当前位置:网站首页>如何选择分类模型的评价指标
如何选择分类模型的评价指标
2020-11-06 01:14:00 【人工智能遇见磐创】

作者|MUSKAN097 编译|VK 来源|Analytics Vidhya
简介

你已经成功地构建了分类模型。你现在该怎么办?你如何评估模型的性能,也就是模型在预测结果方面的表现。为了回答这些问题,让我们通过一个简单的案例研究了解在评估分类模型时使用的度量。
让我们通过案例研究深入了解概念
在这个全球化的时代,人们经常从一个地方旅行到另一个地方。由于乘客排队等候、办理登机手续、拜访食品供应商以及使用卫生间等设施,机场可能会带来风险。在机场追踪携带病毒的乘客有助于防止病毒的传播。

考虑一下,我们有一个机器学习模型,将乘客分为COVID阳性和阴性。在进行分类预测时,可能会出现四种类型的结果:
真正例(TP):当你预测一个观察值属于一个类,而它实际上属于那个类。在这种情况下,也就是预测为COVID阳性并且实际上也是阳性的乘客。

真反例(TN):当你预测一个观察不属于一个类,它实际上也不属于那个类。在这种情况下,也就是预测为非COVID阳性(阴性)并且实际上不是COVID阳性(阴性)的乘客。

假正例(FalsePositive,FP):当你预测一个观察值属于某个类,而实际上它并不属于该类时。在这种情况下,也就是预测为COVID阳性但实际上不是COVID阳性(阴性)的乘客。

假反例(FN):当你预测一个观察不属于一个类,而它实际上属于那个类。在这种情况下,也就是预测为非COVID阳性(阴性)并且实际上是COVID阳性的乘客。

混淆矩阵
为了更好地可视化模型的性能,这四个结果被绘制在混淆矩阵上。

准确度
对!你说得对,我们希望我们的模型能集中在真正的正例和反例。准确度是一个指标,它给出了我们的模型正确预测的分数。形式上,准确度有以下定义:
准确度=正确预测数/预测总数。

现在,让我们考虑平均每天有50000名乘客出行。其中有10个是COVID阳性。
提高准确率的一个简单方法是将每个乘客都归为COVID阴性。所以我们的混淆矩阵如下:

本案例的准确度为:
准确度=49990/50000=0.9998或99.98%

神奇!!这是正确的?那么,这真的解决了我们正确分类COVID阳性乘客的目的吗?
对于这个特殊的例子,我们试图将乘客标记为COVID阳性和阴性,希望能够识别出正确的乘客,我可以通过简单地将每个人标记为COVID阴性来获得99.98%的准确率。
显然,这是一种比我们在任何模型中见过的更精确的方法。但这并不能解决目的。这里的目的是识别COVID阳性的乘客。在这种情况下,准确度是一个可怕的衡量标准,因为它很容易获得非常好的准确度,但这不是我们感兴趣的。
所以在这种情况下,准确度并不是评估模型的好方法。让我们来看看一个非常流行的措施,叫做召回率。
召回率(敏感度或真正例率)
召回率给出你正确识别为阳性的分数。

现在,这是一项重要措施。在所有阳性的乘客中,你正确识别的分数是多少。回到我们以前的策略,把每个乘客都标为阴性,这样召回率为零。
Recall = 0/10 = 0
因此,在这种情况下,召回率是一个很好的衡量标准。它说,把每个乘客都认定为COVID阴性的可怕策略导致了零召回率。我们想最大限度地提高召回率。


作为对上述每个问题的另一个正面回答,请考虑COVID的每一个问题。每个人走进机场,模型都会给他们贴上阳性标签。给每位乘客贴上阳性标签是不好的,因为在他们登机前,实际调查每一位乘客所需的费用是巨大的。
混淆矩阵如下:

召回率将是:
Recall = 10/(10+0) = 1
这是个大问题。因此,结论是,准确度是个坏主意,因为给每个人贴上负面标签可以提高准确度,但希望召回率在这种情况下是一个很好的衡量标准,但后来意识到,给每个人贴上正面标签也会增加召回率。
所以独立的召回率并不是一个好的衡量标准。
还有一种测量方法叫做精确度
精确度
精确度给出了所有预测为阳性结果中正确识别为阳性的分数。

考虑到我们的第二个错误策略,即将每位乘客标记为阳性,其精确度将为:
Precision = 10 / (10 + 49990) = 0.0002
虽然这个错误的策略有一个好的召回值1,但它有一个可怕的精确度值0.0002。
这说明单纯的召回并不是一个好的衡量标准,我们需要考虑精确度。
考虑到另一种情况(这将是最后一种情况,我保证:P)将排名靠前的乘客标记为COVID阳性,即标记出患COVID的可能性最高的乘客。假设我们只有一个这样的乘客。这种情况下的混淆矩阵为:

精确度为:1/(1+0)=1
在这种情况下,精度值很好,但是让我们检查一下召回率:
Recall = 1 / (1 + 9) = 0.1
在这种情况下,精度值很好,但召回值较低。
| 场景 | 准确度 | 召回率 | 精确度 |
|---|---|---|---|
| 将所有乘客分类为阴性 | 高 | 低 | 低 |
| 将所有乘客分类为阳性 | 低 | 高 | 低 |
| 排名靠前的乘客标记为COVID阳性 | 高 | 低 | 低 |
在某些情况下,我们非常确定我们想要最大限度地提高召回率或精确性,而代价是其他人。在这个标记乘客的案例中,我们真的希望能正确地预测COVID阳性的乘客,因为不预测乘客的正确性是非常昂贵的,因为允许COVID阳性的人通过会导致传播的增加。所以我们更感兴趣的是召回率。
不幸的是,你不能两者兼得:提高精确度会降低召回率,反之亦然。这称为准确度/召回率权衡。
准确度/召回率权衡
一些分类模型输出的概率介于0和1之间。在我们将乘客分为COVID阳性和阴性的案例中,我们希望避免遗漏阳性的实际案例。特别是,如果一个乘客确实是阳性的,但我们的模型无法识别它,这将是非常糟糕的,因为病毒很有可能通过允许这些乘客登机而传播。所以,即使有一点怀疑有COVID,我们也要贴上阳性的标签。
所以我们的策略是,如果输出概率大于0.3,我们将它们标记为COVID阳性。

这会导致较高的召回率和较低的精确度。
考虑与此相反的情况,当我们确定乘客为阳性时,我们希望将乘客分类为阳性。我们将概率阈值设置为0.9,即当概率大于或等于0.9时,将乘客分类为正,否则为负。
所以一般来说,对于大多数分类器来说,当你改变概率阈值时,会在召回率和精确度之间进行权衡。

如果需要比较具有不同精确召回值的不同型号,通常可以方便地将精度和召回合并为一个度量。对的!!我们需要一个同时考虑召回率和精确度的指标来计算性能。
F1分数
它被定义为模型精度和召回率的调和平均值。

你一定想知道为什么调和平均而不是简单平均?我们使用调和平均值是因为它对非常大的值不敏感,不像简单的平均值。
比方说,我们有一个精度为1的模型,召回率为0给出了一个简单的平均值为0.5,F1分数为0。如果其中一个参数很低,第二个参数在F1分数中就不再重要了。F1分数倾向于具有相似精确度和召回率的分类器。
因此,如果你想在精确度和召回率之间寻求平衡,F1分数是一个更好的衡量标准。
ROC/AUC曲线
ROC是另一种常用的评估工具。它给出了模型在0到1之间每一个可能的决策点的敏感性和特异性。对于具有概率输出的分类问题,阈值可以将概率输出转换为分类。所以通过改变阈值,可以改变混淆矩阵中的一些数字。但这里最重要的问题是,如何找到合适的阈值?
对于每个可能的阈值,ROC曲线绘制假正例率与真正例率。
假正例率:被错误分类为正例的反例实例的比例。
真正例率:正确预测为正例的正例实例的比例。
现在,考虑一个低阈值。因此,在所有按升序排列的概率中,低于0.1的被认为是负的,高于0.1的都被认为是正的。选择阈值是自由的

但是如果你把你的门槛设得很高,比如0.9。

以下是同一模型在不同阈值下的ROC曲线。
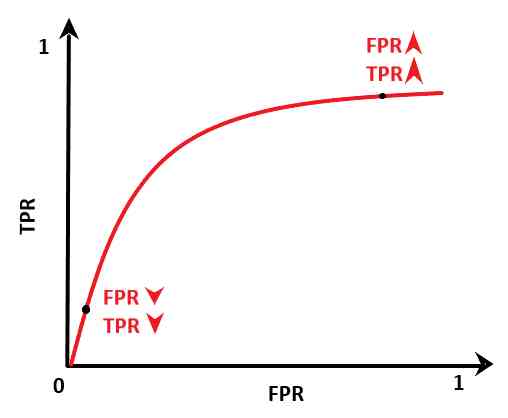
从上图可以看出,真正例率以更高的速率增加,但在某个阈值处,TPR开始逐渐减小。每增加一次TPR,我们就要付出代价—FPR的增加。在初始阶段,TPR的增加高于FPR
因此,我们可以选择TPR高而FPR低的阈值。
现在,让我们看看TPR和FPR的不同值告诉了我们关于这个模型的什么。

对于不同的模型,我们会有不同的ROC曲线。现在,如何比较不同的模型?从上面的曲线图可以看出,曲线在上面代表模型是好的。比较分类器的一种方法是测量ROC曲线下的面积。

AUC(模型1)>AUC(模型2)>AUC(模型2)
因此模型1是最好的。
总结
我们了解了用于评估分类模型的不同度量。何时使用哪些指标主要取决于问题的性质。所以现在回到你的模型,问问自己你想要解决的主要目的是什么,选择正确的指标,并评估你的模型。
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4704944
边栏推荐
猜你喜欢






随机推荐
让前端攻城师独立于后端进行开发: Mock.js
【Flutter 實戰】pubspec.yaml 配置檔案詳解
面经手册 · 第16篇《码农会锁,ReentrantLock之公平锁讲解和实现》
ETCD核心機制解析
50+开源项目正式集结完毕,百万开发者正在投票
keras model.compile损失函数与优化器
用git2consul从Git同步配置到Consul
Vue 3 响应式基础
直接保存文件至 Google Drive 并用十倍的速度下载回来
看完这篇就看懂了很多webpack脚手架
Using tensorflow to forecast the rental price of airbnb in New York City
Polkadot系列(二)——混合共识详解
UML类图还不懂?来看看这版乡村爱情类图,一把学会!
Working principle of gradient descent algorithm in machine learning
梯度下降算法在机器学习中的工作原理
htmlcss
字符串的常见算法总结
自然语言处理-错字识别(基于Python)kenlm、pycorrector
如何选择分类模型的评价指标
从零学习人工智能,开启职业规划之路!