief architect of Huawei cloud database
即构「畅直播」上线!提供全链路升级的一站式直播服务
LeetCode-513. 找树左下角的值
CV2 package guide times could not find a version that satisfies the requirement CV2 (from versions: none)
(待补充)GAMES101作业7提高-实现微表面模型你需要了解的知识
福建省发改委福州市营商办莅临育润大健康事业部指导视察工作
socket(2)
煮茶论英雄!福建省发改委、市营商办领导一行莅临育润大健康事业部交流指导
Datakit 代理实现局域网数据统一汇聚
leetcode1863_2021-10-14
Introduce the overall process of bootloader, PM, kernel and system startup
降低pip到指定版本(通过PyCharm升级pip,在降低到原来版本)
A deep learning model for urban traffic flow prediction with traffic events mined from twitter
Implementation of adjacency table storage array of graph
leetcode-201_2021_10_17
Make tea and talk about heroes! Leaders of Fujian Provincial Development and Reform Commission and Fujian municipal business office visited Yurun Health Division for exchange and guidance
[精选] 多账号统一登录,你如何设计?
[notes of Wu Enda] multivariable linear regression