当前位置:网站首页>AGCO AI frontier promotion (6.23)
AGCO AI frontier promotion (6.23)
2022-06-23 13:21:00 【Zhiyuan community】
LG - machine learning CV - Computer vision CL - Computing and language AS - Audio and voice RO - robot
Turn from love to a lovely life
Abstract : Language driven context image synthesis for object detection 、 Images GAN Non Lambert reverse rendering 、 Rethinking 3D GAN Training for 、 When reinitialization is effective 、 free ( authentication ) Against robustness 、 Large language model planning and reasoning benchmark about change 、 Self monitoring block embedded in bag 、 Global context vision Transformer、 For driverless 3D A survey of target detection
1、[CV] DALL-E for Detection: Language-driven Context Image Synthesis for Object Detection
Y Ge, J Xu, B N Zhao, L Itti, V Vineet
[University of Southern California & Microsoft Research]
DALL-E testing : Language driven context image synthesis for object detection . Cutting and pasting objects has become a promising method , It can effectively generate a large number of labeled training data . It involves compositing the foreground object mask onto the background image . When the background image matches the object , Provide useful context information for training target recognition model . Although this method can easily generate a large amount of tag data , But finding a consistent context image for downstream tasks is still a difficult problem . This paper proposes a new paradigm for automatically generating context images on a large scale . Its core is the interaction between language description of context and language driven image generation . The language description of the context is provided by applying the image description method to a small part of the image representing the context . then , These language descriptions are used in language based DALL-E Image generation framework to generate different context image sets . Then combine these images with the object , Provide an enhanced training set for the classifier . The advantages of the proposed method over the previous context image generation method are proved on four target detection data sets . This paper also emphasizes the compositional properties of the data generation method in out of distribution and zero sample data generation scenarios .
Object cut-and-paste has become a promising approach to efficiently generate large sets of labeled training data. It involves compositing foreground object masks onto background images. The background images, when congruent with the objects, provide helpful context information for training object recognition models. While the approach can easily generate large labeled data, finding congruent context images for downstream tasks has remained an elusive problem. In this work, we propose a new paradigm for automatic context image generation at scale. At the core of our approach lies utilizing an interplay between language description of context and language-driven image generation. Language description of a context is provided by applying an image captioning method on a small set of images representing the context. These language descriptions are then used to generate diverse sets of context images using the language-based DALL-E image generation framework. These are then composited with objects to provide an augmented training set for a classifier. We demonstrate the advantages of our approach over the prior context image generation approaches on four object detection datasets. Furthermore, we also highlight the compositional nature of our data generation approach on out-of-distribution and zero-shot data generation scenarios.
https://arxiv.org/abs/2206.09592





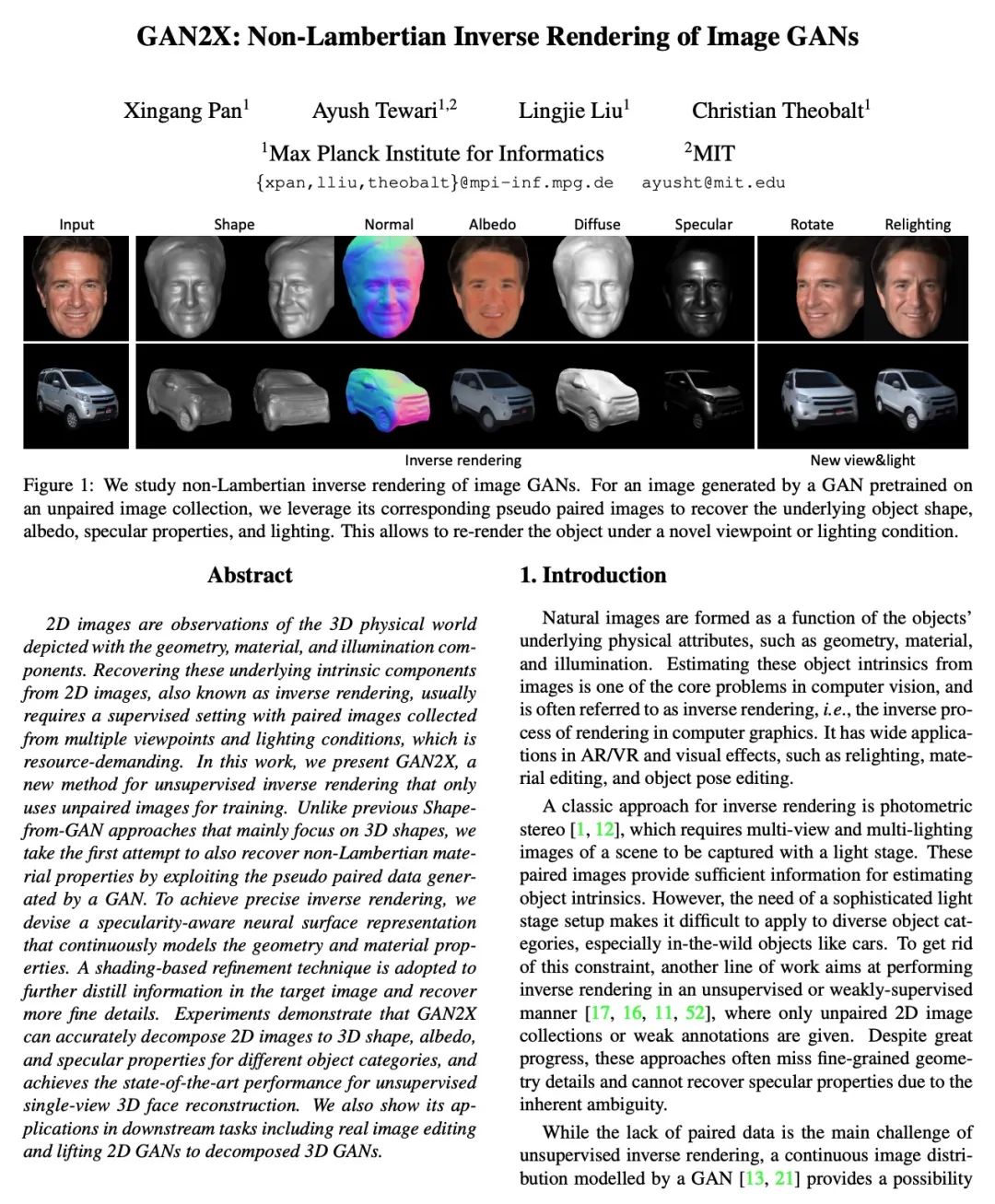
2、[CV] GAN2X: Non-Lambertian Inverse Rendering of Image GANs
X Pan, A Tewari, L Liu, C Theobalt
[Max Planck Institute for Informatics]
GAN2X: Images GAN Non Lambert reverse rendering .2D The image is right 3D Observation of the physical world , It describes geometry 、 Material and light composition . from 2D Recover these potential intrinsic components from the image , Also known as reverse rendering , It is usually necessary to collect a pair of images from multiple perspectives and lighting conditions under supervision , High demand for resources . In this paper, GAN2X, A new method for unsupervised inversion , Only unpaired images are used for training . Compared with the previous main concern 3D The shape of the Shapefrom-GAN The method is different , This paper is the first attempt to use GAN The pseudo pairing data is generated to recover the properties of non Lambert materials . For accurate reverse rendering , This paper designs a high light perception neural surface representation , Continuous modeling of geometry and material properties . A shadow based thinning technique is used to further refine the information in the target image , And restore more fine details . Experiments show that ,GAN2X Can accurately translate 2D Image unwrapping is 3D shape 、 Albedo and specular properties of different objects , And in an unsupervised single view 3D Face reconstruction has achieved the most advanced performance . This paper also shows its application in downstream tasks , Including real image editing and editing 2D GAN Promote to exploded 3D GAN.
2D images are observations of the 3D physical world depicted with the geometry, material, and illumination components. Recovering these underlying intrinsic components from 2D images, also known as inverse rendering, usually requires a supervised setting with paired images collected from multiple viewpoints and lighting conditions, which is resource-demanding. In this work, we present GAN2X, a new method for unsupervised inverse rendering that only uses unpaired images for training. Unlike previous Shapefrom-GAN approaches that mainly focus on 3D shapes, we take the first attempt to also recover non-Lambertian material properties by exploiting the pseudo paired data generated by a GAN. To achieve precise inverse rendering, we devise a specularity-aware neural surface representation that continuously models the geometry and material properties. A shading-based refinement technique is adopted to further distill information in the target image and recover more fine details. Experiments demonstrate that GAN2X can accurately decompose 2D images to 3D shape, albedo, and specular properties for different object categories, and achieves the state-of-the-art performance for unsupervised single-view 3D face reconstruction. We also show its applications in downstream tasks including real image editing and lifting 2D GANs to decomposed 3D GANs.
https://arxiv.org/abs/2206.09244




3、[CV] EpiGRAF: Rethinking training of 3D GANs
I Skorokhodov, S Tulyakov, Y Wang, P Wonka
[KAUST & Snap Inc.]
EpiGRAF: Rethinking 3D GAN Training for . A recent trend in Generative modeling , It's from 2D Image set 3D Perception generator . In order to sum up 3D deviation , This model usually relies on volume rendering , This kind of rendering is expensive at high resolution . In the past few months , There is 10 Multiple jobs , By training a single 2D The decoder pair consists of pure 3D Low resolution images generated by the generator ( Or characteristic tensor ) Upsampling is performed to solve the expansion problem . But this solution comes at a price : It not only destroys the consistency of multiple views ( That is, when the camera moves , Shapes and textures change ), We also learn geometry with low fidelity . It is possible for this civilization to follow a completely different route , That is, simply train the model block by block , To get one with SotA High resolution of image quality 3D generator . This paper reexamines and improves this optimization scheme in two ways . First , A position and scale perceptual discriminator is designed , So as to work on blocks with different scales and spatial positions . secondly , Modified based on annealing β Distributed block sampling strategy , To stabilize training and accelerate convergence . The resulting model , namely EpiGRAF, It's efficient 、 high resolution 、 pure 3D generator , stay 256 and 512 The resolution is tested on four data sets . It achieves the most advanced image quality 、 High fidelity Geometry , And more than based on upsampler The training speed of similar products is fast ≈2.5 times .
A very recent trend in generative modeling is building 3D-aware generators from 2D image collections. To induce the 3D bias, such models typically rely on volumetric rendering, which is expensive to employ at high resolutions. During the past months, there appeared more than 10 works that address this scaling issue by training a separate 2D decoder to upsample a low-resolution image (or a feature tensor) produced from a pure 3D generator. But this solution comes at a cost: not only does it break multi-view consistency (i.e. shape and texture change when the camera moves), but it also learns the geometry in a low fidelity. In this work, we show that it is possible to obtain a high-resolution 3D generator with SotA image quality by following a completely different route of simply training the model patch-wise. We revisit and improve this optimization scheme in two ways. First, we design a locationand scale-aware discriminator to work on patches of different proportions and spatial positions. Second, we modify the patch sampling strategy based on an annealed beta distribution to stabilize training and accelerate the convergence. The resulted model, named EpiGRAF, is an efficient, high-resolution, pure 3D generator, and we test it on four datasets (two introduced in this work) at 256 and 512 resolutions. It obtains state-of-the-art image quality, high-fidelity geometry and trains ≈2.5× faster than the upsampler-based counterparts. Code/data/visualizations: https://universome.github.io/epigraf
https://arxiv.org/abs/2206.10535





4、[LG] When Does Re-initialization Work?
S Zaidi, T Berariu, H Kim, J Bornschein, C Clopath, Y W Teh, R Pascanu
[University of Oxford & Imperial College London & DeepMind]
When reinitialization is effective ? In recent work , It has been observed that reinitializing neural networks during training can improve generalization ability . However , It is not widely used in deep learning practice , Nor is it often used in the most advanced training programs . This raises a question : When reinitialization is effective , And whether it should be associated with data enhancement 、 Weight attenuation is used together with regularization techniques such as learning rate planning . This paper makes an extensive empirical comparison between standard training and selected reinitialization methods , To answer this question , More than... Are trained on various image classification benchmarks 15000 A model . First determine , Without any other regularization , These methods always facilitate generalization . However , When deployed with other carefully tuned regularization techniques , The reinitialization method offers few additional benefits for generalization , Although the optimal generalization performance becomes less sensitive to the selection of learning rate and weight decay superparameters . In order to study the effect of reinitialization on noisy data , This paper also considers learning under label noise . It's amazing , under these circumstances , Reinitialization greatly improves standard training , Even with other carefully tuned regularization techniques .
Re-initializing a neural network during training has been observed to improve generalization in recent works. Yet it is neither widely adopted in deep learning practice nor is it often used in state-of-the-art training protocols. This raises the question of when re-initialization works, and whether it should be used together with regularization techniques such as data augmentation, weight decay and learning rate schedules. In this work, we conduct an extensive empirical comparison of standard training with a selection of re-initialization methods to answer this question, training over 15,000 models on a variety of image classification benchmarks. We first establish that such methods are consistently beneficial for generalization in the absence of any other regularization. However, when deployed alongside other carefully tuned regularization techniques, re-initialization methods offer little to no added benefit for generalization, although optimal generalization performance becomes less sensitive to the choice of learning rate and weight decay hyperparameters. To investigate the impact of re-initialization methods on noisy data, we also consider learning under label noise. Surprisingly, in this case, re-initialization significantly improves upon standard training, even in the presence of other carefully tuned regularization techniques.
https://arxiv.org/abs/2206.10011





5、[LG] (Certified!!) Adversarial Robustness for Free!
N Carlini, F Tramer, K (Dj)Dvijotham, J. Z Kolter
[Google & CMU]
free ( authentication ) Against robustness . This article shows how to implement the pre training of L2 State of the art authentication robustness against norm bounded perturbations . A diffusion probability model combined with pre training and a standard high-precision classifier , Instantiate Salman De-noising and smoothing method of et al . This makes it possible to prove that under the constraint of resisting disturbance 71% Of ImageNet The accuracy lies in ε = 0.5 Of L2 Within norm , Use any method than previously certified SoTA Improved 14 percentage , Or better than de-noising and smoothing 30 percentage . Only the pre trained diffusion model and image classifier are used to obtain these results , Without any fine tuning or retraining of model parameters .
In this paper we show how to achieve state-of-the-art certified adversarial robustness to `2-norm bounded perturbations by relying exclusively on off-the-shelf pretrained models. To do so, we instantiate the denoised smoothing approach of Salman et al. by combining a pretrained denoising diffusion probabilistic model and a standard high-accuracy classifier. This allows us to certify 71% accuracy on ImageNet under adversarial perturbations constrained to be within an `2 norm of ε = 0.5, an improvement of 14 percentage points over the prior certified SoTA using any approach, or an improvement of 30 percentage points over denoised smoothing. We obtain these results using only pretrained diffusion models and image classifiers, without requiring any fine tuning or retraining of model parameters.
https://arxiv.org/abs/2206.10550



Several other papers worthy of attention :
[CL] Large Language Models Still Can't Plan (A Benchmark for LLMs on Planning and Reasoning about Change)
Large language models still cannot be planned ( Large language model planning and reasoning benchmark about change )
K Valmeekam, A Olmo, S Sreedharan, S Kambhampati
[Arizona State University]
https://arxiv.org/abs/2206.10498


[CV] Intra-Instance VICReg: Bag of Self-Supervised Image Patch Embedding
Intra-Instance VICReg: Self monitoring block embedded in bag
Y Chen, A Bardes, Z Li, Y LeCun
[Meta AI & Redwood Center]
https://arxiv.org/abs/2206.08954





[CV] Global Context Vision Transformers
Global context vision Transformer
A Hatamizadeh, H Yin, J Kautz, P Molchanov
[NVIDIA]
https://arxiv.org/abs/2206.09959





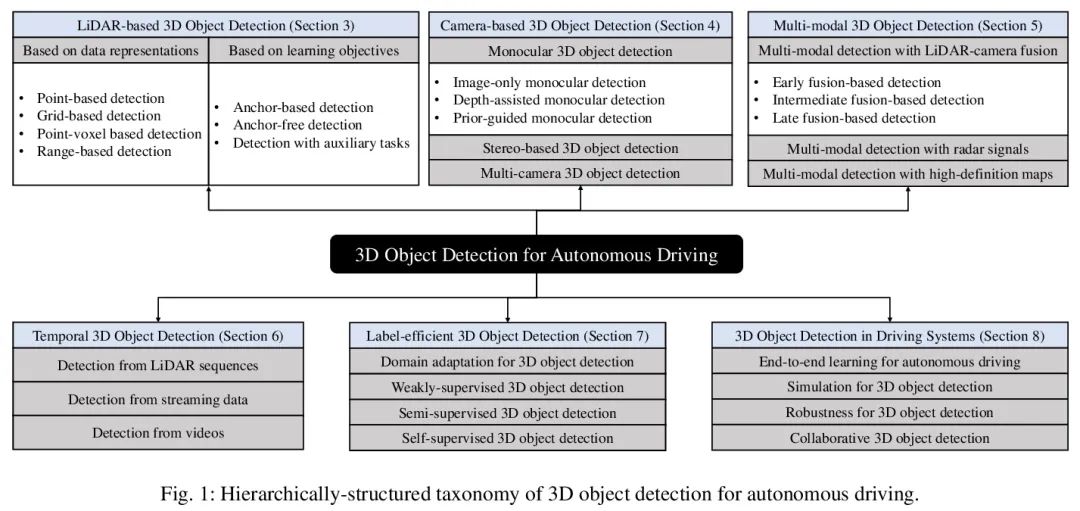
[CV] 3D Object Detection for Autonomous Driving: A Review and New Outlooks
For driverless 3D object detection : Review and prospect
J Mao, S Shi, X Wang, H Li
[The Chinese University of Hong Kong & Max Planck Institute for Informatics]
https://arxiv.org/abs/2206.09474




边栏推荐
- Homekit supports the matter protocol. What does this imply?
- kubernetes comfig subpath
- Esp32-c3 introductory tutorial problems ⑧ - blufi_ example. c:244: undefined reference to `esp_ ble_ gap_ start_ advertising
- Capacity limited facility location problem
- Lm05 former VIX (second generation product)
- Androd Gradle模块依赖替换如何使用
- Analysis and solution of connection failure caused by MySQL using replicationconnection
- In flinksql, the Kafka flow table and MySQL latitude flow table are left joined, and the association is made according to I'd. false
- 理财产品长期是几年?新手最好买长期还是短期?
- LM05丨曾经的VIX(二代产品)
猜你喜欢

"Four highs" of data midrange stability | startdt Tech Lab 18

What should testers do if the requirements need to be changed when the project is half tested?

Homekit and NFC support: smart Ting smart door lock SL1 only costs 149 yuan

After the uncommitted transactions in the redo log buffer of MySQL InnoDB are persisted to the redo log, what happens if the transaction rollback occurs?

618的省钱技术攻略 来啦 -体验场景 领取10元猫超卡!
What if the test time is not enough?

HomeKit支持matter协议,这背后将寓意着什么?

Architecture design methods in technical practice

Excel-VBA 快速上手(一、宏、VBA、过程、类型与变量、函数)

MySQL使用ReplicationConnection导致的连接失效分析与解决
随机推荐
sed -i命令怎么使用
TUIKit 音视频低代码解决方案导航页
有向图D和E
Restcloud ETL resolves shell script parameterization
Oracle中dbms_output.put_line怎么使用
Go write permissions to file writefile (FileName, data, 0644)?
Configure SSH Remote Login for H3C switch
2 万字 + 30 张图 |MySQL 日志:undo log、redo log、binlog 有什么用?
Photon network framework
Excel-VBA 快速上手(一、宏、VBA、过程、类型与变量、函数)
Gradle Build Cache引发的Task缓存编译问题怎么解决
CDH mail alarm configuration
When did the redo log under InnoDB in mysql start to perform check point disk dropping?
在线文本实体抽取能力,助力应用解析海量文本数据
Hanyuan high tech USB3.0 optical transceiver USB industrial touch screen optical transceiver USB3.0 optical fiber extender USB3.0 optical fiber transmitter
Wallys/DR6018-S/ 802.11AX MU-MIMO OFDMA / 2* GE PORTS/WIFI 6e / BAND DUAL CONCURRENT
AssetBundle resource management
Cloud native essay deep understanding of ingress
Germancreditdata of dataset: a detailed introduction to the introduction, download and use of germancreditdata dataset
.Net怎么使用日志框架NLog