当前位置:网站首页>Redis缓存
Redis缓存
2022-06-22 21:12:00 【旧时言】
1.为什么要用缓存?
生活事例
小明是一家饭店的厨师,在饭店发展的初期,因为顾客不多因此小明生活得很悠闲,上班打卡玩手机,下班打卡逛夜店,生活过得十分惬意,但随着饭店的日益发展,顾客也越来越多了,因此出现了高峰期顾客长时间等待的情况,满意度也大幅下降。
因此老板就找到了小明,询问了相关的情况,小明说在高峰期自己要洗菜、切菜和炒菜,每个人的工作量都很大所以就忙不过了,因此上菜就比较慢了。
于是精明的老板就想到了一个好主意,他让厨师在平常不忙的时候把顾客长点的菜提前做好,然后妥善的保存起来,在高峰期直接拿出来热一下就好了,这样一来,果然工作效率就大大提升了,每到高峰期也能轻松应对了。
缓存定义
缓存是一个高速数据交换的存储器,使用它可以快速的访问和操作数据。
程序中的缓存
对于程序来说,当没有使用缓存时,程序的调用流程是这样的:
但随着业务的发展,公司的框架慢慢变成了多个程序调用一个数据库的情况了:
这样改造之后,所有的程序不会直接调用数据库,而是会先调用缓存,当缓存中有数据时会直接返回,当缓存中没有数据时才去查询数据库,这样就大大的降低了数据库的压力,并加速了程序的响应速度。
缓存优点
相比于数据库而言,缓存的操作性能更高,缓存性能高的主要原因有以下几个:
- 缓存一般都是 key-value查询数据的,因为不像数据库一样还有查询的条件等因素,所以查询的性能一般会比数据库高;
- 缓存的数据是存储在内存中的,而数据库的数据是存储在磁盘中的,因为内存的操作性能远远大于磁盘,因此缓存的查询效率会高很多;
- 缓存更容易做分布式部署(当一台服务器变成多台相连的服务器集群),而数据库一般比较难实现分布式部署,因此缓存的负载和性能更容易平行扩展和增加。
2.缓存分类
缓存大致可以分为两大类:
- 本地缓存
- 分布式缓存
本地缓存
本地缓存也叫单机缓存,也就是说可以应用在单机环境下的缓存。所谓的单机环境是指,将服务部署到一台服务器上,如下图所示:

举个例子
本地缓存相当于每家企业的公司规定一样,不同的公司规定也是不同的,比如上班时间,不同的公司上班时间规定也是不同的,对于企事业单位来说一般要求9:00-17:00上班,而对于酒吧来说,这个时间就完全不适合了。
所以,本地缓存的特征是只适用于当前系统。
分布式缓存
分布式缓存是指可以应用在分布式系统中的缓存。所谓的分布式系统是指将一套服务器部署到多台服务器,并且通过负载分发将用户的请求按照一定的规则分发到不同服务器,如下图所示: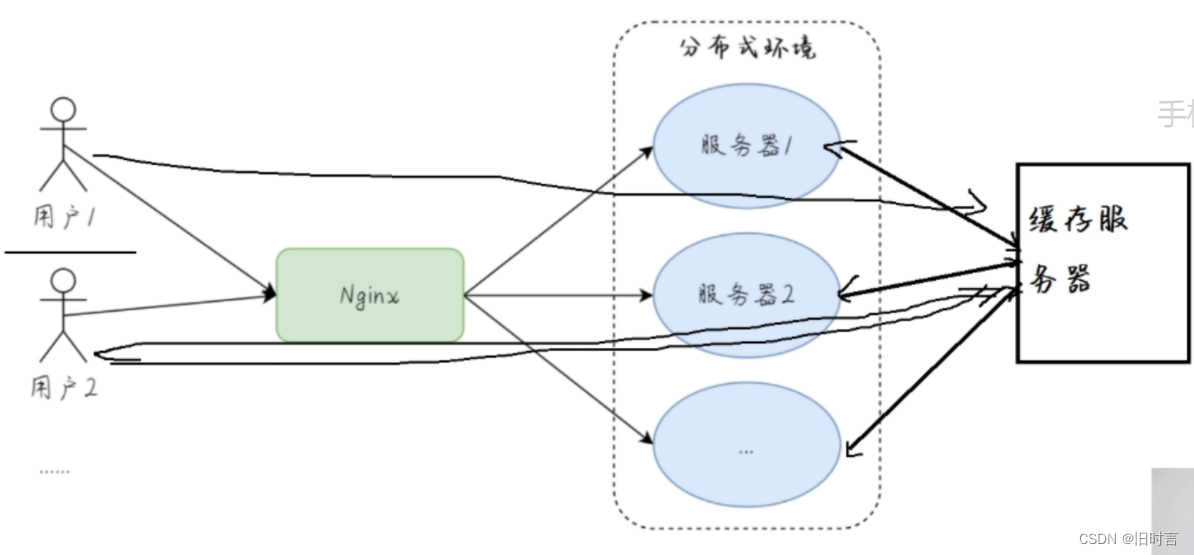
举个例子
分布式缓存相当于适用于所有公司的规定,比如无论是任何公司都不能偷税漏税,不能做违反法律的事情,这种情况就和分布式缓存很像,适用于所有的系统。
比如我们在分布式系统中的服务器A中存储了一个缓存key=laowang,那么在服务器B中也可以读取到 key=laowang 的数据,这样情况就是分布式缓存的作用。
3.常见缓存使用
本地缓存的常见使用: Spring Cache、MyBatis的缓存等。
分布式缓存的常见使用: Redis 和 Memcached。
本地缓存: Spring Cache
在Spring Boot项目,可以直接使用Spring 的内置Cache(本地缓存),只需要完成以下三个步骤就可以正常使用了:
- 开启缓存
- 操作缓存
- 调用缓存
开启缓存
在Spring Boot的启动类上添加如下代码,开启缓存:
@SpringBootApplication
@Enablecaching #开启缓存功能
public class BiteApplication {
public static void main(String[] args) {
SpringApplication.run(BiteApplication.class,args );
}
}
操作缓存
@service
public class UserService {
@Cacheable(cacheNames = "user" ,key = "#id" )
public string getUser(int id){
//伪代码
System.out.println("我进入了getUser方法");
return "ID: "+id;
}
}
使用缓存
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
Userservice userService;
@RequestMapping("/get")
public string getUser(int id) {
return userService.getUser(id);
}
}
使用Postman进行测试

结果分析:第一次调用的时候,调用伪代码进入Dao层,控制台会打印“我进入了getUser方法”。第二次、第三次往后再调用的时候就不会进入Dao层,而是进入缓存中读取数据,也就不会打印“我进入了getUser方法”。
分布式缓存: Redis
在Spring框架中我们也可以直接操作Redis 缓存,它的操作流程如下图所示:
Redis和Memcached有什么区别?
- 存储方式不同: memcache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小; Redis有部份存在硬盘上,这样能保证数据的持久性;
- 数据支持类型:memcache对数据类型支持相对简单;Redis有复杂的数据类型;
- 存储值大小不同: Redis最大可以达到512mb,memcache 只有1mb。
总结:通常情况下,如果是单机Spring项目,会直接使用Spring Cache作为本地缓存,如果是分布式环境一般会使用Redis。
4. Redis数据类型和使用
Redis有5大基础数据类型:
- String——字符串类型
- Hash——字典类型
- List——列表类型
- Set——集合类型
- zSet——有序集合类型
其中最常用的是字符串和字典类型。
字符串类型
字符串类型(Simple Dynamic Strings简称SDS),译为:简单动态字符串,它是以键值对 key-value的形式进行存储的,根据key 来存储和获取 value值,它的使用相对来说比较简单,但在实际项目中应用非常广泛。
字符串的使用如下:
1 127.e.0.1:6379> set k1 v1#添加数据
2 OK
3 127.0.0.1:6379>get k1 #查询数据
4 "v1"
5 127.8.8.1:6379> strlen k1 #查询字符串的长度
6 (Integer) 5
我们也可以使用ex (expires)参数来设置字符串的过期时间,如下代码所示:
1 127.0.0.1:6379> set k1 v1 ex 1000 #设置 k1 1000s后过期(删除)
2 OK
字符串的常见使用场景:
- 存放用户(登录)信息;
- 存放文章详情和列表信息;
- 存放和累计网页的统计信息。
…
字典类型
字典类型(Hash)又被成为散列类型或者是哈希表类型,它是将一个键值(key)和一个特殊的“哈希表”关联起来,这个“哈希表”表包含两列数据:字段和值,它就相当于Java中的Map<String,Map<String,String>>结构。
假如我们使用字典类型来存储一篇文章的详情信息,存储结构如下图所示:
同理我们也可以使用字典类型来存储用户信息,并且使用字典类型来存储此类信息就无需手动序列化和反序列化数据了,所以使用起来更加的方便和高效。
字典类型的使用如下:
1 127.0.0.1:6379> hset myhash key1 value1 #添加数据
2 (integer) 1
3 127.e.0.1:6379> hget myhash key1 #查询数据
4 "value1"
字典类型的数据结构,如下图所示:
列表类型
列表类型(List)是一个使用链表结构存储的有序结构,它的元素插入会按照先后顺序存储到链表结构中,因此它的元素操作(插入和删除)时间复杂度为O(1),所以相对来说速度还是比较快的,但它的查询时间复杂度为O(n),因此查询可能会比较慢。
列表类型的使用如下:
1 127.e.e.1:6379> lpush list 1 2 3#添加数据
2 (integer) 3
3 127.e.0.1:6379> lpop list #获取并删除列表的第一个元素
4 1
列表的典型使用场景有以下两个:
- 消息队列:列表类型可以使用rpush实现先进先出的功能,同时又可以使用lpop轻松的弹出(查询并删除)第一个元素,所以列表类型可以用来实现消息队列;
- 文章列表:对于博客站点来说,当用户和文章都越来越多时,为了加快程序的响应速度,我们可以把用户自己的文章存入到List中,因为List是有序的结构,所以这样又可以完美的实现分页功能,从而加速了程序的响应速度。
集合类型
集合类型(Set)是一个无序并唯一的键值集合。
集合类型的使用如下:
1 127.0.0.1:6379> sadd myset v1 v2 v3#添加数据
2 (integer) 3
3 127.8.0.1:6379> smembers myset #查询集合中的所有数据
4 1) "v1"
5 2) "v3"
6 3) "v2"
集合类型的经典使用场景如下:
- 微博关注我的人和我关注的人都适合用集合存储,可以保证人员不会重复;
- 中奖人信息也适合用集合类型存储,这样可以保证一个人不会重复中奖。
集合类型(Set)和列表类型(List)的区别如下:
- 列表可以存储重复元素,集合只能存储非重复元素;
- 列表是按照元素的先后顺序存储元素的,而集合则是无序方式存储元素的。
有序集合类型
有序集合类型(Sorted Set)相比于集合类型多了一个排序属性score (分值),对于有序集合ZSet来说,每个存储元素相当于有两个值组成的,一个是有序结合的元素值,一个是排序值。有序集合的存储元素值也是不能重复的,但分值是可以重复的。
当我们把学生的成绩存储在有序集合中时,它的存储结构如下图所示:
有序集合类型的使用如下:
1 127.0.0.1:6379> zadd zset1 3 golang 4 sql 1 redis #添加数据
2 (integer) 3
3 127.0.0.1:6379> zrange zset 0 -1 #查询所有数据
4 1) "redis"
5 2) "mysql"
6 3) "java"
有序集合的经典使用场景如下:
- 学生成绩排名
- 粉丝列表,根据关注的先后时间排序
5. 持久化
所谓的持久化就是将数据从内存保存到磁盘的过程,它的目的就是为了防止数据丢失。因为内存中的数据在服务器重启之后就会丢失,而磁盘的数据则不会,因此为了系统的稳定起见,我们需要将数据进行持久化。同时持久化功能又是Redis和 Memcached最主要的区别之一,因为Redis支持持久化而Memcached 不支持。
Redis持久化的方式有以下3种:
- 快照方式(RDB,Redis DataBase)将某一个时刻的内存数据,以二进制的方式写入磁盘;
- 文件追加方式(AOF,Append Only File),记录所有的操作命令,并以文本的形式追加到文件中;
- 混合持久化方式,Redis 4.0之后新增的方式,混合持久化是结合了RDB和AOF的优点,在写入的时候,先把当前的数据以RDB的形式写入文件的开头,再将后续的操作命令以AOF的格式存入文件,这样既能保证Redis重启时的速度,又能减低数据丢失的风险。
持久化策略设置
可以在redis-cli命令行中执行config set aof-use-rdb-preamble yes来开启混合持久化,当开启混合持久化时Redis 就以混合持久化方式来作为持久化策略;当没有开启混合持久化的情况下,使用config set appendonly yes 来开启AOF持久化的策略,当AOF和混合持久化都没开启的情况下默认会是RDB持久化的方式。
RDB优点
- RDB 的内容为二进制的数据,占用内存更小,更紧凑,更适合做为备份文件;
- RDB对灾难恢复非常有用,它是一个紧凑的文件,可以更快的传输到远程服务器进行Redis服务恢复;
- RDB可以更大程度的提高Redis
的运行速度,因为每次持久化时Redis主进程都会fork()一个子进程,进行数据持久化到磁盘,Redis主进程并不会执行磁盘I/○等操作; - 与AOF格式的文件相比,RDB文件可以更快的重启。
RDB缺点
- 因为RDB只能保存某个时间间隔的数据,如果中途Redis 服务被意外终止了,则会丢失一段时间内的 Redis数据;
- RDB需要经常fork()才能使用子进程将其持久化在磁盘上。如果数据集很大,fork()可能很耗时,并且如果数据集很大且CPU性能不佳,则可能导致Redis停止为客户端服务几毫秒甚至-秒钟。
AOF优点
- AOF持久化保存的数据更加完整,AOF提供了三种保存策略:每次操作保存、每秒钟保存一次、跟随系统的持久化策略保存,其中每秒保存一次,从数据的安全性和性能两方面考虑是一个不错的选择,也是
AOF默认的策略,即使发生了意外情况,最多只会丢失1s钟的数据; - AOF采用的是命令追加的写入方式,所以不会出现文件损坏的问题,即使由于某些意外原因,导致了最后操作的持久化数据写入了一半,也可以通过redis-check-aof工具轻松的修复;
- AOF持久化文件,非常容易理解和解析,它是把所有Redis键值操作命令,以文件的方式存入了磁盘。即使不小心使用
flushall命令删除了所有键值信息,只要使用AOF文件,删除最后的flushall命令,重启Redis 即可恢复之前误删的数据。
AOF缺点
- 对于相同的数据集来说,AOF文件要大于RDB文件;
- 在Redis负载比较高的情况下,RDB比AOF性能更好;
- RDB使用快照的形式来持久化整个Redis,数据,而AOF只是将每次执行的命令追加到AOF文件中,因此从理论上说,RDB比AOF更健壮。
混合持久化优点
- 混合持久化结合了RDB和AOF持久化的优点,开头为RDB的格式,使得Redis可以更快的启动,同时结合AOF的优点,有减低了大量数据丢失的风险。
混合持久化缺点
- AOF文件中添加了RDB格式的内容,使得AOF文件的可读性变得很差;
- 兼容性差,如果开启混合持久化,那么此混合持久化AOF文件,就不能用在Redis 4.0之前版本了。
6. 常见面试题
缓存雪崩
缓存雪崩是指在短时间内,有大量缓存同时过期,导致大量的请求直接查询数据库,从而对数据库造成了巨大的压力,严重情况下可能会导致数据库宕机的情况叫做缓存雪崩。
我们先来看下正常情况下和缓存雪崩时程序的执行流程图,正常情况下系统的执行流程如下图所示:
缓存雪崩的执行流程,如下图所示:

以上对比图可以看出缓存雪崩对系统造成的影响,那如何解决缓存雪崩的问题?缓存雪崩的常用解决方案有以下几个。
加锁排队
加锁排队可以起到缓冲的作用,防止大量的请求同时操作数据库,但它的缺点是增加了系统的响应时间,降低了系统的吞吐量,牺牲了一部分用户体验。
随机化过期时间
为了避免缓存同时过期,可在设置缓存时添加随机时间,这样就可以极大的避免大量的缓存同时失效。
示例代码如下:
1 l/缓存原本的失效时间
2 int exTime = 10 * 60;
3 //随机数生成类
4 Random random = new Random( );
5 /缓存设置
6 jedis.setex(cacheKey,exTime+random.nextInt(1000) , value) ;
设置二级缓存
二级缓存指的是除了Redis 本身的缓存,再设置一层缓存,当Redis 失效之后,先去查询二级缓存。
例如可以设置一个本地缓存,在Redis缓存失效的时候先去查询本地缓存而非查询数据库。加入二级缓存之后程序执行流程,如下图所示:
缓存穿透
缓存穿透是指查询数据库和缓存都无数据,因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。
缓存穿透执行流程如下图所示: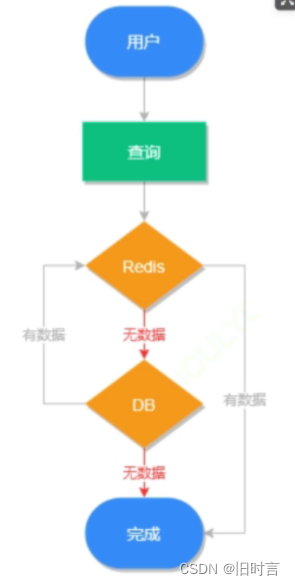
其中红色路径表示缓存穿透的执行路径,可以看出缓存穿透会给数据库造成很大的压力。缓存穿透的解决方案有以下几个。
缓存空结果
另一种方式是我们可以把每次从数据库查询的数据都保存到缓存中,为了提高前台用户的使用体验(解决长时间内查询不到任何信息的情况),我们可以将空结果的缓存时间设置的短一些,例如3-5分钟。
缓存击穿
缓存击穿的执行流程如下图所示:
它的解决方案有以下2个。
加锁排队
此处理方式和缓存雪崩加锁排队的方法类似,都是在查询数据库时加锁排队,缓冲操作请求以此来减少服务器的运行压力。
设置永不过期
对于某些热点缓存,我们可以设置永不过期,这样就能保证缓存的稳定性,但需要注意在数据更改之后,要及时更新此热点缓存,不然就会造成查询结果的误差。
缓存预热
首先来说,缓存预热并不是一个问题,而是使用缓存时的一个优化方案,它可以提高前台用户的使用体验。
缓存预热指的是在系统启动的时候,先把查询结果预存到缓存中,以便用户后面查询时可以直接从缓存中读取,以节约用户的等待时间。
缓存预热的执行流程,如下图所示: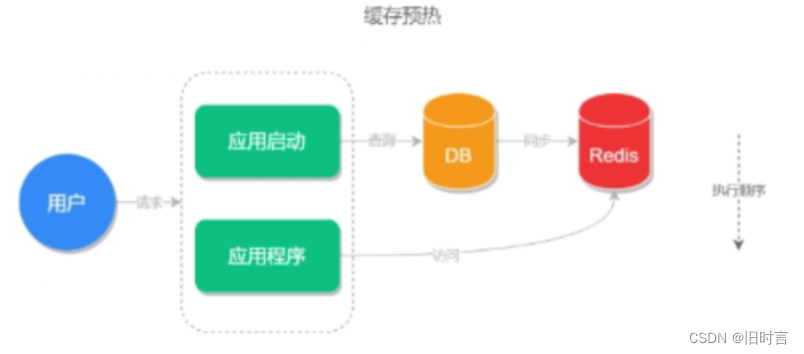
缓存预热的实现思路有以下三种:
- 把需要缓存的方法写在系统初始化的方法中,这样系统在启动的时候就会自动的加载数据并缓存数据;
- 把需要缓存的方法挂载到某个页面或后端接口上,手动触发缓存预热;
- 设置定时任务,定时自动进行缓存预热。
边栏推荐
- web缓存技术
- Reddit's discussion on lamda model: it is not stateless. It adopts a dual process. Compared with the way it edits Wikipedia, it doesn't matter whether it has feelings or not
- Uniapp modifies array properties, and the view is not updated
- 对 cookie 的添加/获取和删除
- js防止PC端复制正确的链接
- three.js模拟驾驶游览艺术展厅---打造超级相机控制器
- C language greedy snake
- js图片分辨率压缩
- flink同步mysql数据到ES
- Mysql database design
猜你喜欢

MySQL master-slave synchronization and its basic process of database and table division

ArcGIS应用(二十)Arcgis 栅格图像符号系统提示“This dataset does not have valid histogram required for classificati…”

2021-04-05

OJ每日一练——过滤多余的空格

保证数据库和缓存的一致性

swagger2 使用方法

c# sqlsugar,hisql,freesql orm框架全方位性能测试对比 sqlserver 性能测试

wallys/WiFi6 MiniPCIe Module 2T2R 2 × 2.4GHz 2x5GHz

tp5.1上传excel文件并读取其内容

企业数字化不是各自发展,而是全面SaaS化推进
随机推荐
Phantomjs utility code snippet (under continuous update...)
flink同步mysql数据到ES
ArcGIS应用(二十)Arcgis 栅格图像符号系统提示“This dataset does not have valid histogram required for classificati…”
同步电路与跨时钟域电路设计2——多bit信号的跨时钟域传输(FIFO)
2021-07-27
异步FIFO
SqlServer 复制表的自增属性
Greedy interval problem (1)
冒泡排序 指针
Relationship between adau1452 development system interface and code data
Array and string offset access syntax with curly braces is no longer support
Unity:利用 射线Ray 检测物体
Ensure database and cache consistency
Autoincrement attribute of sqlserver replication table
tp5.1上传excel文件并读取其内容
js判断浏览器是否打开了控制台
How to continuously improve performance| DX R & D mode
Do domestic mobile phones turn apples? It turned out that it was realized by 100 yuan machine and sharp price reduction
Using the hbuilder x editor to install a solution for terminal window plug-ins that are not responding
js防止PC端复制正确的链接