当前位置:网站首页>Notes of Teacher Li Hongyi's 2020 in-depth learning series 6
Notes of Teacher Li Hongyi's 2020 in-depth learning series 6
2022-07-24 22:59:00 【ViviranZ】
Look blind .... At least take a note
https://www.bilibili.com/video/BV1UE411G78S?from=search&
Q-learning:
First of all, review critic: Responsible for one actor Scoring , When actor At some point state When ,critic You can calculate the possible expectations in the future . Be careful :critic Give a score and actor(policy\pi) The binding of , The same state Different actor Words critic Will give different reward expect .

Review by the way critic Scoring method :
1.MC Method :
Count every time accumulated reward, Therefore, you must play until the end of the game update network.

2.TD Method :
There is no need to play to the end , As long as it's over s_t Get into s_{t+1} You can update

distinguish between :
because MC Go on until the end of the game , Every step will have variance, Multi step is secondary accumulation , So the variance is very large .
TD Just count back one step ,variance Small ; However, due to the small number of calculation steps, it will cause inaccuracy .

An example :
In the calculation s_a When , If we put sa As a waiting state, stay MC And finally get sb Prove it reward Should be 0; But in TD The method says sb This is just a coincidence , Maybe I met sb obtain 0 the 1/4, And look forward to sb Should be 3/4, That is to say sa Get what you deserve reward.

except MC and TD Other than critic-Q^\pi(s,a), Specifically, it means meeting state s It is time to enforce action a, Throw the rest to agent According to \pi Come and go . Also have discrete But it only applies to a limited number of action.

Give a chestnut. :

As long as there is one Q function And any one of them policy\pi You can always find a better one than \pi better policy \pi', Ask again Q, Update again \pi', It always gets better .
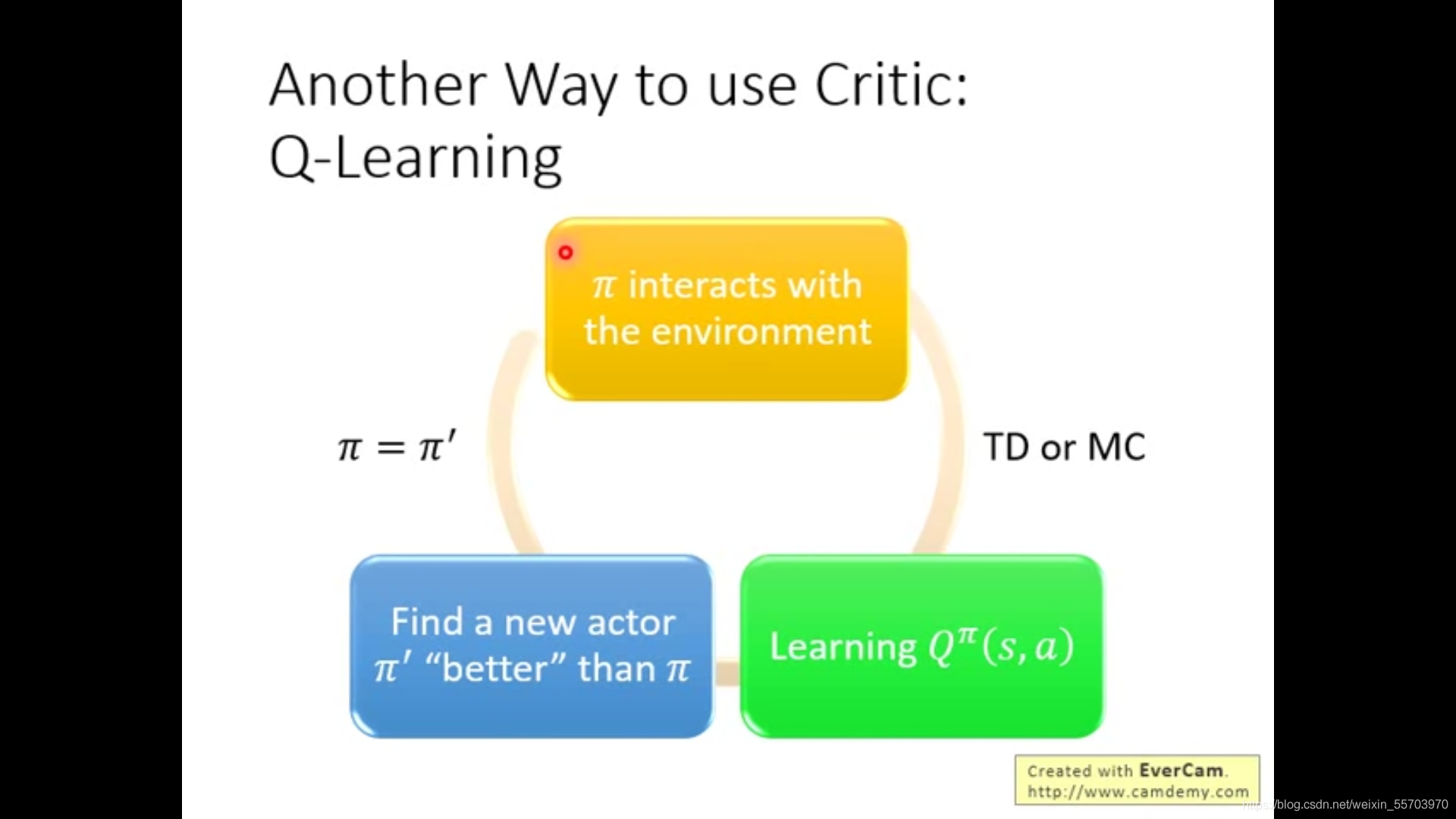
What is called “ good ”?
Is in state s Consider all possible action a, Find the largest one defined as \pi' Corresponding action a.

Next, prove a prop: As long as there is one state take \pi'(s) A given action, No matter which route is adopted policy\pi, Will make the last Q Value increases —— Better !

Here are a few tips:
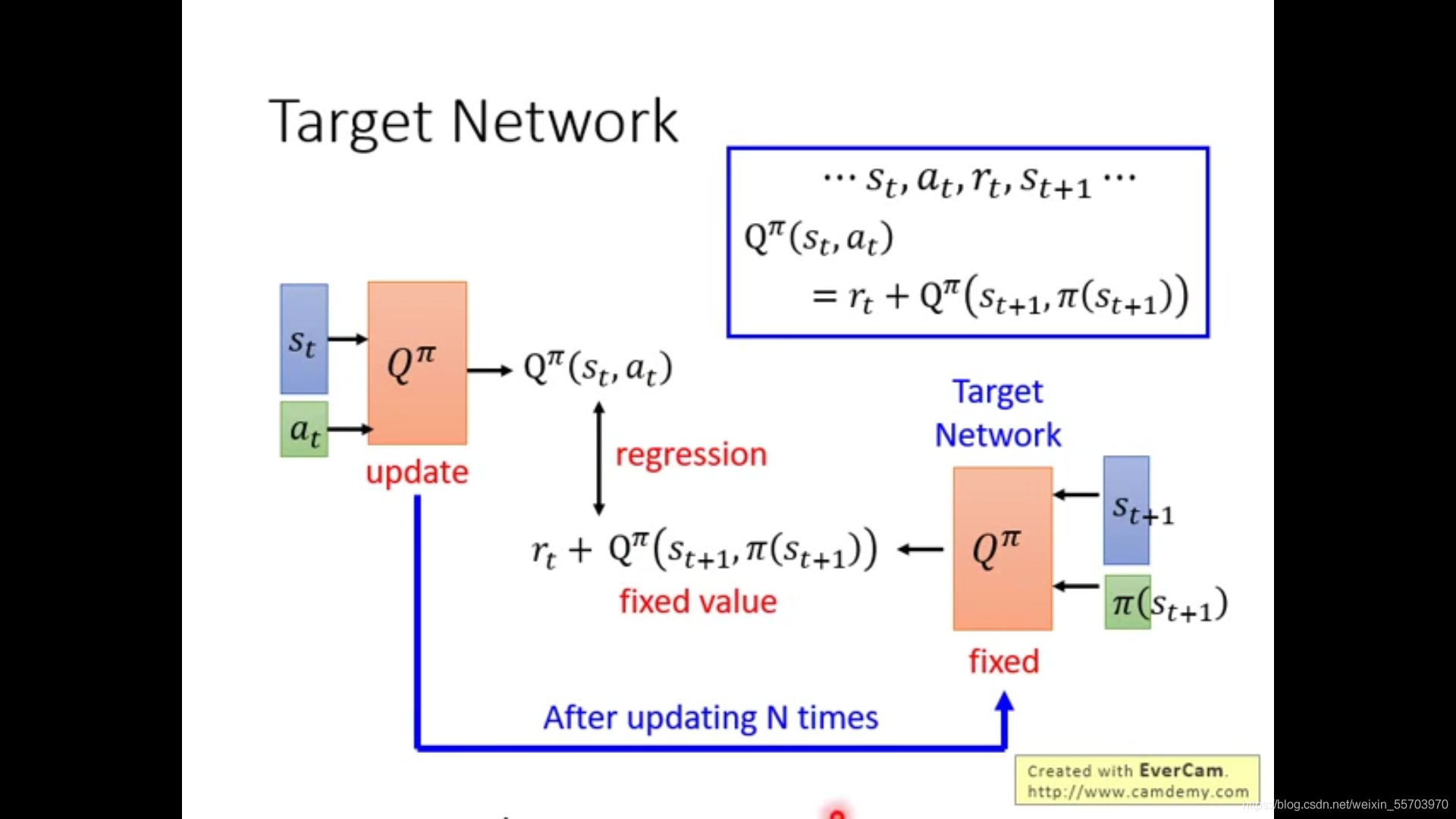
actor-critic Two networks in the network . One is only responsible for walking and usually doesn't move (target network); Another crazy move (……) Be responsible for producing as good as possible action, Crazy exploration to find the best next step back to target,target Walk to the next state Explore crazily again ....( It's bad luck )
The second is if agent Not in the state s done action a, It may not be possible to calculate Q value , Can only estimate . If Q It's a network It's good to say (Q How is network? Don't understand, ), however generally That's a problem .agent It is possible to do a good job and keep doing it , But maybe something else is better ... So we give \epsilon-greedy Algorithm and the second ~

Third : About storage .
We hope Buffer Try to store data in diversed.Buffer Many of the storage in the are used before \pi' The data of - Increase diversity . It is worth noting that , use \pi' Data to calculate \pi Will it cause problems ? The answer is no ( The reason is left for thinking ?)

The overall summary Q-learning The algorithm of :
Be careful :
1.store if buffer Throw one out when it's full .
2.sample It's a group (batch) It's not a piece of (notation It may not be clear )

!! The key is to think clearly ,Q-learning、RL Our goal is to find the best Q!!!!
How to explore another network if it is a continuous action space ( Explore exploration)????
Q-learning There are some problems with the method , So there is Double DQN……( To be continued )

边栏推荐
- Li Kou 1184. Distance between bus stops
- Read and understand the advantages of the LAAS scheme of elephant swap
- How about Minsheng futures? Is it safe?
- Upgrade the jdbc driver to version 8.0.28 and connect to the pit record of MySQL
- "Fundamentals of program design" Chapter 10 function and program structure 7-3 recursive realization of reverse order output integer (15 points)
- Zheng Huijuan: Research on application scenarios and evaluation methods of data assets based on the unified market
- Can the income of CICC securities' new customer financial products reach 6%? How to open an account?
- The idea of Google's "Ai awareness" event this month
- WPF uses pathgeometry to draw the hour hand and minute hand
- How to create and manage customized configuration information
猜你喜欢

Piziheng embedded: the method of making source code into lib Library under MCU Xpress IDE and its difference with IAR and MDK
WPF uses pathgeometry to draw the hour hand and minute hand

IP first experiment hdcl encapsulates PPP, chap, mGRE

JDBC 驱动升级到 Version 8.0.28 连接 MySQL 的踩坑记录

Convert a string to an integer and don't double it

HLS编程入门

ShardingSphere-数据库分库分表简介

Implementation of cat and dog data set classification experiment based on tensorflow and keras convolutional neural network

Effect evaluation of generative countermeasure network

Morris traversal
随机推荐
把字符串转换成整数与不要二
买收益百分之6的理财产品,需要开户吗?
Effect evaluation of generative countermeasure network
[cloud native kubernetes] kubernetes cluster advanced resource object staterulesets
MySQL查询慢的一些分析
基于Verilog HDL的数字秒表
背景图和二维码合成
Monotonic stack structure exercise -- cumulative sum of minimum values of subarrays
中金证券新客理财产品收益可以达到百分之六?开户怎么开?
代码覆盖率
这个月 google的“AI具备意识”的事件的想法
EL & JSTL: JSTL summary
Cross entropy loss
Use kettle to read the data in Excel file and store it in MySQL
高阶产品如何提出有效解决方案?(1方法论+2案例+1清单)
Things to study
Shell调试Debug的三种方式
Is it safe for Guosen Securities to open a mobile account
Luogu p2024 [noi2001] food chain
Okaleido tiger NFT即将登录Binance NFT平台,后市持续看好