当前位置:网站首页>Redis practice: smart use of data types to achieve 100 million level data statistics
Redis practice: smart use of data types to achieve 100 million level data statistics
2022-06-25 19:59:00 【Code byte】
In the business scenario of mobile applications , We need to keep this information : One key Associated with a data set , At the same time, the data in the collection should be sorted statistically .
Common scenarios are as follows :
- Give me a userId , Judge user login status ;
- 200 million users recently 7 The check-in of the day , Statistics 7 The total number of users who sign in continuously in a day ;
- Count the number of new users every day and the number of retained users the next day ;
- Statistics of website visitors (Unique Visitor,UV) The amount
- The latest comment list
- According to the amount of music played
Usually , The number of users and the number of visits we face are huge , Like a million 、 Tens of millions of users , Or tens of millions of levels 、 Even hundreds of millions of levels of access information .
therefore , We have to choose to be able to count a lot of data very efficiently ( For example, 100 million ) Set type of .
How to choose the right data set , First of all, we need to understand the common statistical models , And use reasonable data to solve practical problems .
Four statistical types :
- Binary state statistics ;
- Aggregate statistics ;
- Sort Statistics ;
- Base Statistics .
This article will use String、Set、Zset、List、hash Extended data types beyond Bitmap、HyperLogLog To achieve .
The instructions involved in this article can be sent online Redis Client run debug , Address :https://try.redis.io/, It's very convenient to say .
remarks
Share more and give more , In the early stage, we should create more value for others and ignore the return , In the long run , All these efforts will pay you back .
Especially when you start working with others , Don't worry about short-term returns , It doesn't make much sense , It's more about exercising your vision 、 Perspective and problem solving ability .
Binary state statistics
Margo , What is binary state statistics ?
That is, the values of the elements in the set are only 0 and 1 Two kinds of , In the scene of check-in and clock in and whether the user logs in or not , Just record Sign in (1) or Not signed in (0), Logged in (1) or Not logged in (0).
If we use it in the scenario of judging whether the user logs in or not Redis Of String Type implementation (key -> userId,value -> 0 It means offline ,1 - land ), If storage 100 Login status of 10000 users , If it's stored as a string , You need to store 100 Ten thousand strings , Too much memory overhead .
For binary state scenarios , We can use it Bitmap To achieve . For example, we use a login status bit Who said , 100 million users only occupy One hundred million individual bit Bit memory ≈ (100000000 / 8/ 1024/1024)12 MB.
The approximate formula for space occupation is :($offset/8/1024/1024) MBWhat is? Bitmap Well ?
Bitmap The underlying data structure of is String Type of SDS Data structure to hold bit groups ,Redis Put each byte in the array of 8 individual bit Use it , Every bit position Represents the binary state of an element ( No 0 Namely 1).
Can be Bitmap Think of it as a bit An array of units , Each unit of an array can only store 0 perhaps 1, The subscript of the array is in Bitmap called offset Offset .
For the sake of visualizing , We can understand that buf Each byte of the array is represented by a line , Every line has 8 individual bit position ,8 The two lattices represent each of the 8 individual bit position , As shown in the figure below :

8 individual bit Form a Byte, therefore Bitmap It saves a lot of storage space . This is it. Bitmap The advantages of .
Judge user login status
How to use it? Bitmap To determine whether a certain user in the mass of users is online ?
Bitmap Provides GETBIT、SETBIT operation , By an offset value offset Yes bit Array of offset Positional bit Bit for read and write operations , It should be noted that offset from 0 Start .
Just one key = login_status Indicates to store user login status collection data , Will the user ID As offset, Online is set to 1, Offline settings 0. adopt GETBIT Judge whether the corresponding user is online . 50000 ten thousand Users only need 6 MB Space .
SETBIT command
SETBIT <key> <offset> <value>Set or clear key Of value stay offset Situated bit value ( Can only be 0 perhaps 1).
GETBIT command
GETBIT <key> <offset>obtain key Of value stay offset Situated bit The value of a , When key When there is no , return 0.
If we want to judge ID = 10086 Login status of users :
First step , Execute the following instructions , Indicates that the user is logged in .
SETBIT login_status 10086 1The second step , Check whether the user is logged in , Return value 1 Indicates that you are logged in .
GETBIT login_status 10086The third step , Log out , take offset Corresponding value Set to 0.
SETBIT login_status 10086 0Check in status of users every month
In the check-in Statistics , Every user signs in every day 1 individual bit Who said , A year's check-in only requires 365 individual bit position . A month at most is 31 God , It only needs 31 individual bit Who can .
For example, statistics number 89757 User in 2021 year 5 How to do the clock out in the month ?
key Can be designed as uid:sign:{userId}:{yyyyMM}, The value of each day of the month - 1 It can be used as offset( because offset from 0 Start , therefore offset = date - 1).
First step , Execute the following command to record the user's status in 2021 year 5 month 16 Punch in .
SETBIT uid:sign:89757:202105 15 1The second step , Judge the number 89757 The user is in 2021 year 5 month 16 Whether to punch in or not .
GETBIT uid:sign:89757:202105 15 The third step , Statistics of the user in 5 The number of clocks in the month , Use BITCOUNT Instructions . This instruction is used to count a given bit Array , value = 1 Of bit Number of bits .
BITCOUNT uid:sign:89757:202105In this way, we can achieve the user's monthly clock out situation , Isn't that great .
How to count the first clock in time of this month ?
Redis Provides BITPOS key bitValue [start] [end] Instructions , Return the data representation Bitmap The first value in is bitValue Of offset Location .
By default , The command will detect the entire bitmap , Users can choose from the optional start Parameters and end Parameter specifies the range to detect .
So we can get it by executing the following command userID = 89757 stay 2021 year 5 month Punch in for the first time date :
BITPOS uid:sign:89757:202105 1It should be noted that , We need to return value + 1 Indicates the day of the first clock out , because offset from 0 Start .
Total number of continuous check-in users
After recording a hundred million continuous users 7 Days of clock in data , How to count out this continuous 7 The total number of users who punch in continuously in a day ?
We take the date of each day as Bitmap Of key,userId As offset, If you punch in, it will offset Positional bit Set to 1.
key Each of the corresponding sets bit Bit data is a user's clock in record on that date .
Altogether 7 This one Bitmap, If we can understand this 7 individual Bitmap It's the same as bit Do it 『 And 』 operation .
alike UserID offset It's all the same , When one userID stay 7 individual Bitmap Corresponding to offset Positional bit = 1 It means that the user 7 Clock in every day .
The results are saved to a new Bitmap in , We'll pass it again BITCOUNT Statistics bit = 1 You'll get a continuous clock in 7 Total number of users per day .
Redis Provides BITOP operation destkey key [key ...] This instruction is used for one or more key = key Of Bitmap Perform bit operation .
opration It can be and、OR、NOT、XOR. When BITOP When dealing with strings of different lengths , The missing part of the shorter string will be treated as 0 .
Empty key It is also seen as containing 0 String sequence of .
Easy to understand , As shown in the figure below :

3 individual Bitmap, Corresponding bit Do it 「 And 」 operation , Save the results to a new Bitmap in .
The operation instruction indicates that Three bitmap Conduct AND operation , And save the result to destmap in . Then on destmap perform BITCOUNT Statistics .
// And operation BITOP AND destmap bitmap:01 bitmap:02 bitmap:03// Statistics bit position = 1 The number of BITCOUNT destmapSimple calculation A 100 million bit Bitmap Memory overhead , About 12 MB Of memory (10^8/8/1024/1024),7 Days of Bitmap The memory cost of is about 84 MB. At the same time, we'd better give Bitmap Set expiration time , Give Way Redis Delete expired clock in data , Save memory .
Summary
Thinking is the most important thing , When we encounter statistical scenarios, we only need the binary state of statistical data , For example, whether users exist 、 ip Whether it's a blacklist 、 And check-in and clock out statistics and other scenarios can be considered Bitmap.
Just one bit A bit means 0 and 1, In the statistics of massive data, it will greatly reduce the memory consumption .
Base Statistics
Base Statistics : Count the number of non repeating elements in a set , It is often used to calculate the number of independent users (UV).
The most direct way to realize cardinality statistics , It's using sets (Set) This data structure , When an element never appears out of date , Add an element to the set ; If there has been , So the set remains the same .
When page visits are huge , You need a big one Set Collect statistics , A lot of space will be wasted .
in addition , Such data does not need to be accurate , Is there a better plan ?
That's a good question ,Redis Provides HyperLogLog Data structure is used to solve the statistical problems of various scenarios .
HyperLogLog It is an imprecise cardinality elimination scheme , Its statistical rules are based on probability , Standard error 0.81%, This accuracy is sufficient to meet the requirements of UV Statistics demand .
About HyperLogLog It's too complicated , If you want to know, please move :
Website UV
adopt Set Realization
A user can only visit a website once a day , So it's easy to think of passing Redis Of Set Set to achieve .
The user id 89757 visit 「Redis Why so soon? 」 when , We put this information in the Set in .
SADD Redis Why so soon? :uv 89757When user number 89757 Multiple access 「Redis Why so soon? 」 page ,Set The de duplication function of ensures that the same user will not be recorded repeatedly ID.
adopt SCARD command , Statistics 「Redis Why so soon? 」 page UV. Instruction returns the number of elements in a set ( That is, users ID).
SCARD Redis Why so soon? :uvadopt Hash Realization
Old and wet , It can also be used Hash Type implementation , Will the user ID As Hash A collection of key, Access to the page is executed HSET The order will value Set to 1.
Even if users visit repeatedly , Repeat command , That's the only thing I'll do userId The value of is set to “1".
Last , utilize HLEN Command Statistics Hash The number of elements in a set is UV.
as follows :
HSET redis colony :uv userId:89757 1// Statistics UVHLEN redis colony HyperLogLog The king plan
Old and wet ,Set Is good , If the article is very popular, reach ten million level , One Set Saved the data of tens of millions of users ID, Too many pages and too much memory . Empathy ,Hash The same is true for data types . Do how? ?
utilize Redis Provided HyperLogLog Advanced data structure ( Don't just know Redis There are five basic data types of ). This is a data set type for cardinality Statistics , Even if the amount of data is large , The space needed to calculate the cardinality is also fixed .
Every HyperLogLog At most, it's only a cost 12KB Memory can be calculated 2 Of 64 The cardinality of two elements .
Redis Yes HyperLogLog Optimized storage for , When the count is small , Coefficient matrix is used for storage space , It takes up very little space .
Only when the count is large , A sparse matrix can be transformed into a dense matrix only when the space occupied by it exceeds the threshold , Occupy 12KB Space .
PFADD
Each user who will visit the page ID Add to HyperLogLog in .
PFADD Redis Master slave synchronization principle :uv userID1 userID 2 useID3PFCOUNT
utilize PFCOUNT obtain 「Redis Master slave synchronization principle 」 Page UV value .
PFCOUNT Redis Master slave synchronization principle :uvPFMERGE Use scenarios
HyperLogLog Except for the top PFADD and PFCOIUNT Outside , It also provides PFMERGE , Will be multiple HyperLogLog Merge together to form a new HyperLogLog value .
grammar
PFMERGE destkey sourcekey [sourcekey ...]Use scenarios
For example, in the website, we have two pages with similar content , The operation said that the data of these two pages should be combined .
One of the pages of UV Traffic also needs to be combined , So at this point PFMERGE I can use it , That is to say The same user visits these two pages only once .
As shown below :Redis、MySQL Two Bitmap The collection holds two pages of user access data .
PFADD Redis data user1 user2 user3PFADD MySQL data user1 user2 user4PFMERGE database Redis data MySQL data PFCOUNT database // Return value = 4Will be multiple HyperLogLog Merge (merge) For one HyperLogLog , After the merger HyperLogLog The cardinality of is close to all inputs HyperLogLog The visible set of (observed set) Of Combine .
user1、user2 All visited Redis and MySQL, It's only one visit .
Sort Statistics
Redis Of 4 Among collection types (List、Set、Hash、Sorted Set),List and Sorted Set It's orderly .
- List: Insert by element List The order of , Use scenarios can usually be used as Message queue 、 Latest list 、 Ranking List ;
- Sorted Set: According to the score Weight ranking , We can decide the weight value of each element by ourselves . Use scenarios ( Ranking List , For example, according to the amount of play 、 Number of likes ).
The latest comment list
Old and wet , I can use List Insert the order of sorting to achieve a list of comments
For example, the backstage reply list of WeChat public official account. ( No bars , For example ), Each official account corresponds to one. List, This List All user comments on the official account are kept. .
Every time a user comments , The use of LPUSH key value [value ...] Insert into List Team head .
LPUSH Code byte 1 2 3 4 5 6 Then use LRANGE key star stop Gets the elements in the specified interval of the list .
> LRANGE Code byte 0 41) "6"2) "5"3) "4"4) "3"5) "2"Be careful , Not all the latest lists are available List Realization , For frequently updated lists ,list Type pagination can cause list elements to be duplicated or omitted .
Like the current comment list List ={A, B, C, D}, The left shows the latest comments ,D It's the first comment .
LPUSH Code byte D C B AShow the first page of the latest 2 Comments , Get A、B:
LRANGE Code byte 0 11) "A"2) "B" According to the logic we want , The second page is available through LRANGE Code byte 2 3 obtain C,D.
If before showing the second page , Generate new comments E, Comment on E adopt LPUSH Code byte E Insert into List Team head ,List = {E, A, B, C, D }.
Execute now LRANGE Code byte 2 3 Get the second page comments found , B again .
LRANGE Code byte 2 31) "B"2) "C" The reason for this is that List It is sorted by the location of the elements , Once a new element is inserted ,List = {E,A,B,C,D}.
Where is the original data List Move one bit back , Causes old elements to be read .

Summary
Only no paging is required ( For example, only the top of the list is taken every time 5 Elements ) Or the update frequency is low ( For example, statistics are updated every morning ) It's the right list to use List Type implementation .
For lists that need to be paged and updated frequently , We need to use ordered sets Sorted Set Type implementation .
in addition , The latest list that needs to be looked up through the time range ,List Types don't work , We need to use ordered sets Sorted Set Type implementation , For example, the order list can be queried based on the transaction time range .
Ranking List
Old and wet , For scenes with the latest list ,List and Sorted Set Can achieve , Why still use List Well ? Use it directly Sorted Set Not better , It can also be set score More flexible weight ranking .
as a result of Sorted Set What is the memory capacity of the type List Many times as many types , For a small number of lists , It can be used Sorted Set Type to implement .
Like a week of music charts , We need to update the playback in real time , And it needs to be displayed in pages .
in addition to , The order is determined by the amount of play , This is the time List Can't be satisfied .
We can make music ID Save to Sorted Set Collection ,score Set to the number of plays per song , The music is set every time it is played score = score +1.
ZADD
For example, we will 《 blue and white porcelain 》 and 《 Huatian is wrong 》 Add playback to musicTop Collection :
ZADD musicTop 100000000 blue and white porcelain 8999999 Huatian is wrong ZINCRBY
《 blue and white porcelain 》 Every time it's played, it's passed ZINCRBY Instructions will be score + 1.
> ZINCRBY musicTop 1 blue and white porcelain 100000001ZRANGEBYSCORE
Finally, we need to get musicTop The top ten Volume music list , What's the current maximum amount of play N , It can be obtained by the following command :
ZRANGEBYSCORE musicTop N-9 N WITHSCORES65 Brother : But this N How can we get it ?
ZREVRANGE
It can be done by ZREVRANGE key start stop [WITHSCORES] Instructions .
Where elements are sorted by score The value is decreasing ( From big to small ) To arrange .
Have the same score The members of the value are in the reverse order of the dictionary order (reverse lexicographical order) array .
> ZREVRANGE musicTop 0 0 WITHSCORES1) " blue and white porcelain "2) 100000000Summary
Even if the elements in the collection are updated frequently ,Sorted Set Can also pass through ZRANGEBYSCORE The command gets the data in order accurately .
Show the latest list when you need it 、 In the scene of ranking, etc , If the data is updated frequently or needs to be displayed in pages , It is suggested that priority should be given to use Sorted Set.
Aggregate statistics
It refers to the statistics of aggregation results of multiple set elements , for instance :
- Count common data of multiple elements ( intersection );
- Counts the unique element of one of the two sets ( Difference set statistics );
- Count all elements of multiple sets ( Union statistics ).
Old and wet , What kind of scene will use intersection 、 Difference set 、 What about Union ?
Redis Of Set Type supports adding, deleting, modifying and querying in a collection , The bottom layer uses Hash data structure , Whether it's add、remove All are O(1) Time complexity .
And support the intersection of multiple sets 、 Combine 、 Subtraction operation , Use these set operations , Solve the statistical problems mentioned above .
intersection - Common friends
such as QQ The common friends in are the intersection of aggregation statistics . We use the account number as Key, Friends of this account Set A collection of value.
Simulate the friend collection of two users :
SADD user: Code byte R Big Linux A great god PHP The father of SADD user: bosses Linux A great god Python A great god C++ Vegetable chicken 
Only two friends are needed to count two users Set Intersection of sets , Following commands :
SINTERSTORE user: Common friends user: Code byte user: bosses After command execution ,「user: Code byte 」、「user: bosses 」 The intersection data of two sets is stored in the user: In this collection of common friends .
Difference set - New friends per day
such as , Count a App Daily new registered users , Just take the difference set from the total number of registered users in the past two days .
such as ,2021-06-01 The total number of registered users is stored in key = user:20210601 set Collection ,2021-06-02 The total number of users stored in key = user:20210602 The collection of .
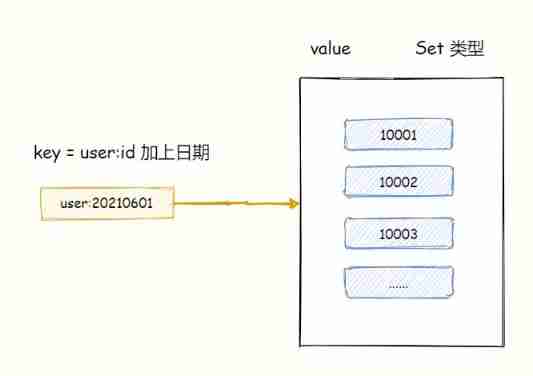
The following instructions , Perform the difference calculation and store the results in the user:new Collection .
SDIFFSTORE user:new user:20210602 user:20210601completion of enforcement , At this time user:new The set will be 2021/06/02 Daily new users .
besides ,QQ There's a person you might know , You can also use difference sets , It's subtracting your friends from your friends, that is, the people you may know .
Combine - Total new friends
Or an example of difference set , Statistics 2021/06/01 and 2021/06/02 Total number of new users in two days , You only need to perform Union on two collections .
SUNIONSTORE userid:new user:20210602 user:20210601Now the new set userid:new It's a new friend in two days .
Summary
Set The difference between the set 、 The computation complexity of Union and intersection is high , In case of large amount of data , If these calculations are performed directly , It can lead to Redis Instance blocking .
therefore , A cluster can be specially deployed for statistics , Let it specialize in aggregate computing , Or read the data to the client , Aggregate statistics on the client side , In this way, we can avoid that other services cannot respond due to blocking .
Previous recommendation
Redis Core : The secret that can't be broken quickly
Redis Journal : The killer of fast recovery without fear of downtime
Redis High availability : You call this master-slave architecture data synchronization principle ?
Redis High availability : You call this Sentinel The principle of sentry group
Redis High availability :Cluster How much data can a cluster support ?

边栏推荐
- 2.2 step tariff
- Thymleaf template configuration analysis
- Yum command
- Mysql database design suggestions
- Web container basic configuration
- 通过启牛学堂开的股票账户可以用吗?资金安全吗?
- Database data type design (the most detailed in the whole network)
- PAT B1076
- PAT B1071
- Connecting PHP to MySQL instances in the lamp environment of alicloud's liunx system
猜你喜欢

Applet canvas generate sharing Poster
Wechat applet swiper simple local picture display appears large blank

Profile path and name

Jsonp non homologous interaction (click trigger)

Lilda Bluetooth air conditioning receiver helps create a more comfortable road life

Use of serialize() and serializearray() methods for form data serialization

Single chip microcomputer line selection method to store impression (address range) method + Example

Arduino read temperature

Wechat applet cloud function does not have dependency option installed

Bloom filter
随机推荐
VMware failed to prompt to lock this profile exclusively
2.1 write a program to calculate the sum and average of four integers.
How do I delete an entity from symfony2
Gbpnzd firm offer for 14 months, simulation for 19 months, test stable
Web container basic configuration
The meanings of /32, /48, /64 in IPv6 addresses
wooyun-2014-065513
Is it safe to open an account with flush?
Pdf file download (the download name is the same as the file name)
What are Baidu collection skills? 2022 Baidu article collection skills
2.5 find the sum of the first n terms of the square root sequence
PHP FPM, workman, spoole, golang simple performance test
rmi-registry-bind-deserialization
Applet canvas generate sharing Poster
Arduino : No such file or directory
Record Baidu search optimization thinking analysis
在打新債開戶證券安全嗎?低傭金靠譜嗎
JS mobile phone and computer open different websites
Simple native JS tab bar switching
Error record: preg_ match(): Compilation failed: range out of order in character class at offset 13