当前位置:网站首页>Elastic searchable snapshot function (frozen Tier 3)
Elastic searchable snapshot function (frozen Tier 3)
2022-06-24 17:02:00 【Three ignition cycles】
@toc
3 month 23 Number ,Elastic The latest 7.12 edition . In this version , The most important update is frozen tier Release . Compared with the previous version of cold tier( About cold tier The details of the , You can check the previous blog posts :Elastic Searchable snapshot A preliminary study of the function of 、Elastic Searchable snapshot A preliminary study of the function of Two (hot phase)), The biggest difference is that we can search the data directly in the object store , That is, we can keep the snapshot data in the object storage all the time Available online , By building a small-scale , A computing cluster with only basic storage , You can view the massive data saved in the snapshot ! Achieve real separation of computing and storage , And greatly reduce the cost of looking up huge historical frozen data and improve the query efficiency .( Refer to the official blog : Search directly with the new frozen layer S3)
High energy picture ahead :
A single node " mount "1PB data , Local disk usage 1.7%, Only a few computing resources and local storage resources can be used to query massive data .
To do that , There are several premises :
- Need to have Elastic Of Enterprise Level subscription
- There are already available object stores for the snapshot repository
Presentation ideas
In Ben Bowen , Let's briefly show you , How to use Searchable snapshot + Frozen Tier To do data search directly in the snapshot , The main point here is —— By building a small-scale , A computing cluster with only basic storage , You can view the massive data saved in the snapshot ! therefore , We need to prepare at least two clusters , A data cluster is used to generate snapshots , We can abstract it into other clusters in our production environment that generate a large number of logs , For those that have turned cold , Even data to be archived , We all put it in snapshot Inside . The other is our goal of keeping archive level data Available online Computing Cluster , adopt mount The way , take snapshot The mount is local , But does not occupy the storage space searchable snapshot index.
- The above
default-deploymentThat's what we mentioned “ Data clustering ” - and
frozen tierThat's what we mentioned “ Computing Cluster ”
In order to use the frozen tier The function of , We need to cluster computing (frozen tier colony ) Make specific configuration —— xpack.searchable.snapshot.shared_cache.size: 8GB:
Be careful , It is already available on this version
autoscalingfunction
Prepare the data
We use esrally As the test data set , The choice is noaa data , contain 33,659,481 A document , The original size is 9.0GB
____ ____
/ __ \____ _/ / /_ __
/ /_/ / __ `/ / / / / /
/ _, _/ /_/ / / / /_/ /
/_/ |_|\__,_/_/_/\__, /
/____/
Available tracks:
Name Description Documents Compressed Size Uncompressed Size Default Challenge All Challenges
------------- --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ----------- ----------------- ------------------- ----------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
noaa Global daily weather measurements from NOAA 33,659,481 949.4 MB 9.0 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,top_metrics,aggs
http_logs HTTP server log data 247,249,096 1.2 GB 31.1 GB append-no-conflicts append-no-conflicts,runtime-fields,append-no-conflicts-index-only,append-sorted-no-conflicts,append-index-only-with-ingest-pipeline,update,append-no-conflicts-index-reindex-only
metricbeat Metricbeat data 1,079,600 87.7 MB 1.2 GB append-no-conflicts append-no-conflicts
so Indexing benchmark using up to questions and answers from StackOverflow 36,062,278 8.9 GB 33.1 GB append-no-conflicts append-no-conflicts
geonames POIs from Geonames 11,396,503 252.9 MB 3.3 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-sorted-no-conflicts,append-fast-with-conflicts
eql EQL benchmarks based on endgame index of SIEM demo cluster 60,782,211 4.5 GB 109.2 GB default default
eventdata This benchmark indexes HTTP access logs generated based sample logs from the elastic.co website using the generator available in https://github.com/elastic/rally-eventdata-track 20,000,000 756.0 MB 15.3 GB append-no-conflicts append-no-conflicts,transform
geoshape Shapes from PlanetOSM 60,523,283 13.4 GB 45.4 GB append-no-conflicts append-no-conflicts
geopointshape Point coordinates from PlanetOSM indexed as geoshapes 60,844,404 470.8 MB 2.6 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-fast-with-conflicts
nyc_taxis Taxi rides in New York in 2015 165,346,692 4.5 GB 74.3 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-sorted-no-conflicts-index-only,update,append-ml,date-histogram
nested StackOverflow Q&A stored as nested docs 11,203,029 663.3 MB 3.4 GB nested-search-challenge nested-search-challenge,index-only
geopoint Point coordinates from PlanetOSM 60,844,404 482.1 MB 2.3 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-fast-with-conflicts
pmc Full text benchmark with academic papers from PMC 574,199 5.5 GB 21.7 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-sorted-no-conflicts,append-fast-with-conflicts
percolator Percolator benchmark based on AOL queries 2,000,000 121.1 kB 104.9 MB append-no-conflicts append-no-conflicts adopt esrally Write to data cluster (default-deployment colony ) in :
esrally race --track=noaa --pipeline=benchmark-only --offline --user-tag="ece:7.12.0" \ --challenge="append-no-conflicts-index-only" \ --target-hosts="https://cb0ac8df156242eeb422394c6b872c00.35.241.87.19.ip.es.io:9243" \ --client-options="use_ssl:true,verify_certs:false,basic_auth_user:'elastic',basic_auth_password:'your-pass-word'"
The default index name is weather-data-2016, The size is 5.7gb:
Create snapshot warehouse and snapshot
We use GCP Upper GCS A repository of snapshots stored as objects .( You can join the previous article Elastic Cloud Enterprise Snapshot management for , Learn how to be in ECE Create and manage snapshot Repositories on )
stay gcs Create a file named shared-repository The snapshot repository of , Notice the base_path, The next computing cluster needs to use the same base_path To read the data snapshot created by the data cluster
PUT /_snapshot/shared-repository
{
"type": "gcs",
"settings": {
"bucket": "lex-demo-bucket",
"client": "my_alternate_client",
"base_path": "searchable_snapshot",
"client_name": "cloud-gcs"
}
} take weather-data-2016 Index write snapshot , here , I named the snapshot searchable_snapshot:
PUT /_snapshot/shared-repository/searchable_snapshot?wait_for_completion=true
{
"indices": "weather-data-2016",
"ignore_unavailable": true,
"include_global_state": false,
"metadata": {
"taken_by": "lex",
"taken_because": "for demo"
}
}Associate snapshot warehouse with snapshot
In the computing cluster (forzen tier colony ) in , In the same base_path Create repository :
PUT /_snapshot/shared-repository
{
"type": "gcs",
"settings": {
"bucket": "lex-demo-bucket",
"client": "my_alternate_client",
"base_path": "searchable_snapshot",
"client_name": "cloud-gcs"
}
}At this time , You can see the snapshot from the data cluster
mount searchable snapshot
Usually , You can ILM Manage searchable snapshots . When searchable snapshot operations arrive cold or frozen When the stage , It will automatically convert a regular index to a searchable snapshot index . But now you can search for snapshots frozen tier The function is still in pre-beta Stage , I haven't done it yet ILM among , therefore , We need to call it manually API The way , Mount .
Mount options
To search for snapshots , You must first mount it locally as an index . Usually ,ILM This operation will be performed automatically , But you can also call Install snapshot API. There are two options for mounting snapshots , Each option has different performance characteristics and local storage space :
full_copy
Load a full copy of the shard of the snapshot index into the node local storage within the cluster . This is the default installation option .ILM stay hot and cold This option is used by default in the phase . This is what we mentioned earlier Cold tier The function of .
Since there is little need to access the snapshot Repository , Therefore, the search performance of a full replica searchable snapshot index is usually comparable to that of a regular index . In the process of recovery , Search performance may be slower than regular indexes , Because the search may require some data that has not been retrieved from the local copy . If this happens ,Elasticsearch Only the data needed to complete the search will be retrieved , Recover in parallel at the same time .
In this case :
POST /_snapshot/shared-repository/searchable_snapshot/_mount?wait_for_completion=true&storage=full_copy
{
"index": "weather-data-2016",
"renamed_index": "weather-data-2016",
"index_settings": {
"index.number_of_replicas": 0
},
"ignored_index_settings": [ "index.refresh_interval" ]
}After loading , Equivalent to the original size , But the default is 0 copy , And it can be recovered automatically
shared_cache
This feature is experimental , It is also the content of this article , However, it may be completely changed or deleted in future versions . Please pay attention to this
Its function is : Use a local cache that contains only the most recently searched portion of the snapshot index data . By default ,ILM stay frozen Use this option in stages and corresponding frozen layers .
If the data needed for the search is not in the cache ,Elasticsearch The missing data will be retrieved from the snapshot repository . Searches that require these extracts are slow , But store the extracted data in the cache , So that similar search services can be provided faster in the future .Elasticsearch Will evict infrequently used data from the cache , To free up space .
Although slower than a full local copy or regular index , But the searchable snapshot index of the shared cache still returns search results quickly , Even for large datasets , Because the data layout in the repository has been optimized for search . Before returning the result , Many searches will need to retrieve only a small portion of the total shard data .
To load a searchable snapshot index using the shared cache mount option , This... Must be configured xpack.searchable.snapshot.shared_cache.size Set to reserve space for the cache on one or more nodes . Use shared_cache The indexes loaded with the mount option are only assigned to the nodes configured with this setting
In this case :
POST /_snapshot/shared-repository/searchable_snapshot/_mount?wait_for_completion=true&storage=shared_cache
{
"index": "weather-data-2016",
"renamed_index": "weather-data-2016",
"index_settings": {
"index.number_of_replicas": 0
},
"ignored_index_settings": [ "index.refresh_interval" ]
}After loading , The local disk takes up space of 0!
Tests can search for snapshots
stay shared_cache Index mounted in mode , Its first visit , There will be a time for data download , But you can see that because only specific data is downloaded ( Here is what is needed for aggregation doc value), therefore ,12 You can complete one in seconds 6gb Aggregation of size indexes
Second execution , Because there is cache , It will be much faster (12048 vs 2002)
But relative to the speed on the original data cluster , There is still a slight gap (2002 vs 1358)
summary
newest release This searchable snapshot of the frozen layer , Let's do the real separation of computing and storage . The freezing layer does not store data locally , Search directly for data stored in the object store , Without having to do it first restore operation . The local cache stores the most recently queried data , In order to get the best performance when searching repeatedly . result , Storage costs have dropped significantly - Up to... In the thermosphere or thermosphere 90%, Up to... In the cold layer 80%. The fully automated lifecycle of data is now complete : From hot to hot to cold to freezing , While ensuring the required access and search performance at the lowest storage cost .
Whether out of observability , Security is also the purpose of enterprise search , Your IT Data can maintain exponential growth . The daily intake and search number of the organization TB Data is very common . These data are not only critical to daily success , It is also very important for historical reference . Review security investigations without restrictions , Drilled for years APM Data for trend identification , Or occasionally find that compliance is the key case needed , It will require your data to be stored and accessed for a long time . And the appearance of frozen layer , It opens the door to all these use cases for you , What are we waiting for? , Try it quickly !
边栏推荐
- Today, Tencent safety and SAIC Group officially announced!
- ## Kubernetes集群中流量暴露的几种方案 Kubernetes集群中流量暴露的几种方案
- Is CICC securities reliable? Is it legal? Is it safe to open a stock account?
- [tke] enable CPU static management strategy
- Daily algorithm & interview questions, 28 days of special training in large factories - the 15th day (string)
- The mystery of redis data migration capacity
- Development of block hash game guessing system (mature code)
- What is a reptile
- A survey of training on graphs: taxonomy, methods, and Applications
- Pagoda activities, team members can enjoy a lightweight server 1 core 2g5m 28 yuan for two years
猜你喜欢

Daily algorithm & interview questions, 28 days of special training in large factories - the 15th day (string)

A survey of training on graphs: taxonomy, methods, and Applications
![[leetcode108] convert an ordered array into a binary search tree (medium order traversal)](/img/e1/0fac59a531040d74fd7531e2840eb5.jpg)
[leetcode108] convert an ordered array into a binary search tree (medium order traversal)
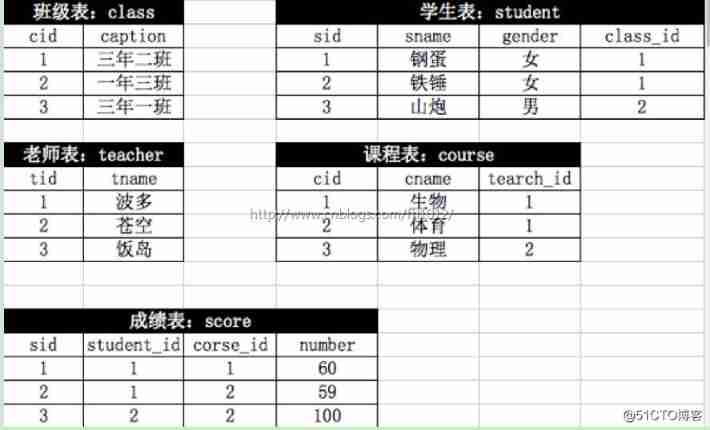
MySQL learning -- table structure of SQL test questions

A survey on model compression for natural language processing (NLP model compression overview)

A survey on dynamic neural networks for natural language processing, University of California
随机推荐
zblog系统实现前台调用当天发布文章数量的教程
National standard gb28181 protocol video platform easygbs alarm reporting function adds video alarm reporting and video recording
What is the difference between a network card and a port
NFT元宇宙源码搭建解析与介绍
How do HPE servers make RAID5 arrays? Teach you step by step today!
Solution to the problem that kibana's map cannot render longitude and latitude coordinate data
How to save data to the greatest extent after deleting LV by misoperation under AIX?
Contributed code to famous projects for the first time, a little nervous
Audio knowledge (I)
[play with Tencent cloud] & lt; trtc-room> Applet component usage
2021 devopsdays Tokyo Station ends perfectly | coding experts are invited to share the latest technical information
网站SEO排名越做越差是什么原因造成的?
What is a reptile
How to access tke cluster API interface with certificate or token
After the collective breakthrough, where is the next step of China's public cloud?
In those years, I insisted on learning the motivation of programming
Is CICC securities reliable? Is it legal? Is it safe to open a stock account?
How to customize the log output format of zap?
Serial of H3CNE experiment column - spanning tree STP configuration experiment
Sigai intelligent container damage identification products are deployed in Rizhao Port and Yingkou Port