当前位置:网站首页>Evolution of software system architecture
Evolution of software system architecture
2022-06-27 10:06:00 【Hua Weiyun】
A mature system , Not perfect in every way from the beginning , I won't consider what high concurrency , High availability problem , But over time , The problems of the existing architecture will gradually appear . For example, the number of users has increased , Increasing traffic , In the process , New problems will continue to appear , And in order to solve these problems , Software technology and architecture will change significantly , Systems with different business characteristics will have their own focus , What websites like Taobao need to solve is massive commodity search Order payment and other issues . Like tencent To solve the problem of implementing message transmission for hundreds of millions of users . Each business has its own different system architecture .
With Java Web For example The e-commerce system has several simple business modules , Suppose there are now : User module 、 Commodity module 、 Payment module
Stage 1 、 Monomer architecture
At the beginning of the website , Often run all programs on a single machine , All functions are in one jar in , Database and application are on one server , The first thing to pay attention to is efficiency , In the early days of the Internet , When the number of users is small , Monomer architecture can also support the use of .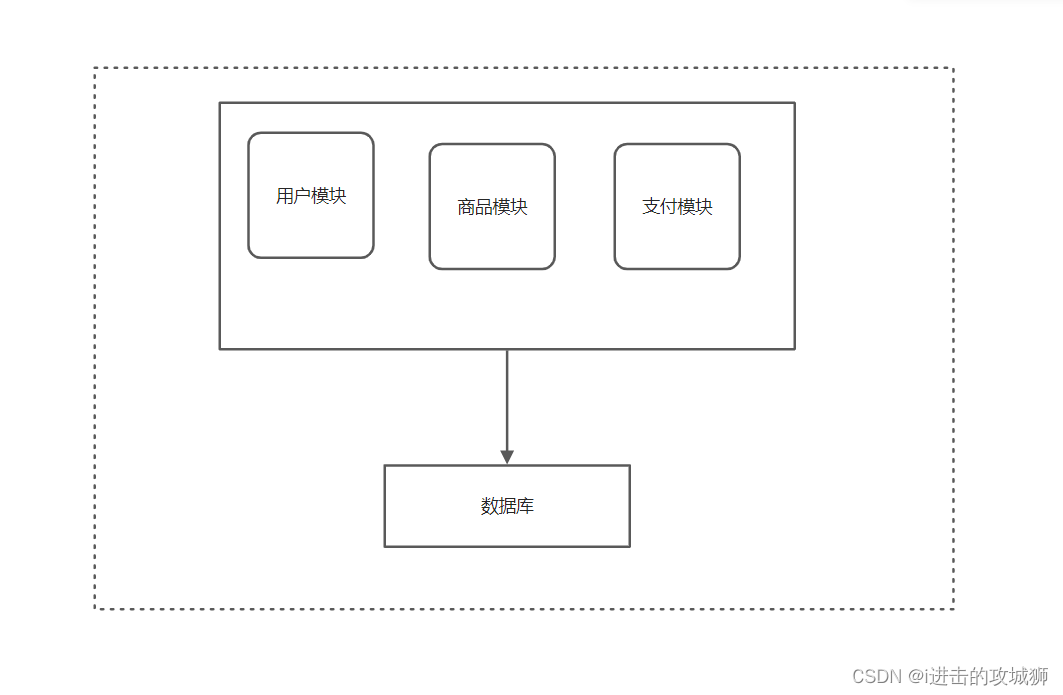
Stage two 、 The application server is separated from the database server
With the launch of the website , The increase in traffic , The performance requirements of the server are also increasing ,web The server is mainly used to handle network connections and resource requests , Therefore, the requirement is high bandwidth , High concurrency , Yes CPU In fact, the requirements are not high , High memory requirements , However web The optimization done by the server is obviously not suitable for the database server . The main responsibility of the database server is to handle SQL sentence , Manage data stored on disk , Requires a large number of disks IO, Very high requirements for buffer pool , All in all ,web The location of server and database server is different , The optimization points are also different , Forcibly putting them together will seriously affect the performance of both , therefore , gradual , Servers and databases , Select separate deployment .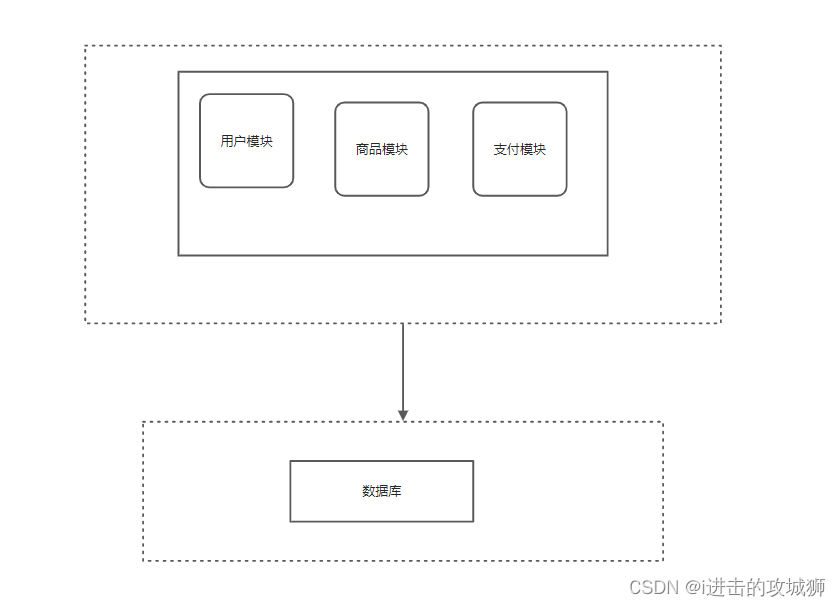
Stage three Application server cluster , Application server load is tight
Over time , Website traffic continues to increase , The performance of a single server can no longer meet the requirements , If the database server does not reach the bottleneck , We can add application servers , Through the application server colony Divert the user's requests to each server , So as to improve the load capacity , We can use Nignx Reverse proxy of , Load balancing , To make the user's request reach each cluster server . There is no direct interaction between servers at this time , They interact with each other through the database .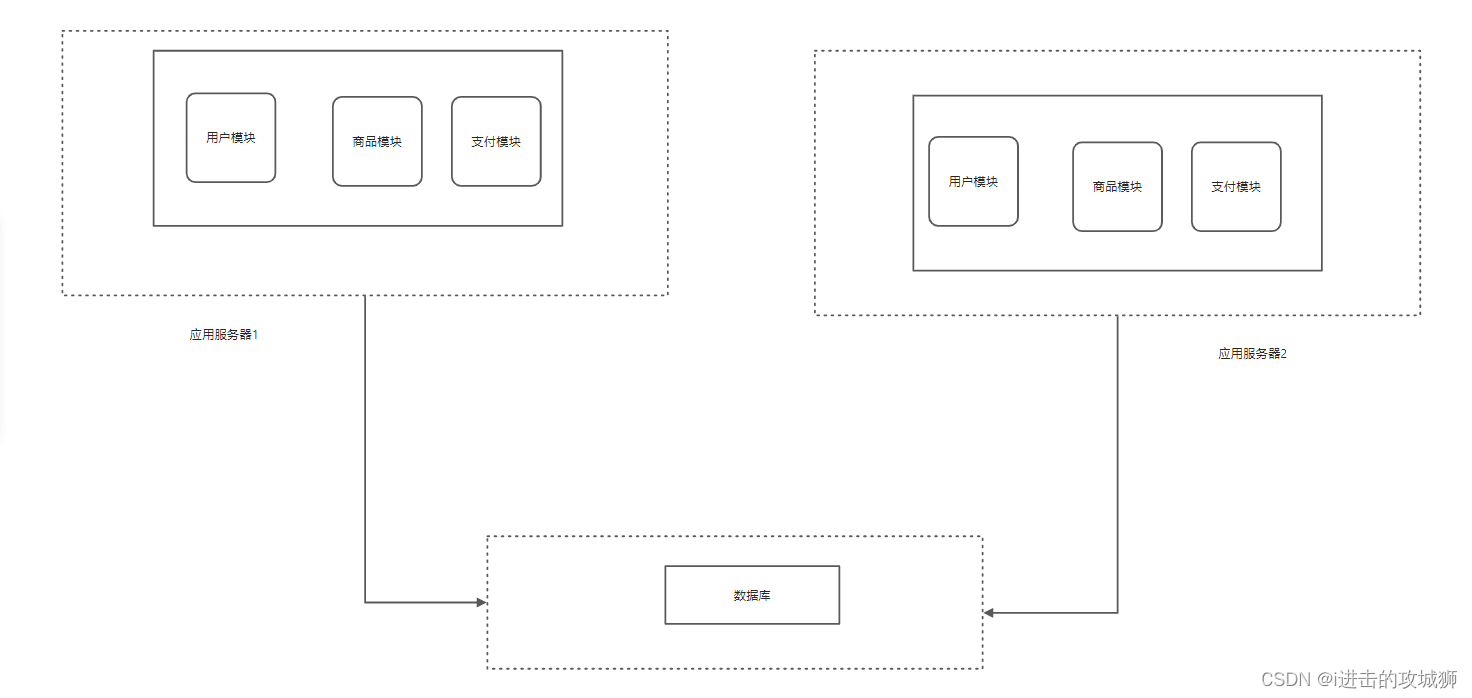
Stage four , The pressure on the database is increasing , The database implements read-write separation
Architecture evolution here is not the end . We have improved the performance of the application layer through the above methods , But the load on the database is too large , In order to improve the performance of data library With the front idea Let's do the same . We began to consider deploying the database to the cluster , Then for the database request , Load on multiple machines respectively . But after the database is clustered , It also needs to be solved, such as data synchronization 、 Read / write separation 、 Problems such as sub database and sub table .

Stage five The pressure of using search engine link degree database
If the database is a reading database , Trying to fuzzy query is not efficient , Website search like e-commerce is a very core function , After several times of reading and writing separation, this problem can not be effectively solved , Then we need to introduce search engine at this time , Using search engine can greatly improve query efficiency , But there are also problems , For example, index maintenance 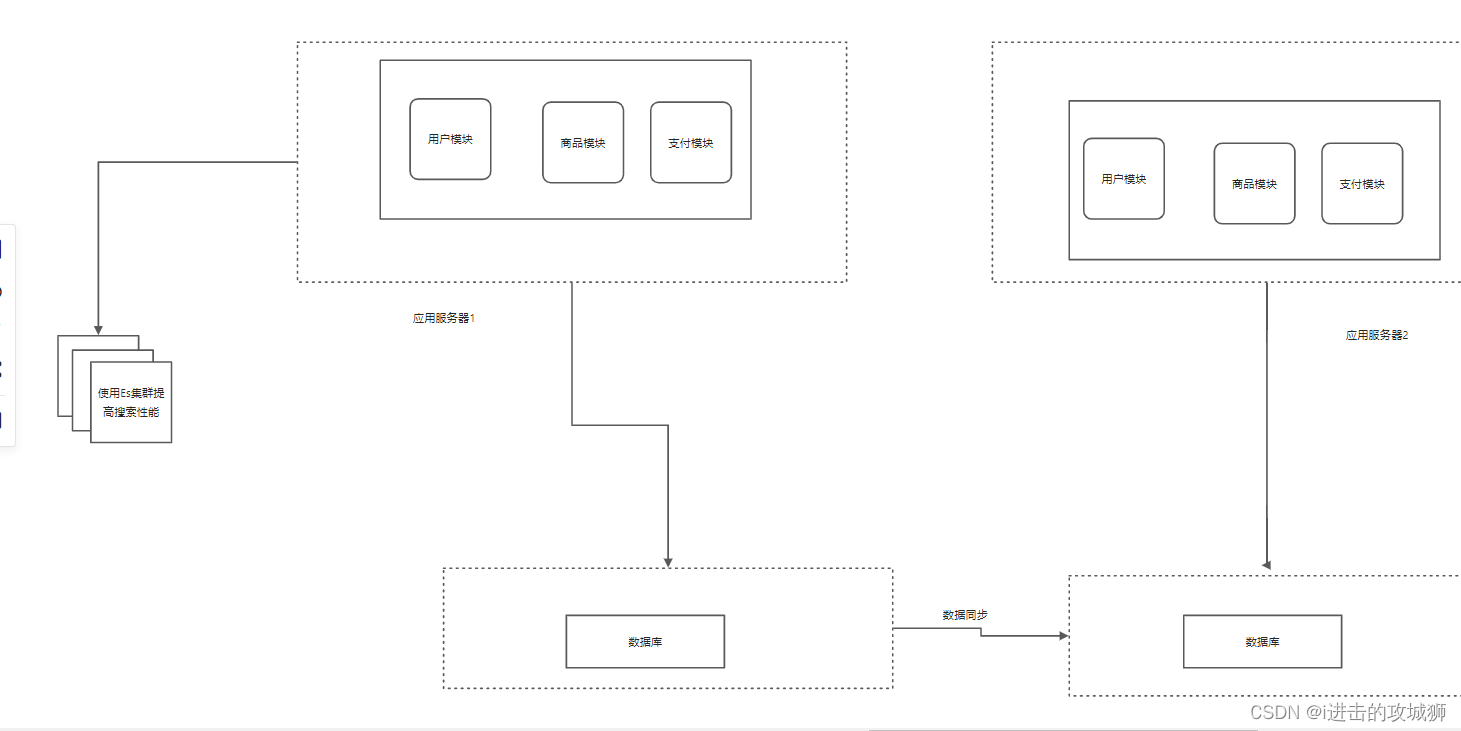
Stage six Introduce database caching mechanism ( For example, hot data )
As the number of visitors continues to increase , Gradually, many users access the same part of data , For these hot data, it is not necessary to query the database every time , We can use caching technology, such as memcache redis As an application layer cache , In some other scenarios Some of our to users ip Limited access frequency , So it's not appropriate to put it in memory , It's always too troublesome to put it in the database , You can use it NoSql For example mongDB To replace traditional databases 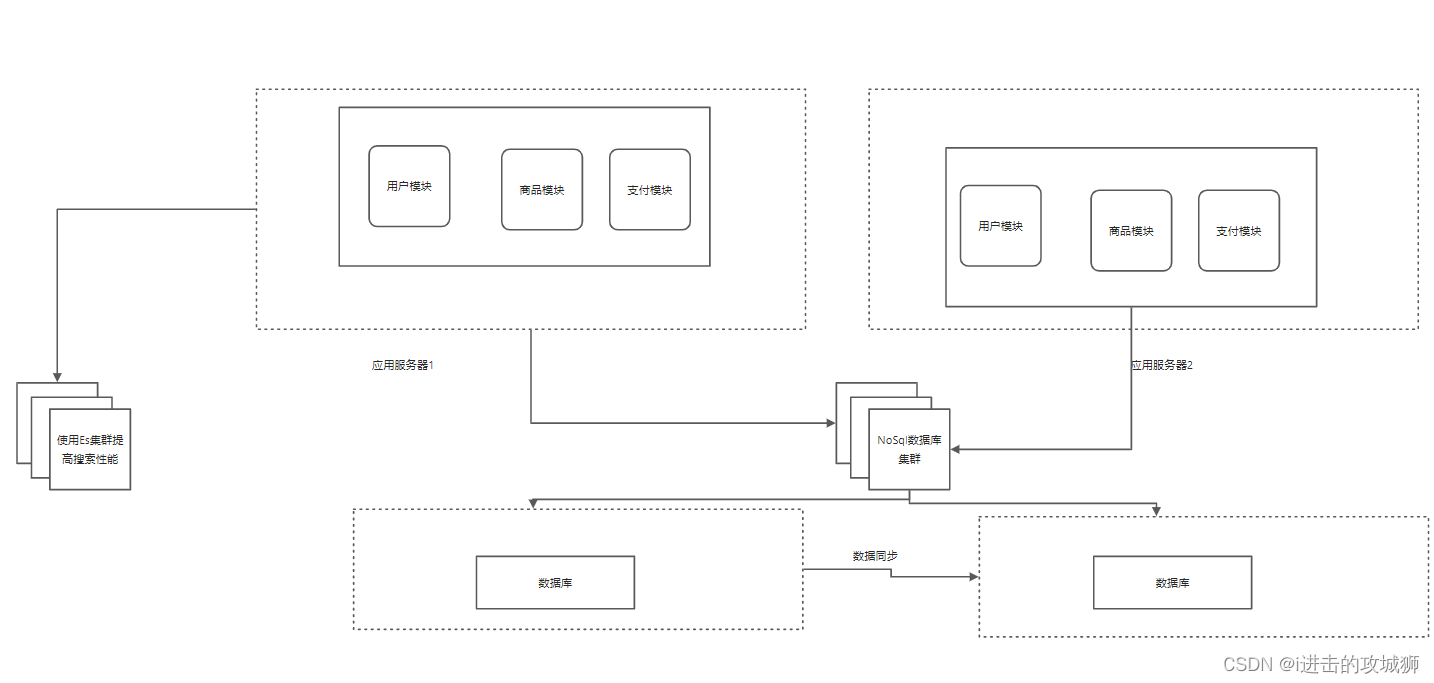
Stage seven , Horizontal and vertical splitting of the database
In the process of website evolution , user goods The transaction data is still in the same database , Despite taking cache The way of separation of reading and writing , But the pressure on the database continues to increase , The bottleneck of database is still a big problem , Therefore, we consider splitting data vertically and horizontally
Split Vertically : Split different business data in the database into different databases
Horizontal split : Split the data of the same table into different databases .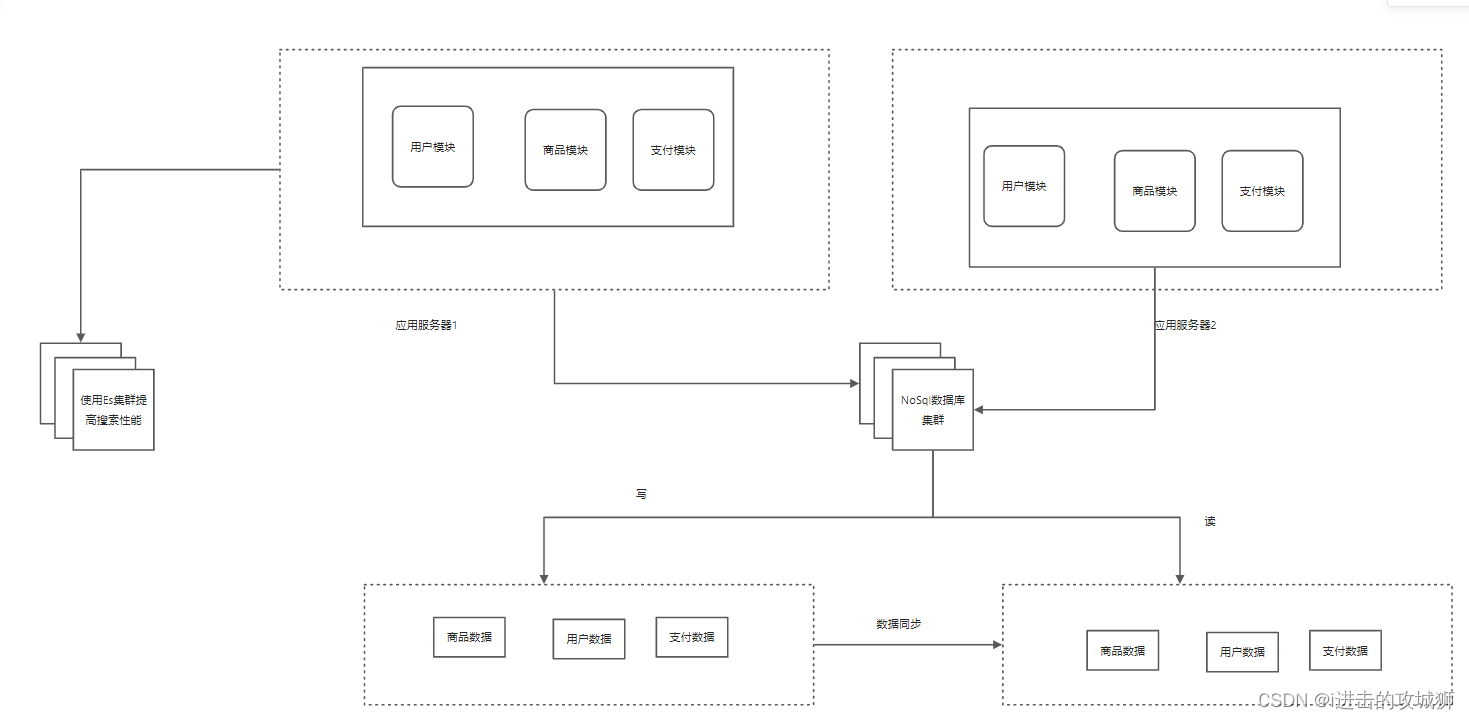
Stage eight Micro service splitting
As the business grows , More and more applications are under pressure . Project scale As the business grows , More and more applications lead to more and more pressure on the server , If all functions are written in a service , There are many inconveniences , For example, the project only needs to modify one line of code , You need to rebuild the whole system 、 test , Then deploy the whole system or, for example, there are too many business visits to the product description, resulting in the service hanging up , All other services also hang up , therefore , Full of , Microservice architecture is becoming popular .
Split according to the system business , Separate each business into a project , Can run separately , A system that is put together as a whole , Each microservice is basically an independent project , And the R & D team corresponding to their own independent projects is also basically independent , Such a structure ensures the parallel development of microservices , And each iteration is fast , Not because all R & D is invested in a single project , This creates a bottleneck in the development phase . Independence of the development phase , It ensures that the research and development of microservices can be carried out efficiently . Even if one of the services goes wrong , It will not affect the operation of other services .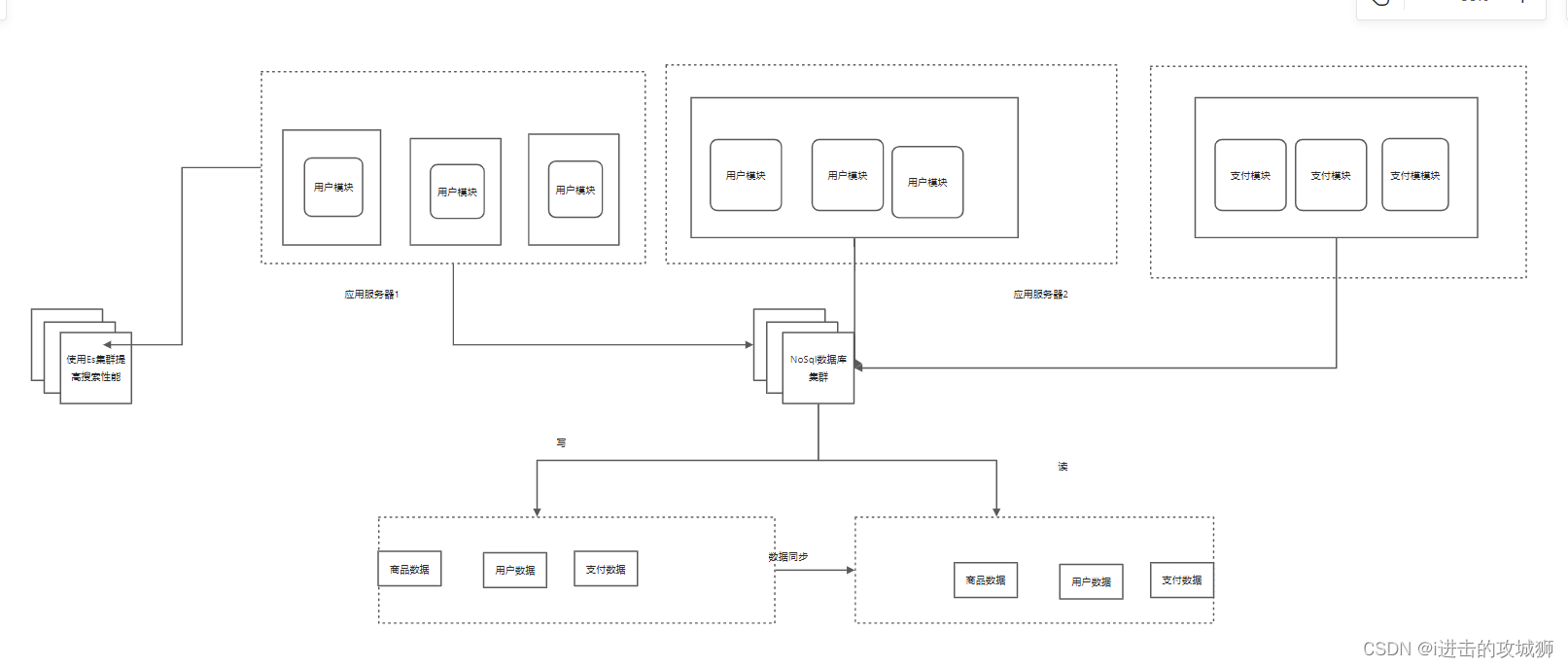
Of course, a brief introduction to this knowledge , With the deepening of system business , The system may also introduce more components , for instance MQ,HABS wait . Not only redis, and es.
Of course, the development of the Internet continues , Microservice architecture is not the end , The optimization and evolution of architecture are still going on .
边栏推荐
猜你喜欢







![[system design] proximity service](/img/02/57f9ded0435a73f86dce6eb8c16382.png)
随机推荐
手机影像内卷几时休?
Oracle连接MySQL报错IM002
leetcode:968. Monitor the binary tree [tree DP, maintain the three states of each node's subtree, it is very difficult to think of the right as a learning, analogous to the house raiding 3]
. Net
js中的数组对象
感应电机直接转矩控制系统的设计与仿真(运动控制matlab/simulink)
R language plot visualization: visualize the normalized histograms of multiple data sets, add density curve KDE to the histograms, set different histograms to use different bin sizes, and add edge whi
BufferedWriter 和 BufferedReader 的使用
10 common website security attack means and defense methods
【面经】云泽科技
Easy to understand Laplace smoothing of naive Bayesian classification
unity--newtonsoft.json解析
运维一线工作常用shell脚本再整理
【OpenCV 例程200篇】212. 绘制倾斜的矩形
浅析基于边缘计算的移动AR实现(中)
别再用 System.currentTimeMillis() 统计耗时了,太 Low,StopWatch 好用到爆!
mongodb跨主机数据库拷贝以及常用命令
【STM32】HAL库 STM32CubeMX教程十二—IIC(读取AT24C02 )
前馈-反馈控制系统设计(过程控制课程设计matlab/simulink)
leetcode待做题目