当前位置:网站首页>MapReduce初级编程实践
MapReduce初级编程实践
2022-06-27 19:57:00 【wr456wr】
实验环境
- ubuntu18.04虚拟机和一个win10物理主机
- 编程环境 IDEA
- 虚拟机ip:192.168.1.108
- JDK:1.8
实验内容
使用Java编程一个WordCount程序,并将该程序打包成Jar包在虚拟机内执行
首先使用IDEA创建一个Maven项目
在pom.xml文件内引入依赖和打包为Jar包的插件:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>2.4.11</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.11</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>2.4.11</version>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.MyProgramDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
编写对应的程序:
MyProgramDriver类用于执行程序入口:
import org.apache.hadoop.util.ProgramDriver;
public class MyProgramDriver {
public static void main(String[] args) {
int exitCode = -1;
ProgramDriver programDriver = new ProgramDriver();
try {
programDriver.addClass("com.WordCount", WordCount.class, "com.WordCount Program");
exitCode = programDriver.run(args);
} catch (Throwable e) {
throw new RuntimeException(e);
}
System.exit(exitCode);
}
}
;
WordCount程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator var5 = values.iterator(); var5.hasNext(); sum += val.get()) {
val = (IntWritable)var5.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
;
项目结构截图: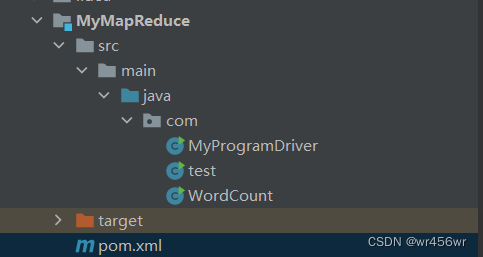
在右侧点击maven的package进行项目打包为Jar文件
打包完成后的打包文件在target目录下
之后将打包好的Jar包发送到虚拟机内,我是放在/root/hadoop/a_dir目录下,放在哪随意,但自己要知道在哪
;
然后编写输入文件input1和input2,内容分别为:
然后将两个文件上传到hadoop的系统路径,这里我放在了hadoop的/root/input目录下,注意不是物理路径,是Hadoop启动后的网络路径
;
之后执行程序:
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar com.WordCount /root/input/* /root/out
其中a_dir/MyMapReduce-1.0-SNAPSHOT.jar是需要执行的Jar包的路径,com.WordCount是需要执行的WordCount程序名称,这个名称就是在MyProgramDriver内注明的名称

/root/input/* 是输入的文件, /root/out是输出路径
;
查看输出:
编程实现文件合并和去重操作
输入样例:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
主要思想:使用map将文件的每一行使用正则拆分为key,value ,如将20150101 x拆分后的key为20150101,value为x,类型为Text类型,将map处理后的由shuffle处理送往reduce进行处理,在reduce内使用HashSet的去重特性(在HashSet内的元素不重复)对输入的值进行去重。
;
Merge程序代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
public class Merge {
public Merge() {
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: merge <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "merge");
job.setJarByClass(Merge.class);
job.setMapperClass(Merge.MyMapper.class);
job.setCombinerClass(Merge.MyReduce.class);
job.setReducerClass(Merge.MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class MyMapper extends Mapper<Object, Text, Text, Text> {
public MyMapper() {
}
@Override
public void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String line = value.toString();
//匹配空白符
String[] split = line.split("\\s+");
if (split.length <= 1) {
return;
}
context.write(new Text(split[0]), new Text(split[1]));
}
}
public static class MyReduce extends Reducer<Text, Text, Text, Text> {
public MyReduce() {
}
@Override
public void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
//使用HashSet进行去重操作
HashSet<String> hashSet = new HashSet<>();
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()) {
hashSet.add(iterator.next().toString());
}
Iterator<String> hashIt = hashSet.iterator();
while (hashIt.hasNext()) {
Text val = new Text(hashIt.next());
context.write(key, val);
}
}
}
}
将Merge程序写入MyProgramDriver类:
import org.apache.hadoop.util.ProgramDriver;
public class MyProgramDriver {
public static void main(String[] args) {
int exitCode = -1;
ProgramDriver programDriver = new ProgramDriver();
try {
programDriver.addClass("com.WordCount", WordCount.class, "com.WordCount Program");
programDriver.addClass("Merge", Merge.class, "xll");
exitCode = programDriver.run(args);
} catch (Throwable e) {
throw new RuntimeException(e);
}
System.exit(exitCode);
}
}
将程序打包后发送到虚拟机,运行程序:
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar Merge /root/input/* /root/out
运行结果:
编程实现对输入文件的排序
思路:在Map端将数值分离出来形成<key,1>这样的键值对,由于排序是MapReduce的默认操作,所以在Reduce端只需要将Map端分离出来的值进行输出就行,将Map端的key值设置为Reduce端的value值。
MyConf类代码:
这里我将一般需要进行的配置提取出来了,减少以后一下代码的重复
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class MyConf {
public static void setConf(Class mainClass,Class outKeyClass, Class outValueClass, String[] args) throws IOException, InterruptedException, ClassNotFoundException, InstantiationException, IllegalAccessException {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("otherArgs length error, length < 2");
System.exit(2);
}
Job job = Job.getInstance(conf, mainClass.getName());
Class[] innerClass = mainClass.getClasses();
for (Class c : innerClass) {
if (c.getSimpleName().equals("MyReduce")) {
job.setReducerClass(c);
// job.setCombinerClass(c);
} else if (c.getSimpleName().equals("MyMapper")) {
job.setMapperClass(c);
}
}
job.setJarByClass(mainClass);
job.setOutputKeyClass(outKeyClass);
job.setOutputValueClass(outValueClass);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
;
Sort类:
import com.utils.MyConf;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class Sort {
public Sort() {
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, InstantiationException, IllegalAccessException {
MyConf.setConf(Sort.class, IntWritable.class, IntWritable.class, args);
}
public static class MyMapper extends Mapper<Object, org.apache.hadoop.io.Text, IntWritable, IntWritable> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException {
String var = value.toString();
context.write(new IntWritable(Integer.parseInt(var.trim())), new IntWritable(1));
}
}
public static class MyReduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
static int sort = 1;
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException {
for (IntWritable va : values) {
context.write(new IntWritable(sort), key);
sort++;
}
}
}
}
然后再将Sort类注入MyProgramDriver类就可以了
程序的输入:
打包后放在虚拟机运行
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar Sort /root/input* /root/out5
运行结果:
对给定的表格进行信息挖掘
思路:(参考),举个例子:
steven lucy
lucy mary
这个输入在经过map(map的具体逻辑参考下面的代码)出来后得到输出:
<steven,old#lucy>,<lucy,young#steven>,<lucy,old#mary>,<mary,young#lucy>,
之后经过shuffle处理之后得到输入:
<steven,old#lucy>,<lucy,<young#steven,old#mary>>,<mary,young#lucy>,
之后每个键值对作为Reduce端的输入
<lucy,<young#steven,old#mary>>键值对在经过reduce的逻辑处理后得到一个有效输出:
<steven, mary>
InfoFind类:
package com;
import com.utils.MyConf;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
public class InfoFind {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, InstantiationException, IllegalAccessException {
MyConf.setConf(InfoFind.class, Text.class, Text.class, args);
}
public static class MyMapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] splStr = value.toString().split("\\s+");
String child = splStr[0];
String parent = splStr[1];
if (child.equals("child") && parent.equals("parent"))
return;
context.write(new Text(child), new Text("old#" + parent));
context.write(new Text(parent), new Text("young#" + child));
}
}
public static class MyReduce extends Reducer<Text, Text, Text, Text> {
private static boolean head = true ;
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException
{
if(head)
{
context.write(new Text("grandchild"), new Text("grandparent"));
head = false;
}
ArrayList<String> grandchild = new ArrayList<>();
ArrayList<String> grandparent = new ArrayList<>();
String[] temp;
for(Text val:values)
{
temp = val.toString().split("#");
if(temp[0].equals("young"))
grandchild.add(temp[1]);
else
grandparent.add(temp[1]);
}
for(String gc:grandchild)
for(String gp:grandparent)
context.write(new Text(gc), new Text(gp));
}
}
}
输入:
运行:
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar InfoFind /root/input/* /root/out6
输出:
参考资料
https://blog.csdn.net/u013384984/article/details/80229459 (一个重点内容)
https://blog.csdn.net/qq_43310845/article/details/123298811
https://blog.csdn.net/zhangwenbingbingyu/article/details/52210348
https://www.cnblogs.com/ginkgo-/p/13273671.html
边栏推荐
- Workflow automation low code is the key
- Penetration learning - shooting range chapter - detailed introduction to Pikachu shooting range (under continuous update - currently only the SQL injection part is updated)
- PHP connects to database to realize user registration and login function
- 网易云“情怀”底牌失守
- Redis principle - string
- Follow the archiving tutorial to learn rnaseq analysis (III): count standardization using deseq2
- Using the cucumber automated test framework
- Macro task and micro task understanding
- Where can I set the slides on the front page of CMS applet?
- Yarn performance tuning of CDH cluster
猜你喜欢

Workflow automation low code is the key

average-population-of-each-continent

信通院举办“业务与应用安全发展论坛” 天翼云安全能力再获认可

Spark BUG实践(包含的BUG:ClassCastException;ConnectException;NoClassDefFoundError;RuntimeExceptio等。。。。)

初识C语言 第二弹

Livox lidar+ Hikvision camera real-time 3D reconstruction based on loam to generate RGB color point cloud

About the SQL injection of davwa, errors are reported: analysis and verification of the causes of legal mix of settlements for operation 'Union'
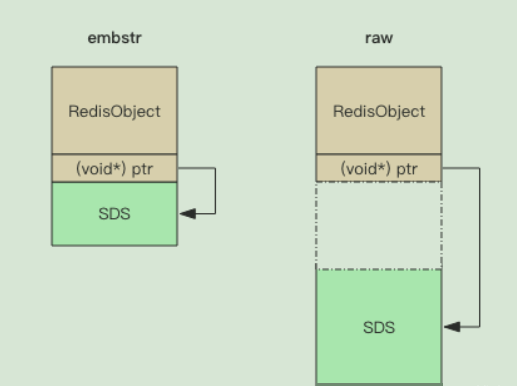
Redis principle - string
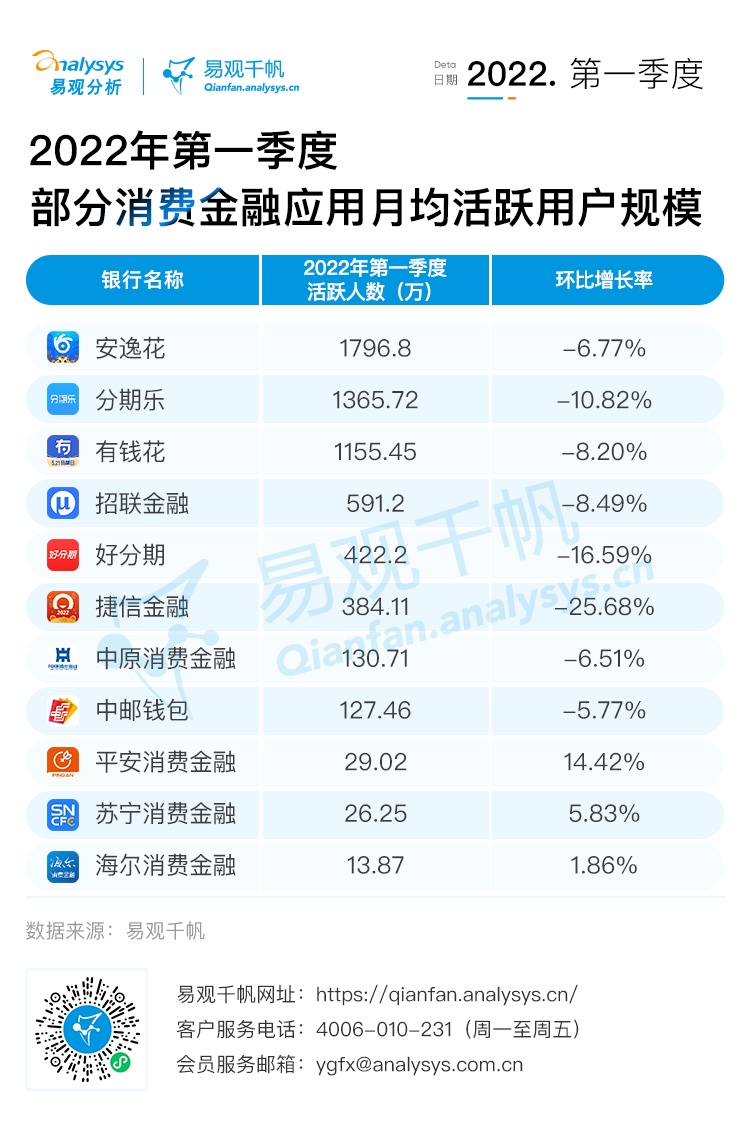
Consumer finance app user insight in the first quarter of 2022 - a total of 44.79 million people

资深猎头团队管理者:面试3000顾问,总结组织出8大共性(茅生)
随机推荐
How to participate in openharmony code contribution
Open source of local run / development library of hiplot online drawing tool
游戏手机平台简单介绍
Improving deep neural networks: hyperparametric debugging, regularization and optimization (III) - hyperparametric debugging, batch regularization and program framework
[suggested collection] ABAP essays-excel-4-batch import recommended
「R」使用ggpolar绘制生存关联网络图
对话乔心昱:用户是魏牌的产品经理,零焦虑定义豪华
PHP连接数据库实现用户注册登录功能
Use logrotate to automatically cut the website logs of the pagoda
Character interception triplets of data warehouse: substrb, substr, substring
Livox lidar+ Haikang camera generates color point cloud in real time
宏任务、微任务理解
netERR_CONNECTION_REFUSED 解决大全
Personal tree ALV template - accelerate your development
[cloud based co creation] what is informatization? What is digitalization? What are the connections and differences between the two?
月薪3万的狗德培训,是不是一门好生意?
Record a list object traversal and determine the size of the float type
Introduce you to ldbc SNB, a powerful tool for database performance and scenario testing
mongodb基础操作之聚合操作、索引优化
Penetration learning - shooting range chapter - detailed introduction to Pikachu shooting range (under continuous update - currently only the SQL injection part is updated)