当前位置:网站首页>Yolox backbone -- implementation of cspparknet
Yolox backbone -- implementation of cspparknet
2022-06-24 09:05:00 【Said the Shepherdess】
YOLOX The backbone feature extraction network used is CSPDarknet, As shown in the box on the left of the following figure .

picture source : Pytorch Build your own YoloX Target detection platform (Bubbliiiing Deep learning course )_ Bili, Bili _bilibili
CSPDarknet The main points of the are summarized as follows .
1. Focus Network structure
Focus The specific operation of the structure is , The direction of rows and columns in an image is extracted every pixel , Form a new characteristic layer , Each image can be reorganized into 4 Characteristic layers , And then 4 Feature layers are stacked , Expand the input channel to 4 times . The stacked feature layer is relative to the original 3 The channel becomes 12 passageway , As shown in the figure below :

PyTorch The code implementation is as follows :
class Focus(nn.Module):
"""Focus width and height information into channel space."""
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
# shape of x (b,c,w,h) -> y(b,4c,w/2,h/2)
patch_top_left = x[..., ::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_left = x[..., 1::2, ::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat(
(
patch_top_left,
patch_bot_left,
patch_top_right,
patch_bot_right,
),
dim=1,
)
return self.conv(x)
2. Residual network Residual
CSPDarknet The residual network in is divided into two branches , Do a trunk branch 1x1 Convolution sum once 3x3 Convolution , The residual edge part is not processed , It is equivalent to directly combining the input and output of the trunk .
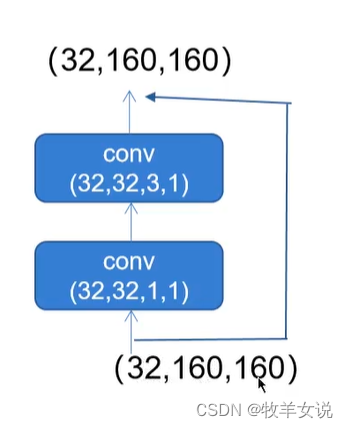
The code is as follows ,
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(
self,
in_channels,
out_channels,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
Among them DWConv refer to Depthwise Convolution, In lightweight networks such as YOLOX-Nano and YOLOX-Tiny use .
DWConv and BaseConv Is defined as follows :
class DWConv(nn.Module):
"""Depthwise Conv + Conv"""
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = BaseConv(
in_channels,
in_channels,
ksize=ksize,
stride=stride,
groups=in_channels,
act=act,
)
self.pconv = BaseConv(
in_channels, out_channels, ksize=1, stride=1, groups=1, act=act
)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class BaseConv(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))3. CSPNet Network structure
CSPNet Structure and Residual It's kind of like , It is also divided into two parts , The trunk part is used to stack the residual blocks , The other part is like the residual edge , After a small amount of processing, it is connected to the last part of the trunk . Here is the following :

This is from the Internet .
The rightmost part of the figure above is CSPNet Decomposition structure of , among ,Bottleneck The number of can be configured according to different layers . The code implementation of this structure is as follows :
class CSPLayer(nn.Module):
"""C3 in yolov5, CSP Bottleneck with 3 convolutions"""
def __init__(
self,
in_channels,
out_channels,
n=1,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
"""
Args:
in_channels (int): input channels.
out_channels (int): output channels.
n (int): number of Bottlenecks. Default value: 1.
"""
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
# The trunk part is convoluted for the first time
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# The first convolution of the large residual edge part
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# Convolute the stacked results , Note after stacking , Input channels Doubled
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
# Build... According to the number of cycles Bottleneck Residual structure
module_list = [
Bottleneck(
hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act
)
for _ in range(n)
]
self.m = nn.Sequential(*module_list)
def forward(self, x):
# X_1 It is the trunk part
x_1 = self.conv1(x)
# x_2 Is the large residual side part
x_2 = self.conv2(x)
# In the main part, the residual structure stack is used for feature extraction
x_1 = self.m(x_1)
# The trunk part and the large residual side part are stacked
x = torch.cat((x_1, x_2), dim=1)
# Convolute the stacking results
return self.conv3(x)
4. SiLU Activation function
SiLU The activation function is Signoid and ReLU Improved version , Having a lower bound and no upper bound 、 smooth 、 Nonmonotonic properties , The effect on the deep model is better than ReLU. Something like this :

The implementation code is as follows :
class SiLU(nn.Module):
"""export-friendly version of nn.SiLU()"""
@staticmethod
def forward(x):
return x * torch.sigmoid(x)5. SPP structure
SPP yes Spatial Pyramid Pooling Abbreviation . stay CSPDarknet in , Different pooled core sizes are used MaxPool Feature extraction , To improve the feeling of the network . And in YOLOv4 Lieutenant general SPP Use in FPN It's different inside , stay YOLOX in ,SPP The module is used in the backbone feature extraction network . The schematic diagram is as follows :

The implementation code is as follows :
class SPPBottleneck(nn.Module):
"""Spatial pyramid pooling layer used in YOLOv3-SPP"""
def __init__(
self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"
):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList(
[
nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
for ks in kernel_sizes
]
)
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
6. CSPDarknet Complete implementation
Okay ,CSPDarknet That's all , Next , The above sub modules need to be assembled into the final CSPDarknet. The code is as follows :
class CSPDarknet(nn.Module):
def __init__(
self,
dep_mul,
wid_mul,
out_features=("dark3", "dark4", "dark5"),
depthwise=False,
act="silu",
):
super().__init__()
assert out_features, "please provide output features of Darknet"
self.out_features = out_features
Conv = DWConv if depthwise else BaseConv
# The input image size is 640x640x3
# The initial basic channel is 64
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
# utilize focus Network structure for feature extraction
# 640x640x3 -> 320x320x12 -> 320x320x64
self.stem = Focus(3, base_channels, ksize=3, act=act)
# dark2
# Conv: 320x320x64 -> 160x160x128
# CSPLayer: 160x160x128 -> 160x160x128
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2, act=act),
CSPLayer(
base_channels * 2,
base_channels * 2,
n=base_depth,
depthwise=depthwise,
act=act,
),
)
# dark3
# Conv: 160x160x128 -> 80x80x256
# CSPLayer: 80x80x256 -> 80x80x256
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2, act=act),
CSPLayer(
base_channels * 4,
base_channels * 4,
n=base_depth * 3,
depthwise=depthwise,
act=act,
),
)
# dark4
# Conv: 80x80x256 -> 40x40x512
# CSPLayer: 40x40x512 -> 40x40x512
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2, act=act),
CSPLayer(
base_channels * 8,
base_channels * 8,
n=base_depth * 3,
depthwise=depthwise,
act=act,
),
)
# dark5
# Conv: 40x40x512 -> 20x20x1024
# SPPConv: 20x20x1024 -> 20x20x1024
# CSPLayer: 20x20x1024 -> 20x20x1024
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2, act=act),
SPPBottleneck(base_channels * 16, base_channels * 16, activation=act),
CSPLayer(
base_channels * 16,
base_channels * 16,
n=base_depth,
shortcut=False,
depthwise=depthwise,
act=act,
),
)
def forward(self, x):
outputs = {}
x = self.stem(x)
outputs["stem"] = x
x = self.dark2(x)
outputs["dark2"] = x
# dark3 The output of is 80x80x256 Effective feature layer
x = self.dark3(x)
outputs["dark3"] = x
# dark4 The output of is 40x40x512 Effective feature layer
x = self.dark4(x)
outputs["dark4"] = x
# dark5 The output of is 20x20x1024 Effective feature layer
x = self.dark5(x)
outputs["dark5"] = x
return {k: v for k, v in outputs.items() if k in self.out_features}边栏推荐
- PM2 deploy nuxt3 JS project
- 【LeetCode】415. String addition
- Jenkins is deployed automatically and cannot connect to the dependent service [solved]
- 十二、所有功能实现效果演示
- [MySQL from introduction to mastery] [advanced part] (I) character set modification and underlying principle
- 数组相向指针系列
- 双指针模拟
- A tip to read on Medium for free
- [Niuke] length of the last word of HJ1 string
- MySQL - SQL statement
猜你喜欢

Prompt code when MySQL inserts Chinese data due to character set problems: 1366

110. balanced binary tree recursive method

Mysql数据(Liunx环境)定时备份
MySQL data (Linux Environment) scheduled backup

4274. suffix expression

A tip to read on Medium for free

Data midrange: detailed explanation of the technical stack of data acquisition and extraction

OpenCV每日函数 结构分析和形状描述符(7) 寻找多边形(轮廓)/旋转矩形交集

Ebanb B1 Bracelet brush firmware abnormal interrupt handling
![[noi Simulation Competition] send (tree DP)](/img/5b/3beb9f5fdad00b6d5dc789e88c6e98.png)
[noi Simulation Competition] send (tree DP)
随机推荐
JS to find and update the specified value in the object through the key
Transplantation of xuantie e906 -- fanwai 0: Construction of xuantie c906 simulation environment
every()、map()、forEarch()方法。数组里面有对象的情况
IDEA另起一行快捷键
Linux (centos7.9) installation and deployment of MySQL Cluster 7.6
Qingcloud based R & D cloud solution for geographic information enterprises
One article explains in detail | those things about growth
1528. rearrange strings
Digital cloud released the 2022 white paper on digital operation of global consumers in the beauty industry: global growth solves marketing problems
数据中台:数据中台全栈技术架构解析,附带行业解决方案
【Pytorch基础教程31】YoutubeDNN模型解析
【NOI模拟赛】给国与时光鸡(构造)
Qingcloud based "real estate integration" cloud solution
uniapp 开发多端项目如何配置环境变量以及区分环境打包
华为路由器:GRE技术
Camera projection matrix calculation
Huawei Router: GRE Technology
KaFormer个人笔记整理
数组相向指针系列
Jenkins is deployed automatically and cannot connect to the dependent service [solved]