当前位置:网站首页>用Attention和微调BERT进行自然语言推断-PyTorch
用Attention和微调BERT进行自然语言推断-PyTorch
2022-06-26 16:01:00 【葫芦娃啊啊啊啊】
动手学深度学习笔记
一、自然语言推断与数据集
当需要决定一个句子是否可以从另一个句子推断出来,或者需要通过识别语义等价的句子来消除句子间冗余时,知道如何对一个文本序列进行分类是不够的。相反,我们需要能够对成对的文本序列进行推断。
1.自然语言推断
自然语言推断(natural language inference)主要研究假设(hypothesis)是否可以从前提(premise)中推断出来,其中两者都是文本序列。换言之,自然语言推断决定了一对文本序列之间的逻辑关系。这类关系通常分为三种类型:
- 蕴涵(entailment): 假设可以从前提中推断出来。
- 矛盾(contradiction): 假设的否定可以从前提中推断出来。
- 中性(neutral): 所有其他情况。
自然语言推断也被称为识别文本蕴涵任务。
2.斯坦福自然语言推断数据集
斯坦福自然语言推断语料库(Stanford Natural Language Inference,SNLI是由500000多个带标签的英语句子对组成的集合。训练集约有550000对,测试集约有10000对,训练集和测试集中的三个标签“蕴涵”、“矛盾”和“中性”是平衡的。
import os
import re
import torch
from torch import nn
from d2l import torch as d2l
#@save
d2l.DATA_HUB['SNLI'] = (
'https://nlp.stanford.edu/projects/snli/snli_1.0.zip',
'9fcde07509c7e87ec61c640c1b2753d9041758e4')
data_dir = d2l.download_extract('SNLI')
def read_snli(data_dir, is_train):
"""将SNLI数据集解析为前提、假设和标签"""
def extract_text(s):
# 删除括号
s = re.sub('\\(', '', s)
s = re.sub('\\)', '', s)
# 两个或多个连续的空格只保留一个空格
s = re.sub('\\s{2,}', ' ', s)
return s.strip()
# 蕴涵:0,矛盾:1,中性:2
label_set = {
'entailment': 0, 'contradiction': 1, 'neutral': 2}
file_name = os.path.join(data_dir, 'snli_1.0_train.txt'
if is_train else 'snli_1.0_test.txt')
with open(file_name, 'r') as f:
rows = [row.split('\t') for row in f.readlines()[1:]]
premises = [extract_text(row[1]) for row in rows if row[0] in label_set]
hypotheses = [extract_text(row[2]) for row in rows if row[0] in label_set]
labels = [label_set[row[0]] for row in rows if row[0] in label_set]
return premises, hypotheses, labels
- 加载数据集
class SNLIDataset(torch.utils.data.Dataset):
"""用于加载SNLI数据集的自定义数据集"""
def __init__(self, dataset, num_steps, vocab=None):
self.num_steps = num_steps
all_premise_tokens = d2l.tokenize(dataset[0])
all_hypothesis_tokens = d2l.tokenize(dataset[1])
if vocab is None:
self.vocab = d2l.Vocab(all_premise_tokens + \
all_hypothesis_tokens, min_freq=5, reserved_tokens=['<pad>'])
else:
self.vocab = vocab
self.premises = self._pad(all_premise_tokens)
self.hypotheses = self._pad(all_hypothesis_tokens)
self.labels = torch.tensor(dataset[2])
print('read ' + str(len(self.premises)) + ' examples')
def _pad(self, lines):
return torch.tensor([d2l.truncate_pad(
self.vocab[line], self.num_steps, self.vocab['<pad>'])
for line in lines])
def __getitem__(self, idx):
return (self.premises[idx], self.hypotheses[idx]), self.labels[idx]
def __len__(self):
return len(self.premises)
调用read_snli函数和SNLIDataset类来下载SNLI数据集,并返回训练集和测试集的DataLoader实例,以及训练集的词表。注意,必须使用从训练集构造的词表作为测试集的词表。因此,在训练集中训练的模型将不知道来自测试集的任何新词元。
def load_data_snli(batch_size, num_steps=50):
"""下载SNLI数据集并返回数据迭代器和词表"""
data_dir = d2l.download_extract('SNLI')
train_data = read_snli(data_dir, True)
test_data = read_snli(data_dir, False)
train_set = SNLIDataset(train_data, num_steps)
test_set = SNLIDataset(test_data, num_steps, train_set.vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
shuffle=False)
return train_iter, test_iter, train_set.vocab
二、利用注意力进行自然语言推断
1.模型
与保留前提和假设中词元的顺序相比,我们可以将一个文本序列中的词元与另一个文本序列中的每个词元对齐,然后比较和聚合这些信息,以预测前提和假设之间的逻辑关系。与机器翻译中源句和目标句之间的词元对齐类似,前提和假设之间的词元对齐可以通过注意力机制灵活地完成。

- 注意
第一步是将一个文本序列中的词元与另一个序列中的每个词元对齐。对齐是使用加权平均的“软”对齐,其中理想情况下较大的权重与要对齐的词元相关联。
使用注意力机制的软对齐: A = ( a 1 , … , a m ) \mathbf{A} = (\mathbf{a}_1, \ldots, \mathbf{a}_m) A=(a1,…,am)和 B = ( b 1 , … , b n ) \mathbf{B} = (\mathbf{b}_1, \ldots, \mathbf{b}_n) B=(b1,…,bn)表示前提和假设,词元数量分别为 m m m和 n n n,其中 a i , b j ∈ R d \mathbf{a}_i, \mathbf{b}_j \in \mathbb{R}^{d} ai,bj∈Rd。对于软对齐,注意力权重 e i j ∈ R e_{ij} \in \mathbb{R} eij∈R计算为:
e i j = f ( a i ) ⊤ f ( b j ) e_{ij} = f(\mathbf{a}_i)^\top f(\mathbf{b}_j) eij=f(ai)⊤f(bj)
其中函数 f f f是在下面的mlp函数中定义的多层感知机。输出维度由mlp的num_hiddens参数指定。
def mlp(num_inputs, num_hiddens, flatten):
net = []
net.append(nn.Dropout(0.2))
net.append(nn.Linear(num_inputs, num_hiddens))
net.append(nn.ReLU())
if flatten:
net.append(nn.Flatten(start_dim=1))
net.append(nn.Dropout(0.2))
net.append(nn.Linear(num_hiddens, num_hiddens))
net.append(nn.ReLU())
if flatten:
net.append(nn.Flatten(start_dim=1))
return nn.Sequential(*net)
在上式中, f f f分别输入 a i \mathbf{a}_i ai和 b j \mathbf{b}_j bj,而不是将它们一对放在一起作为输入。这种分解技巧导致 f f f只有 m + n m + n m+n个次计算(线性复杂度),而不是 m n mn mn次计算(二次复杂度)。对注意力权重进行规范化,计算假设中所有词元向量的加权平均值,以获得假设的表示,该假设与前提中索引 i i i的词元进行软对齐:
β i = ∑ j = 1 n exp ( e i j ) ∑ k = 1 n exp ( e i k ) b j . \boldsymbol{\beta}_i = \sum_{j=1}^{n}\frac{\exp(e_{ij})}{ \sum_{k=1}^{n} \exp(e_{ik})} \mathbf{b}_j. βi=j=1∑n∑k=1nexp(eik)exp(eij)bj.
同样,计算假设中索引为 j j j的每个词元与前提词元的软对齐:
α j = ∑ i = 1 m exp ( e i j ) ∑ k = 1 m exp ( e k j ) a i . \boldsymbol{\alpha}_j = \sum_{i=1}^{m}\frac{\exp(e_{ij})}{ \sum_{k=1}^{m} \exp(e_{kj})} \mathbf{a}_i. αj=i=1∑m∑k=1mexp(ekj)exp(eij)ai.
定义Attend类来计算假设(beta)与输入前提A的软对齐以及前提(alpha)与输入假设B的软对齐。
class Attend(nn.Module):
def __init__(self, num_inputs, num_hiddens, **kwargs):
super(Attend, self).__init__(**kwargs)
self.f = mlp(num_inputs, num_hiddens, flatten=False)
def forward(self, A, B):
# A/B的形状:(批量大小,序列A/B的词元数,embed_size)
# f_A/f_B的形状:(批量大小,序列A/B的词元数,num_hiddens)
f_A = self.f(A)
f_B = self.f(B)
# e的形状:(批量大小,序列A的词元数,序列B的词元数)
e = torch.bmm(f_A, f_B.permute(0, 2, 1))
# beta的形状:(批量大小,序列A的词元数,embed_size),
# 意味着序列B被软对齐到序列A的每个词元(beta的第1个维度)
beta = torch.bmm(F.softmax(e, dim=-1), B)
# alpha的形状:(批量大小,序列B的词元数,embed_size),
# 意味着序列A被软对齐到序列B的每个词元(alpha的第1个维度)
alpha = torch.bmm(F.softmax(e.permute(0, 2, 1), dim=-1), A)
return beta, alpha
- 比较
接下来,将一个序列中的词元与该词元软对齐的另一个序列进行比较。注意,在软对齐中,一个序列中的所有词元(尽管可能具有不同的注意力权重)将与另一个序列中的词元进行比较。例如,上述的“注意”步骤确定前提中的“need”和“sleep”都与假设中的“tired”对齐,则将对“疲倦-需要睡眠”进行比较。
在比较步骤中,将来自一个序列的词元的连结和来自另一序列的对齐的词元送入函数 g g g(一个多层感知机):
v A , i = g ( [ a i , β i ] ) , i = 1 , … , m v B , j = g ( [ b j , α j ] ) , j = 1 , … , n \mathbf{v}_{A,i} = g([\mathbf{a}_i, \boldsymbol{\beta}_i]), i = 1, \ldots, m\\ \mathbf{v}_{B,j} = g([\mathbf{b}_j, \boldsymbol{\alpha}_j]), j = 1, \ldots, n vA,i=g([ai,βi]),i=1,…,mvB,j=g([bj,αj]),j=1,…,n
其中, v A , i \mathbf{v}_{A,i} vA,i是指,所有假设中的词元与前提中词元 i i i软对齐,再与词元 i i i的比较; v B , j \mathbf{v}_{B,j} vB,j是指,所有前提中的词元与假设中词元 i i i软对齐,再与词元 i i i的比较。
下面的Compare个类定义了比较步骤。
class Compare(nn.Module):
def __init__(self, num_inputs, num_hiddens, **kwargs):
super(Compare, self).__init__(**kwargs)
self.g = mlp(num_inputs, num_hiddens, flatten=False)
def forward(self, A, B, beta, alpha):
V_A = self.g(torch.cat([A, beta], dim=2))
V_B = self.g(torch.cat([B, alpha], dim=2))
return V_A, V_B
- 聚合
现有两组比较向量 v A , i \mathbf{v}_{A,i} vA,i( i = 1 , … , m i = 1, \ldots, m i=1,…,m)和 v B , j \mathbf{v}_{B,j} vB,j( j = 1 , … , n j = 1, \ldots, n j=1,…,n),将聚合这些信息以推断逻辑关系。首先求和这两组比较向量:
v A = ∑ i = 1 m v A , i , v B = ∑ j = 1 n v B , j . \mathbf{v}_A = \sum_{i=1}^{m} \mathbf{v}_{A,i}, \quad \mathbf{v}_B = \sum_{j=1}^{n}\mathbf{v}_{B,j}. vA=i=1∑mvA,i,vB=j=1∑nvB,j.
接下来,将两个求和结果的连结提供给函数 h h h(一个多层感知机),以获得逻辑关系的分类结果:
y ^ = h ( [ v A , v B ] ) . \hat{\mathbf{y}} = h([\mathbf{v}_A, \mathbf{v}_B]). y^=h([vA,vB]).
聚合步骤在以下Aggregate类中定义。
class Aggregate(nn.Module):
def __init__(self, num_inputs, num_hiddens, num_outputs, **kwargs):
super(Aggregate, self).__init__(**kwargs)
self.h = mlp(num_inputs, num_hiddens, flatten=True)
self.linear = nn.Linear(num_hiddens, num_outputs)
def forward(self, V_A, V_B):
# 对两组比较向量分别求和
V_A = V_A.sum(dim=1)
V_B = V_B.sum(dim=1)
# 将两个求和结果的连结送到多层感知机中
Y_hat = self.linear(self.h(torch.cat([V_A, V_B], dim=1)))
return Y_hat
- 整合代码
通过将注意步骤、比较步骤和聚合步骤组合在一起,定义可分解注意力模型来联合训练这三个步骤。
class DecomposableAttention(nn.Module):
def __init__(self, vocab, embed_size, num_hiddens, num_inputs_attend = 100,
num_inputs_compare = 200, num_inputs_agg = 400, **kwargs):
super(DecomposableAttention, self).__init__(**kwargs)
self.embedding = nn.Embedding(len(vocab), embed_size)
self.attend = Attend(num_inputs_attend, num_hiddens)
self.compare = Compare(num_inputs_compare, num_hiddens)
# 有3种可能的输出:蕴涵、矛盾和中性
self.aggregate = Aggregate(num_inputs_agg, num_hiddens, num_outputs=3)
def forward(self, X):
premises, hypotheses = X
A = self.embedding(premises)
B = self.embedding(hypotheses)
beta, alpha = self.attend(A, B)
V_A, V_B = self.compare(A, B, beta, alpha)
Y_hat = self.aggregate(V_A, V_B)
return Y_hat
2.训练和评估模型
# 读取数据集
batch_size, num_steps = 256, 50
train_iter, test_iter, vocab = d2l.load_data_snli(batch_size, num_steps)
# 创建模型
embed_size, num_hiddens, devices = 100, 200, d2l.try_all_gpus()
net = DecomposableAttention(vocab, embed_size, num_hiddens)
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds)
# 训练和评估模型
lr, num_epochs = 0.001, 4
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
报错的话,改一下matplotlib的版本 !pip install matplotlib==‘3.0’

3.预测
def predict_snli(net, vocab, premise, hypothesis):
"""预测前提和假设之间的逻辑关系"""
net.eval()
premise = torch.tensor(vocab[premise], device=d2l.try_gpu())
hypothesis = torch.tensor(vocab[hypothesis], device=d2l.try_gpu())
label = torch.argmax(net([premise.reshape((1, -1)),
hypothesis.reshape((1, -1))]), dim=1)
return 'entailment' if label == 0 else 'contradiction' if label == 1 \
else 'neutral'
predict_snli(net, vocab, ['he', 'is', 'good', '.'], ['he', 'is', 'bad', '.'])
# contradiction
三、微调BERT进行自然语言推断
在BERT这篇博客中用一个较小的数据集WikiText-2预训练了BERT(原始的BERT模型是在更大的语料库上预训练的)。下面有两个版本的预训练的BERT:“bert.base”与原始的BERT基础模型一样大,需要大量的计算资源才能进行微调,“bert.small”是一个小版本。
1.加载预训练的BERT
import json
import multiprocessing
import os
import torch
from torch import nn
from d2l import torch as d2l
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')
两个预训练好的BERT模型都包含一个定义词表的“vocab.json”文件和一个预训练参数的“pretrained.params”文件。load_pretrained_model函数加载预先训练好的BERT参数。
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, max_len, devices):
data_dir = d2l.download_extract(pretrained_model)
# 定义空词表以加载预定义词表
vocab = d2l.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir,'vocab.json')))
vocab.token_to_idx = {
token: idx
for idx, token in enumerate(vocab.idx_to_token)}
bert = d2l.BERTModel(len(vocab), num_hiddens, norm_shape=[256],
ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens,
num_heads=4, num_layers=2, dropout=0.2,
max_len=max_len, key_size=256, query_size=256,
value_size=256, hid_in_features=256,
mlm_in_features=256, nsp_in_features=256)
# 加载预训练BERT参数
bert.load_state_dict(torch.load(os.path.join(
data_dir, 'pretrained.params')))
return bert, vocab
2.用于微调BERT的数据集
对于SNLI数据集的下游任务自然语言推断,定义了一个数据集类SNLIBERTDataset。在每个样本中,前提和假设形成一对文本序列,并被打包成一个BERT输入序列。片段索引用于区分BERT输入序列中的前提和假设。利用预定义的BERT输入序列的最大长度(max_len),持续移除输入文本对中较长文本的最后一个标记,直到满足max_len。
class SNLIBERTDataset(torch.utils.data.Dataset):
def __init__(self, dataset, max_len, vocab=None):
all_premise_hypothesis_tokens = [[
p_tokens, h_tokens] for p_tokens, h_tokens in zip(
*[d2l.tokenize([s.lower() for s in sentences])
for sentences in dataset[:2]])]
self.labels = torch.tensor(dataset[2])
self.vocab = vocab
self.max_len = max_len
(self.all_token_ids, self.all_segments,
self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)
print('read ' + str(len(self.all_token_ids)) + ' examples')
def _preprocess(self, all_premise_hypothesis_tokens):
pool = multiprocessing.Pool(4) # 使用4个进程
out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)
all_token_ids = [token_ids for token_ids, segments, valid_len in out]
all_segments = [segments for token_ids, segments, valid_len in out]
valid_lens = [valid_len for token_ids, segments, valid_len in out]
return (torch.tensor(all_token_ids, dtype=torch.long),
torch.tensor(all_segments, dtype=torch.long),
torch.tensor(valid_lens))
def _mp_worker(self, premise_hypothesis_tokens):
p_tokens, h_tokens = premise_hypothesis_tokens
self._truncate_pair_of_tokens(p_tokens, h_tokens)
tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)
token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \
* (self.max_len - len(tokens))
segments = segments + [0] * (self.max_len - len(segments))
valid_len = len(tokens)
return token_ids, segments, valid_len
def _truncate_pair_of_tokens(self, p_tokens, h_tokens):
# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置
while len(p_tokens) + len(h_tokens) > self.max_len - 3:
if len(p_tokens) > len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx]), self.labels[idx]
def __len__(self):
return len(self.all_token_ids)
下载完SNLI数据集后,实例化SNLIBERTDataset类来生成训练和测试样本。这些样本将在自然语言推断的训练和测试期间进行小批量读取。
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
'bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_layers=2, dropout=0.1, max_len=512, devices=devices)
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True,
num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
num_workers=num_workers)
3.微调BERT
用于自然语言推断的微调BERT只需要一个额外的多层感知机,该多层感知机由两个全连接层组成。这个多层感知机将特殊的“<cls>”词元的BERT表示进行了转换,该词元同时编码前提和假设的信息(为自然语言推断的三个输出):蕴涵、矛盾和中性。
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(256, 3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)
return self.output(self.hidden(encoded_X[:, 0, :]))
在BERT中,MaskLM类和NextSentencePred类在其使用的多层感知机中都有一些参数,这些参数是预训练BERT模型参数的一部分,这些参数仅用于计算预训练过程中的遮蔽语言模型损失和下一句预测损失。这两个损失函数与微调下游应用无关,因此当BERT微调时,MaskLM和NextSentencePred中采用的多层感知机的参数不会更新。
为了允许具有陈旧梯度的参数,标志ignore_stale_grad=True在step函数d2l.train_batch_ch13中被设置。通过该函数使用SNLI的训练集(train_iter)和测试集(test_iter)对net模型进行训练和评估。
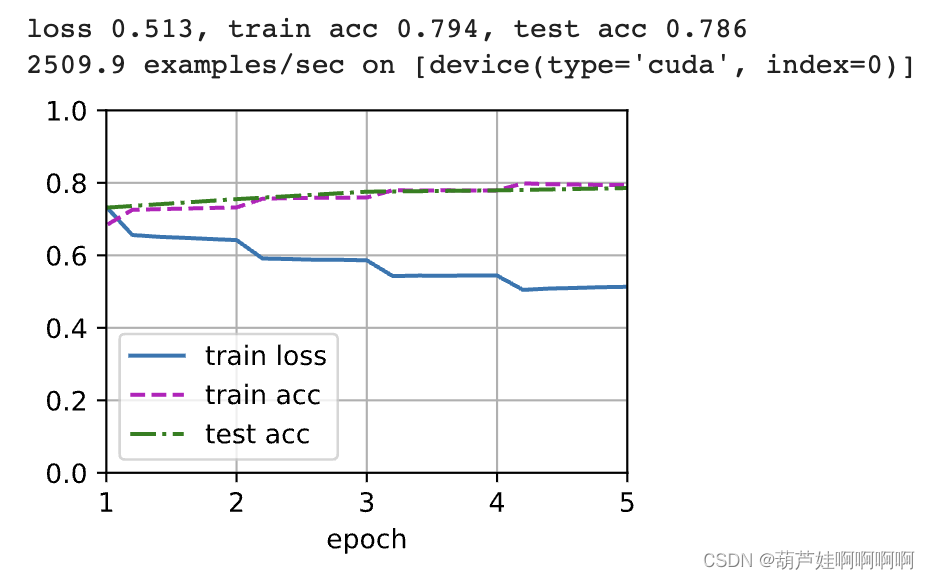
(Colab用GPU跑了近20分钟)
net = BERTClassifier(bert)
lr, num_epochs = 1e-4, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
边栏推荐
- 1-12Vmware新增SSH功能
- How to identify contractual issues
- 清华“神奇药水”登Nature:逆转干细胞分化,比诺奖成果更进一步,网友:不靠精子卵子就能创造生命了?!...
- 10 tf. data
- I want to know how to open an account through online stock? Is online account opening safe?
- 【思考】在买NFT的时候你在买什么?
- 现在券商的优惠开户政策是什么?现在在线开户安全么?
- 【力扣刷题】11.盛最多水的容器//42.接雨水
- This year, the AI score of college entrance examination English is 134. The research of Fudan Wuda alumni is interesting
- C语言读取数据
猜你喜欢

Net基于girdview控件实现删除与编辑行数据

Handwritten numeral recognition, run your own picture with the saved model

Solana capacity expansion mechanism analysis (2): an extreme attempt to sacrifice availability for efficiency | catchervc research

NFT contract basic knowledge explanation
【力扣刷题】单调栈:84. 柱状图中最大的矩形

NFT Platform Security Guide (1)

若依如何实现接口限流?

如何辨别合约问题

Oilfield exploration problems

Panoramic analysis of upstream, middle and downstream industrial chain of "dry goods" NFT
随机推荐
3 keras版本模型训练
STEPN 新手入门及进阶
Unlock the value of data fusion! Tencent angel powerfl won the "leading scientific and Technological Achievement Award" at the 2021 digital Expo
OpenSea上如何创建自己的NFT(Polygon)
Canvas three dot flashing animation
6 自定义层
What is the process of switching C # read / write files from user mode to kernel mode?
NFT transaction principle analysis (1)
Analyse panoramique de la chaîne industrielle en amont, en aval et en aval de la NFT « Dry goods»
SAP OData 开发教程 - 从入门到提高(包含 SEGW, RAP 和 CDP)
2 三种建模方式
牛客小白月赛50
Svg savage animation code
H5 close the current page, including wechat browser (with source code)
Anaconda3安装tensorflow 2.0版本cpu和gpu安装,Win10系统
Svg animation around the earth JS special effects
全面解析Discord安全问题
10 tf.data
若依如何实现接口限流?
5000 word analysis: the way of container security attack and defense in actual combat scenarios