当前位置:网站首页>anchor free yolov1
anchor free yolov1
2022-07-23 23:13:00 【TJMtaotao】
1. YOLO The core idea of
YOLO The core idea is to use the whole graph as the input of the network , Return directly to the output layer bounding box The location and bounding box Category .
If I remember correctly faster RCNN The whole picture is also used as input directly in , however faster-RCNN Overall, it still adopts RCNN That kind of proposal+classifier Thought , Just to extract proposal The steps are put in CNN Implemented in the .
2.YOLO Implementation method
- Divide an image into SxS Grid (s) (grid cell), If a object Center of In this grid , Then this grid is responsible for predicting this object.

Each grid should forecast B individual bounding box, Every bounding box In addition to going back to where you are , And with a prediction confidence value .
This confidence Represents the predicted box contains object Of Degree of confidence And this box Predicted How accurate is it Dual information , The value is calculated as follows :
among If there is object Fall on one grid cell in , The first one is 1, Otherwise take 0. The second is the prediction bounding box And the actual groundtruth Between IoU value .Every bounding box To predict (x, y, w, h) and confidence common 5 It's worth , Each grid also predicts a category information , Write it down as C class . be SxS Grid (s) , Every grid should predict B individual bounding box And predict C individual categories. Output is S x S x (5*B+C) One of the tensor.
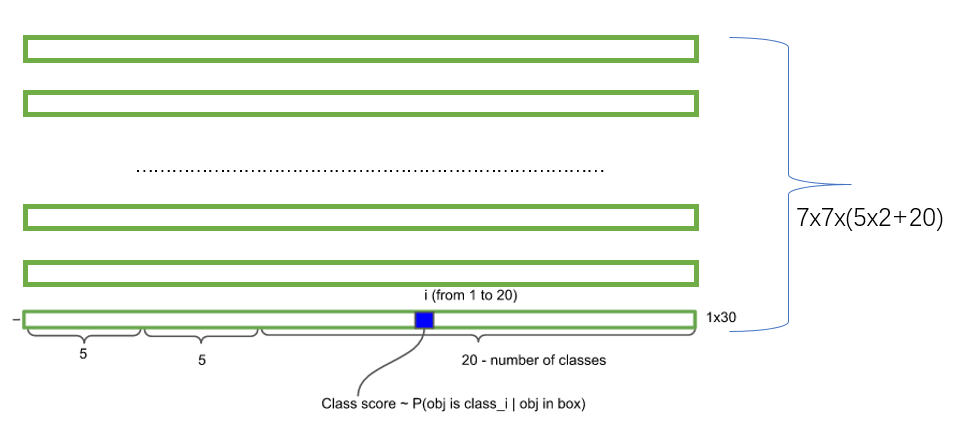
Be careful :class Information is for each grid ,confidence The message is for each bounding box Of .Illustrate with examples : stay PASCAL VOC in , The image input is 448x448, take S=7,B=2, Altogether 20 Categories (C=20). Then the output is 7x7x30 One of the tensor.
The whole network structure is shown in the figure below :

The network structure draws lessons from GoogLeNet .24 Convolution layers ,2 A full link layer .( use 1×1 reduction layers Following the 3×3 convolutional layers replace Goolenet Of inception modules )

- stay test When , Predicted by each grid class Information and bounding box Predicted confidence Information multiplication , You get everything bounding box Of class-specific confidence score:

The first term on the left of the equation is Category information of each grid prediction , The second and third item is Every bounding box Predicted confidence. This product is encode Predicted box The probability of belonging to a certain category , It's time to box Accuracy information .
- Get each box Of class-specific confidence score in the future , Set the threshold , Filter out the low score boxes, Yes reserved boxes Conduct NMS Handle , And you get the final test results .
3.YOLO Implementation details
Every grid Yes 30 dimension , this 30 Weizhong ,8 It's a return box Coordinates of ,2 Weishi box Of confidence, also 20 Dimensions are categories .
Its Coordinates in x,y Use the corresponding grid offset Normalize to 0-1 Between ,w,h With images width and height Normalize to 0-1 Between .
In implementation , The main thing is How to design the loss function , Give Way These three aspects are well balanced . The author simply and roughly adopted sum-squared error loss To do it .
There are several problems in this way :
First of all ,8 Dimensional localization error and 20 Dimensional classification error It's obviously unreasonable to be equally important ;
second , If there is no object( There are many grids in a picture ), So I'm going to put box Of confidence push To 0, Compared with less object The grid of , This is overpowering Of , This will lead to network instability and even divergence .
terms of settlement :- Pay more attention to 8 Coordinate prediction of dimension , Give more to these losses loss weight, Write it down as
 stay pascal VOC Take... From training 5.
stay pascal VOC Take... From training 5. - For no object Of box Of confidence loss, Give small loss weight, Write it down as
 stay pascal VOC Take... From training 0.5.
stay pascal VOC Take... From training 0.5. - Yes object Of box Of confidence loss And categories loss Of loss weight Take... Normally 1.
- Pay more attention to 8 Coordinate prediction of dimension , Give more to these losses loss weight, Write it down as
For different sizes box Forecasting , Compared with big box The prediction is a little bit biased , Small box It must be more intolerable to deviate a little . and sum-square error loss To the same offset loss It's the same .
In order to ease the problem , The author used a more ingenious way , Will be box Of width and height Take the square root instead of the original height and width. This is easy to understand with reference to the figure below , Small box The value of the horizontal axis is smaller , When there is an offset , React to y The shaft is bigger box Be big .One grid predicts multiple box, The hope is that each box predictor To predict a particular object. The specific way is to look at the current forecast box And ground truth box Which one of them IoU Big , Which one is responsible for . This practice is called box predictor Of specialization.
Finally, the whole loss function is as follows :


In this loss function :
- Only if there is... In a grid object It's only when classification error To punish .
- Only when someone box predictor To someone ground truth box When in charge , That's right box Of coordinate error To punish , And to which ground truth box It depends on the predicted value and ground truth box Of IoU Is it there cell All of the box The largest of .
- Other details , For example, use the activation function to use leak RELU, For model ImageNet Pre training and so on

The design goal of the loss function is to let the coordinates (x,y,w,h),confidence,classification These three aspects are well balanced . Simply all use sum-squared error loss To do this will have the following shortcomings : a) 8 Dimensional localization error and 20 Dimensional classification error It's obviously unreasonable to be equally important ; b) If there is no object( There are many grids in a picture ), So I'm going to put box Of confidence push To 0, Compared with less object The grid of , This is overpowering Of , This will lead to network instability and even divergence . The solution is as follows :
- Pay more attention to 8 Coordinate prediction of dimension , Give more to these losses loss weight, Write it down as
 rcoobj stay pascal VOC Take... From training 5.( The blue box above )
rcoobj stay pascal VOC Take... From training 5.( The blue box above ) - For no object Of bbox Of confidence loss, Give small loss weight, Write it down as rnoobj stay pascal VOC Take... From training 0.5.( The orange box above )
- Yes object Of bbox Of confidence loss ( The red box in the figure above ) And categories loss ( The purple box above ) Of loss weight Take... Normally 1.
For different sizes bbox Forecasting , Compared with big bbox The prediction is a little bit biased , Small box The prediction is a little biased, and it's even more unbearable . and sum-square error loss To the same offset loss It's the same . In order to ease the problem , The author used a more ingenious way , Will be box Of width and height Take the square root instead of the original height and width. Here's the picture :small bbox The value of the horizontal axis is smaller , When there is an offset , React to y On axis loss( The figure below is green ) Than big box( The picture below is red ) Be big .

One grid predicts multiple bounding box, In training, we want everyone to object(ground true box) only one bounding box Responsible for ( One object One bbox). The specific approach is to work with ground true box(object) Of IOU maximal bounding box Responsible for the ground true box(object) The forecast . This practice is called bounding box predictor Of specialization( Professionalization ). Each predictor will be specific to (sizes,aspect ratio or classed of object) Of ground true box The prediction is getting better and better .( Personal understanding :IOU The largest offset will be less , Can learn to the right position more quickly )
Approximate process :
- Resize become 448*448, Image segmentation results in 7*7 grid (cell)
- CNN Feature extraction and prediction : Convolution is not angry, responsible for presenting features . The full link section is responsible for predicting :a) 7*7*2=98 individual bounding box(bbox) Coordinates of And whether there are objects confidence . b) 7*7=49 individual cell Belongs to 20 Probability of an object .
- Filter bbox( adopt nms)

Training :
Pre training classification network : stay ImageNet 1000-class competition dataset Pre train a classification network , This network is Figure3 In front of 20 A winder network +average-pooling layer+ fully connected layer ( At this time, the network input is 224*224).
Training detection network : Transform the model to perform the detection task ,《Object detection networks on convolutional feature maps》 It is mentioned that adding convolution and full link layers to the pre training network can improve performance . Add... To their example 4 Convolutions and 2 A full link layer , Random initialization weights . Detection requires fine-grained visual information , So the network input is also 224*224 become 448*448. see Figure3.
- A picture is divided into 7x7 Grid (s) (grid cell), The center of an object falls in this grid, which is responsible for predicting the object .

The output of the last layer is (7*7)*30 Dimensions . Every 1*1*30 The dimension of corresponds to the original drawing 7*7 individual cell One of them ,1*1*30 It contains category prediction and bbox Coordinate prediction . In general, let the grid be responsible for category information ,bounding box Mainly responsible for coordinate information ( Part responsible for category information :confidence It's also category information ). As follows :
- Every grid (1*1*30 The dimension corresponds to... In the original drawing cell) To predict 2 individual bounding box ( Yellow solid wireframe in the figure ) Coordinates of (,w,h) , among : Of the central coordinates Normalized to... Relative to the corresponding grid 0-1 Between ,w,h With images width and height Normalize to 0-1 Between . Every bounding box In addition to going back to where you are , And with a prediction confidence value . This confidence Represents the predicted box contains object And this box How accurate and dual information is predicted :confidence = . If there is ground true box( Manually marked objects ) Fall on one grid cell in , The first one is 1, Otherwise take 0. The second is the prediction bounding box And the actual ground truth box Between IOU value . namely : Every bounding box To predict , common 5 It's worth ,2 individual bounding box common 10 It's worth , Corresponding 1*1*30 The first of the dimensional features 10 individual .
-



- Each grid also predicts category information , There is... In the paper 20 class .7x7 The grid of , Every grid should predict 2 individual bounding box and 20 Category probability , Output is 7x7x(5x2 + 20) . ( General formula : SxS Grid (s) , Every grid should predict B individual bounding box And predict C individual categories, Output is S x S x (5*B+C) One of the tensor. Be careful :class Information is for each grid ,confidence The message is for each bounding box Of )
4.YOLO The shortcomings of
YOLO For objects close to each other , There are also very small groups The detection effect is not good , This is because only two boxes are predicted in a grid , And it belongs to only one category .
Yes test Image , The new and unusual aspect ratios and other cases of the same kind of objects are . The generalization ability is weak .
Because of the loss of function , Positioning error is the main reason that affects the detection effect . Especially in the handling of large and small objects , Need to be strengthened .
https://blog.csdn.net/c20081052/article/details/80236015
边栏推荐
- Sword finger offer II 115. reconstruction sequence
- Classification model - logistic regression, Fisher linear discriminant (SPSS)
- The role of physical layer, link layer, network layer, transport layer and application layer of tcp/ip model of internet protocol stack
- Grey prediction (matlab)
- ES6 other syntax and extended syntax summary
- J9 number theory: how can we overcome the fomo phenomenon in the digital industry?
- ES6 use of arrow function
- Upgrade unity visual studio 2019 to 2022 (throw away pirated red slag)
- Analysis of video capability and future development trend based on NVR Technology
- 【Unity3D日常BUG】Unity3D解决“找不到类型或命名空间名称“XXX”(您是否缺少using指令或程序集引用?)”等问题
猜你喜欢
Mongodb database + graphical tools download, installation and use

Getting started database days3

Tap series article 7 | easy to manage pipeline configuration
![[leetcode ladder] linked list · 203 remove linked list elements](/img/72/d3e46a820796a48b458cd2d0a18f8f.png)
[leetcode ladder] linked list · 203 remove linked list elements
ospf终极实验——学会ospf世纪模板例题

Tap series article 8 | tap Learning Center - learn through hands-on tutorials

Diabetes genetic risk testing challenge advanced

Rails with OSS best practices
![[jailhouse article] a novel software architecture for mixed criticality systems (2020)](/img/ab/b9269acfa5135fdaa3d0d8cc052105.png)
[jailhouse article] a novel software architecture for mixed criticality systems (2020)

Getting started database days2
随机推荐
As a developer, you have to know the three performance testing tools JMeter, API and jmh user guide
Grey prediction (matlab)
D2admin framework is basically used
礪夏行動|源啟數字化:既有模式,還是開源創新?
ospf终极实验——学会ospf世纪模板例题
ES6 use of arrow function
砺夏行动 2022|源启数字化圆桌论坛即将上线
torchvision.datasets.ImageFolder前的数据整理及使用方法
Notes on network segment CIDR
SecureCRT garbled
$, $*, [email protected], $$ Understand the meaning of 0
Tap series article 9 | application development accelerator
ES6箭頭函數的使用
Linked list - 203. remove linked list elements
砺夏行动|源启数字化:既有模式,还是开源创新?
Interface test
TAP 系列文章5 | 云原生构建服务
Getting started database Days1
13. Roman to integer
openEuler 资源利用率提升之道 01:概论