当前位置:网站首页>Target segmentation for 10000 frames of video, with less than 1.4GB of video memory | eccv2022
Target segmentation for 10000 frames of video, with less than 1.4GB of video memory | eccv2022
2022-07-23 13:23:00 【Xixiaoyao】

writing | bright and quick From the Aofei temple
Source | qubits | official account QbitAI
Why , How good Fujiwara Qianhua , All of a sudden “ High temperature red version ”?

This big purple hand , Is mieba alive ??

If you think the above effects are just coloring the object later , That was really AI Cheated .
These strange colors , In fact, it is the representation of video object segmentation .
but u1s1, This effect is really indistinguishable for a time .
Whether it's cute girl's flying hair :

Or a towel that changes its shape 、 Objects block back and forth :
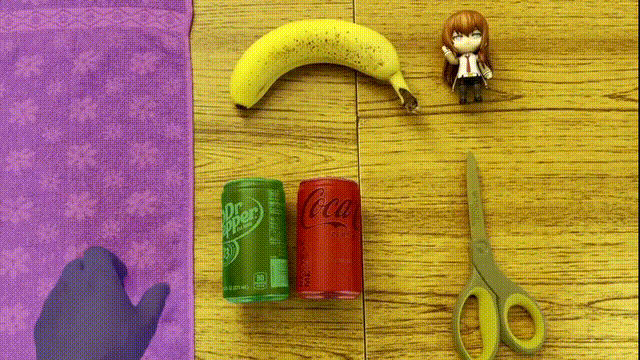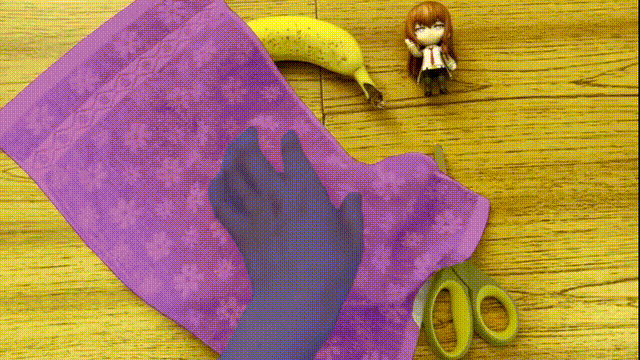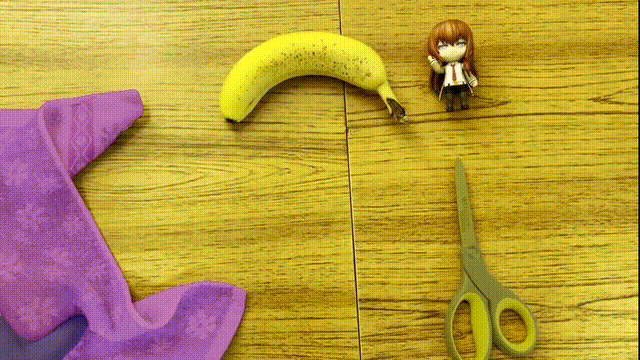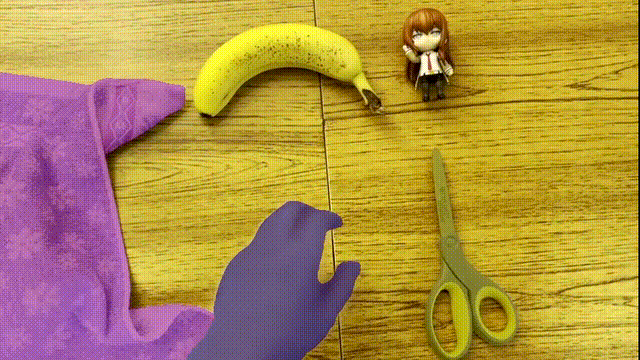
AI The segmentation of the target can be called perfect , It seems that the color “ weld ” Go up .
It's not just high-precision segmentation of targets , This method can also handle more than 10000 frame In the video .
And the segmentation effect is always maintained at the same level , The second half of the video is still silky and fine .

What's more surprising is , This method is right GPU Not very demanding .
The researchers said that during the experiment , This method consumes GPU Memory never exceeds 1.4GB.
Need to know , Current similar methods based on attention mechanism , You can't even process more than... On ordinary consumer graphics cards 1 Minute video .
This is the University of Illinois Urbana - A long video target segmentation method recently proposed by scholars at the University of champagne XMem.
At present has been ECCV 2022 receive , The code is open source, too .
Such a silky effect , still Reddit Attract many netizens to watch , Heat up to 800+.

Netizens are joking :
Why paint your hands purple ?
Who knows if mieba has a hobby in computer vision ?

Imitate human memory
At present, there are many video object segmentation methods , But they are either slow to process , Or yes GPU Demand is high , Or the accuracy is not high enough .
And the method proposed in this paper , It can be said that the above three aspects are taken into account .
It can not only quickly segment long videos , The number of frames can reach 20FPS, At the same time, in ordinary GPU I can finish it .
What's special about it is , It is inspired by human memory patterns .
1968 year , Psychologists Atkinson and schifflin proposed Multiple storage model (Atkinson-Shiffrin memory model).
The model says , Human memory can be divided into 3 Patterns : Instantaneous memory 、 Short term memory and long term memory .
Refer to the above mode , Researchers AI The framework is also divided into 3 Memory mode . Namely :
Instant memory updated in time
High resolution working memory
Dense long-term memory .

among , The transient memory is updated every frame , To record the image information in the picture .
Working memory collects picture information from transient memory , The update frequency is every r Frame once .
When the working memory is saturated , It will be compressed and transferred to long-term memory .
When the long-term memory is saturated , Will forget outdated features over time ; Generally speaking, this will be saturated after processing thousands of frames .
thus ,GPU Memory will not be insufficient due to the passage of time .
Usually , Segmentation of the video target will give the image of the first frame and the target object mask , Then the model will track the relevant targets , Generate corresponding masks for subsequent frames .
The specific term ,XMem The process of processing a single frame is as follows :

Whole AI Frame by 3 An end-to-end convolution network .
One Query encoder (Query encoder) Used to track, extract and query specific image features .
One decoder (Decoder) Responsible for obtaining the output of the memory reading step , To generate an object mask .
One Value encoder (Value encoder) You can combine the image with the mask of the target , So as to extract new memory characteristic values .
The characteristic value extracted by the final value encoder will be added to the working memory .
From the experimental results , This method is applied to short video and long video , It's all done SOTA.

When processing long videos , As the number of frames increases ,XMem The performance of has not decreased .

Research team
One of the authors is Chinese Ho Kei (Rex) Cheng.

He graduated from Hong Kong University of science and Technology , At the University of Illinois, Urbana - A doctoral degree at the University of champagne .
The research direction is computer vision .
Many of his papers have been CVPR、NeurIPS、ECCV Wait for the top to receive .
Another author is Alexander G. Schwing.

He is now at the University of Illinois, Urbana - Assistant professor at the University of champagne , He graduated from the Federal Institute of technology in Zurich .
His research interests are machine learning and computer vision .
Address of thesis :
https://arxiv.org/abs/2207.07115
GitHub:
https://github.com/hkchengrex/XMem
Backstage reply key words 【 The group of 】
Join selling cute house NLP、CV、 Search promotion and job search discussion groups
边栏推荐
- The unity model is displayed in front of the UI, and the UI behind it jitters
- [jzof] 08 next node of binary tree
- 【JZOF】11旋转数组的最小数字
- Successful joint commissioning of Vientiane Aoke and CoDeSys Technology
- Image processing image feature extraction and description
- Evaluation of classification model
- “算力猛兽”浪潮NF5468A5 GPU服务器开放试用免费申请
- OpenCV 视频操作
- 射击 第 1-3 课:图像精灵
- 第十天笔记
猜你喜欢


![[actf2020 freshman competition]backupfile 1](/img/4c/cefb3660a176fee7fde6b0e38e6f4b.png)





随机推荐
Intercept the specified range data set from list < map >
Beifu PLC and C transmit int array type variables through ads communication
Quelle est la raison pour laquelle la plate - forme easygbs ne peut pas lire l'enregistrement vidéo et a un phénomène de streaming répété rtmp?
倍福PLC和C#通过ADS通信传输int数组类型变量
JVM detailed parsing
JVM内存模型简介
Shooting lesson 1-3: image Sprite
Opencv image processing (Part 1): geometric transformation + morphological operation
UI自动化
Current limiting based on redis+lua
Beifu PLC and C transmit structure type variables through ads communication
Beifu PLC and C # regularly refresh IO through ads communication
Record a reptile question bank
射击 第 1-01 课:入门
软件测试岗位饱和了?自动化测试是新一代‘offer’技能
Outlook 教程,如何在 Outlook 中切换日历视图、创建会议?
倍福PLC--C#ADS通信以通知的方式读取变量
High voltage MOS tube knx42150 1500v/3a is applied to frequency converter power supply inverter, etc
倍福PLC和C#通过ADS通信传输Bool数组变量
倍福和C#通过ADS通信传输Real类型