当前位置:网站首页>一篇文章教会你使用Python网络爬虫下载酷狗音乐
一篇文章教会你使用Python网络爬虫下载酷狗音乐
2020-11-06 20:53:00 【Python进阶者】
【一、项目背景】
现在的听歌软件动不动就是各种付费,要下载软件才能听,当你下载了之后,你会惊奇的发现这首歌还收费,这就让一向喜欢白嫖的小编感到很伤心了。于是,小编冥思苦想,终于让我发现了其中的奥秘,一起来看看吧。
【二、项目准备】
1、编辑器:Sublime Text 3
2、软件:360浏览器
【三、项目目标】
下载我们喜欢的音乐。
【四、项目实现】
1、打开酷狗音乐官网
360浏览器打开酷狗音乐官网:

可以看到十分清爽的画风,这也是我比较喜欢的地方。
2、审查元素,分析请求
打开Network ,分析请求,我们可以看到:

从上图可以看出,这是请求的参数,所以我们可以使用Requests模块对它发起请求。
3、模拟发起请求
我们从网页中得知它的地址为:
https://www.kugou.com/yy/html/search.html#searchType=song&searchKeyWord=%E4%B8%8D%E8%B0%93%E4%BE%A0
可以看到真正对于我们来说有用的就只有SearchKeyWord参数后的值,前面的搜索类型默认填写即可,所以我们可以这样:
import requests
headers={
'accept': '*/*',
'accept-encoding':'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'kg_mid=ebb2de813317a791bcf7b7d3131880c4; UM_distinctid=1722ba8b22632d-07ac0227c507a7-4e4c0f20-1fa400-1722ba8b2284a1; kg_dfid=0Q0BEI47P4zf0mHYzV0SYbou; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1590041687,1590280210,1590367138,1590367386; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1590367431',
'referer': 'https://www.kugou.com/yy/html/search.html',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
aa=input('请输入歌名:')
data={
'callback': 'jQuery112408716317197794392_1590368232677',
'keyword':aa,
'page': '1',
'pagesize':'30',
'userid':'-1',
'clientver': '',
'platform': 'WebFilter',
'tag': 'em',
'filter': '2',
'iscorrection': '1',
'privilege_filter': '0',
'_': '1590368232679',
}
requests.get('https://www.kugou.com/yy/html/search.html',params=data,timeout=4)
这样就实现了模拟请求,我们来验证下:

可以看出它成功打印出了和我们上面一模一样的地址。
4、获取音乐文件列表
rep=requests.get('https://www.kugou.com/yy/html/search.html',params=data,timeout=5)
print(rep.url)
res=requests.get(rep.url,timeout=4)
print(res.text)
当我们将请求地址填写正确后,我发现竟然内容与预期不相符,但是请求地址对的一批。
我以为是这样的结果:
实际上的结果:

可以看到差距很大,而且用Json也根本获取不到,报格式错误,说明不是一个Json,看来这比QQ音乐难度高点。不过我们今天要下载的是音频文件,所以暂时跳过,不管它。
5、下载音频文件
我们在搜索后弹出来的列表中选择原唱曲目,进去听一下:
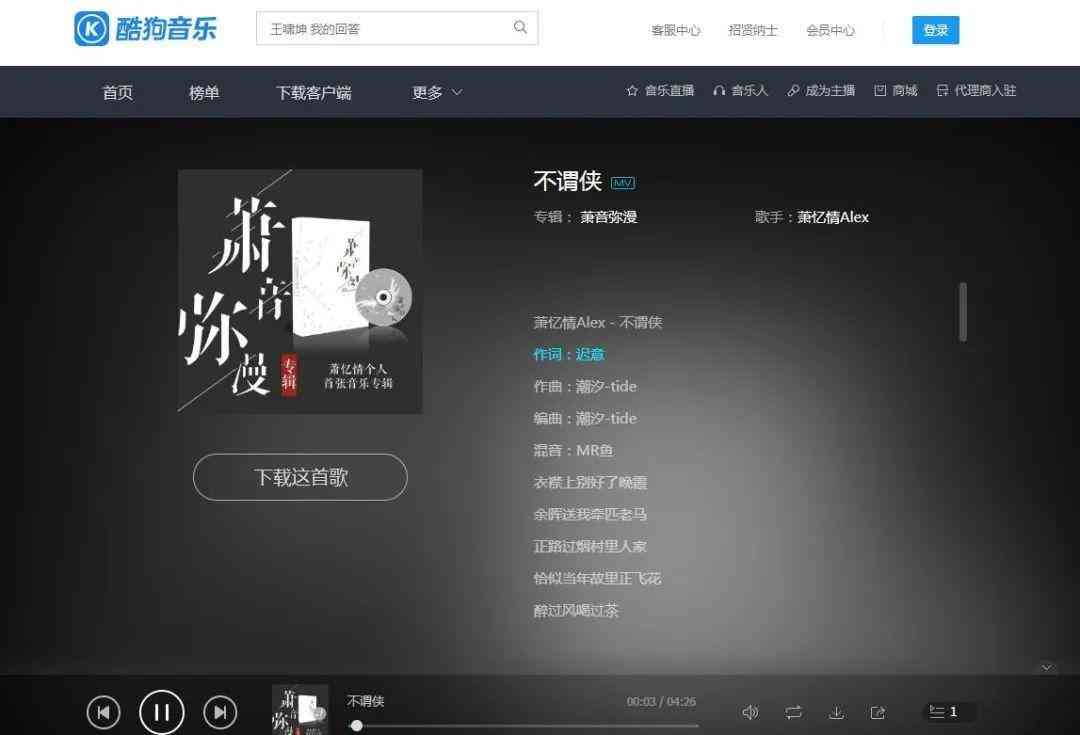
我选择第一首,打开是这样,我们开始骚操作,打开Network:

我们输入后缀Mp3,然后定位到对应的请求,然后打开它的请求结果,可以看到一个Json结果:

我们将Json结果粘贴到控制台,可以看到里面有一段关于Mp3的结果,不过添加了点干扰符号,我们把它提取出来:

这样我们就可以把酷狗音乐的歌曲下载下来了。
【五、项目总结】
1、其实,酷狗音乐与QQ音乐不同,酷狗音乐的下载链接更好捕获,你可以直接在它的播放界面捕获到:

模拟请求这个界面,一切都搞定了。
2、关于QQ音乐的获取,可以参考之前发布的系列文章:
3、需要本文源码的小伙伴,后台回复“酷狗音乐”四个字,即可获取。 想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
版权声明
本文为[Python进阶者]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4521128/blog/4666153
边栏推荐
- Analysis of react high order components
- How long does it take you to work out an object-oriented programming interview question from Ali school?
- Summary of common string algorithms
- Architecture article collection
- Swagger 3.0 天天刷屏,真的香嗎?
- Three Python tips for reading, creating and running multiple files
- Using consult to realize service discovery: instance ID customization
- 6.1.1 handlermapping mapping processor (1) (in-depth analysis of SSM and project practice)
- Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)
- Using Es5 to realize the class of ES6
猜你喜欢

小程序入门到精通(二):了解小程序开发4个重要文件
合约交易系统开发|智能合约交易平台搭建

Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)

This article will introduce you to jest unit test
Mongodb (from 0 to 1), 11 days mongodb primary to intermediate advanced secret

NLP model Bert: from introduction to mastery (1)
一篇文章带你了解CSS 分页实例
![[C / C + + 1] clion configuration and running C language](/img/5b/ba96ff4447b150f50560e5d47cb8d1.jpg)
[C / C + + 1] clion configuration and running C language

How to use Python 2.7 after installing anaconda3?

Existence judgment in structured data
随机推荐
Three Python tips for reading, creating and running multiple files
Aprelu: cross border application, adaptive relu | IEEE tie 2020 for machine fault detection
Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!
PHP应用对接Justswap专用开发包【JustSwap.PHP】
Python download module to accelerate the implementation of recording
NLP model Bert: from introduction to mastery (1)
至联云分享:IPFS/Filecoin值不值得投资?
Face to face Manual Chapter 16: explanation and implementation of fair lock of code peasant association lock and reentrantlock
Programmer introspection checklist
如何玩转sortablejs-vuedraggable实现表单嵌套拖拽功能
Let the front-end siege division develop independently from the back-end: Mock.js
100元扫货阿里云是怎样的体验?
[C / C + + 1] clion configuration and running C language
How to select the evaluation index of classification model
Electron application uses electronic builder and electronic updater to realize automatic update
Common algorithm interview has been out! Machine learning algorithm interview - KDnuggets
[event center azure event hub] interpretation of error information found in event hub logs
一篇文章教会你使用HTML5 SVG 标签
Brief introduction of TF flags
Swagger 3.0 天天刷屏,真的香嗎?