当前位置:网站首页>Test drive citus 11.0 beta (official blog)
Test drive citus 11.0 beta (official blog)
2022-06-24 19:27:00 【PostgreSQLChina】


Citus 11.0 beta The biggest change of schema and Citus Metadata is now automatically synchronized across the database cluster .
This means that you can always start from Citus Any node in the cluster queries the distributed table !
Use Citus The easiest way is to connect to the coordinator node and use it for schema Change and distributed query , But for very demanding applications , You can now choose to use different connection strings and consider some limitations , In the application ( part ) Load balancing of distributed queries among work nodes .
We are also 11.0 beta Some features have been discarded in the release to speed up our development , I hope most of you will not affect us .
In this article 11.0 beta In a blog post , You will learn :
1、Citus 11.0 beta New automatic metadata synchronization function in
2、 How to configure Citus 11.0 beta colony
3、 How to load balance queries across work nodes
4、 Upgrade to 11.0 beta edition
5、 Improved cluster activity view
6、 Metadata synchronization in transaction block
7、 Abandoning
You can try the new Citus 11.0 beta , See how your application will use it , Or try new features . You can find these packages in our installation instructions .
https://docs.citusdata.com/en/v11.0-beta/installation/multi_node.html
We just launched 11.0 beta New release notes for , If you want to know more about our open source GitHub Repository and review the issues we solved in this release , This should be useful . If you find it useful , Please be there. Slack Tell us on the Internet ! We also plan for the upcoming Citus Release release notes for this type of release . You can Citus Navigation at the top of the website “UPDATES” Link to these release notes .
https://www.citusdata.com/updates/v11-0-beta/
https://slack.citusdata.com/

Citus It could be an extension PostgreSQL The best way to a database . When you publish ,Citus It can span large PostgreSQL Server cluster routing and parallelizing complex queries . In addition to the initial settings , Distribution is transparent to the application : Your application is still connected to a single PostgreSQL node (Citus In terminology “ The coordinator ”), And the coordinator distributes the messages sent by your application in the background Postgres Inquire about .

chart 1:Citus 10.2 Or earlier Citus colony , Where users and items are distributed tables , Their metadata is only on the coordinator .
The single coordinator architecture has many benefits and very good performance , But for some high-performance workloads , The coordinator may become a bottleneck . In practice , Few applications encounter the bottleneck of the coordinator , because Citus The coordinator does relatively little . however , We do find that application developers often want to be ready for the future in terms of scalability , And there are some very demanding enterprise applications .
https://www.citusdata.com/blog/2022/03/12/how-to-benchmark-performance-of-citus-and-postgres-with-hammerdb/
For a long time ,Citus By synchronizing distributed tables schema And metadata , Able to execute distributed queries through work nodes . In the past , We sometimes call this function “MX”. however ,MX Function in use sequence (sequences)、 function (functions)、 Pattern (schemas) And other database objects —— This means that not all tables support metadata synchronization .
Citus 11.0 beta Change to the new operating mode : Now all Citus Database clusters always use metadata synchronization . That means using Citus 11.0 beta And all future versions , You can always run distributed from any node Postgres Inquire about .
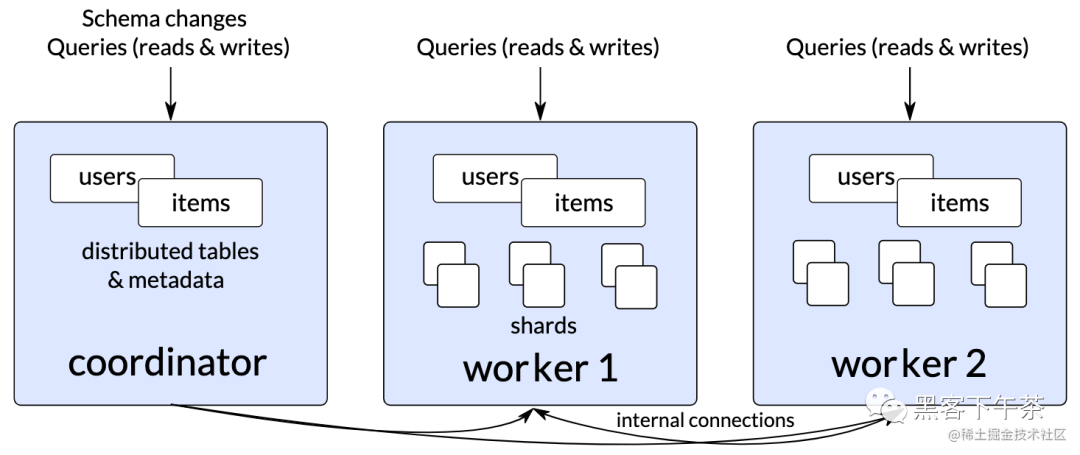
chart 2:Citus 11.0 beta colony , among users and items It's a distributed table , And use the new automatic metadata synchronization function , Their metadata will be synchronized to all nodes .
When you start using Citus 11.0 beta when , You don't need to do anything to enable the new metadata synchronization feature . Each distributed table 、 Database objects and schema Changes are automatically propagated to all Citus worker node .Schema Changes and node management still need to be sent to Citus The coordinator , You can choose to distribute the data by changing the connection string in your application Postgres The query is sent to the coordinator or any other node .
If you need to be in PostgreSQL Many queries are executed on the database every second , You may need to use a relatively large number of connections . Final , Your total throughput is [ The number of connections ]/[ Mean response time ], Because you can only query each connection once at a time .
When your application opens with one of them Citus When connecting nodes , This connection will produce a Postgres process . This Postgres The process needs to establish an internal connection with other nodes to query the fragments of the distributed table . These internal connections are cached to minimize response time . This does mean that every connection from the client will eventually result in additional internal connections to other nodes , Therefore, each node will eventually get the number of connections with the client to the whole database cluster . Fortunately, , We are PostgreSQL 14 There are significant improvements to connectivity scalability in , allow Postgres( and Citus) Maintain good performance under high connection numbers .
https://www.citusdata.com/blog/2020/10/25/improving-postgres-connection-scalability-snapshots/
If you decide to connect from the application to worker Node to run distributed queries , So your client connection is technically competing with the internal connection . To ensure that each of the client connections is handled Postgres Processes can also establish internal connections with all other nodes , We added citus.max_client_connections Set up . This setting limits the number of external client connections , At the same time, continue to allow Citus Internal connections between nodes . In addition to the usual installation instructions , We suggest that in every Citus node ( Coordinator and all workers ) Upper postgresql.conf Add the following settings to , To accommodate a large number of client connections :
https://docs.citusdata.com/en/v11.0-beta/installation/multi_node.html
# The maximum number of client + internal connections a node can handle
# The total number of client connections across all nodes should never exceed this number
max_connections = 6000
# The number of client connections an individual node can handle
# Should be no greater than: max_connections / node count including the coordinator
citus.max_client_connections = 500
Use these settings , Each node will receive up to... From your application 500 A connection , So if you have 10 Work nodes and 1 A coordinator , Then your application can build a total of 5500 A connection . You can do this by using on each node something like pgbouncer Such a connection pool can further increase this number .
https://www.pgbouncer.org/
We also strongly recommend that Citus Add coordinator to metadata , So that the work node can also connect to the coordinator . Only if the coordinator is in metadata , some Citus Function is available . We may add the required coordinators in the future .
-- on all nodes:
CREATE EXTENSION citus;
-- only on coordinator: add coordinator to metadata
SELECT citus_set_coordinator_host('<coordinator’s own hostname>', 5432);
-- only on coordinator: add worker nodes to metadata
SELECT citus_add_node('<worker 1 hostname>', 5432);
SELECT citus_add_node('<worker 2 hostname>', 5432);
-- only on coordinator:
CREATE TABLE items (key text, value text);
SELECT create_distributed_table('items', 'key');
-- from any node:
INSERT INTO items VALUES ('hello', 'world');
Citus 11.0 beta After the cluster is up and running , You have 2 A choice :
You can connect your application to the coordinator as usual , Or by using load balancing enabled clients and custom connection strings ( Such as JDBC or Npgsql), Between work nodes Postgres Query for load balancing . You should also be able to load balance existing applications that already use one of these clients .
https://jdbc.postgresql.org/
https://www.npgsql.org/
stay 2 individual worker An example of load balancing between JDBC Connection string :
https://jdbc.postgresql.org/documentation/head/connect.html
jdbc:postgresql://[email protected]:5432,worker2.host:5432/postgres?loadBalanceHosts=true
stay 2 individual worker An example of load balancing between Npgsql Connection string :
https://www.npgsql.org/doc/connection-string-parameters.html
jdbc:postgresql://[email protected]:5432,worker2.host:5432/postgres?loadBalanceHosts=trueHost=worker1.host,worker2.host;Database=postgres;Username=user;Load Balance Hosts=true
Another method is to set up a node that contains all work nodes IP Of DNS Record . Use DNS One of the disadvantages of , Because of the local DNS cache , Simultaneous open connections from the same machine usually use the same IP. Another option is to set up a dedicated load balancer , Such as HAProxy.
https://severalnines.com/resources/database-management-tutorials/postgresql-load-balancing-haproxy
stay 11.0 beta adopt Citus Work node running Postgres When inquiring , Some limitations need to be noted :
1、 You need to configure your application to pass Citus The coordinator executes schema change , The query can be carried out through any node .
2、 If you create a table on a work node , If you then connect to different work nodes , It will not show .
3、 If you enable citus.use_citus_managed_tables Set or create foreign keys that reference tables , Then the local table on the coordinator only appears in worker Node .
https://www.citusdata.com/blog/2021/06/18/foreign-keys-between-local-ref-tables/
4、 Generate bigint The sequence of will be before the serial number 16 Bit contains the of the connected node ID, This means that the serial number is still unique , But not monotonous .
When trying to insert from a work node , Generate int/smallint The sequence will throw an error
We hope that in the future Citus The above limitations are addressed in version .
If you want to add an existing ( nonproductive ) Cluster upgrade to Citus 11.0 beta, So after installing the new package , You need to call a function to complete the upgrade :
-- on all nodes
ALTER EXTENSION citus UPDATE;
-- only on the coordinator
select citus_finalize_upgrade_to_citus11();
The upgrade function will ensure that all work nodes have the correct schema and metadata. It also solves several naming problems that affect partition table fragmentation .
If there is any situation that prevents metadata synchronization ( for example , Missing permissions or conflicting objects on the work node ), The upgrade function will throw an error . Before fixing the problem and completing the upgrade , You can still go through coordinator Use the existing Citus Database cluster , But some new 11.0 beta Features will not be available .
Citus One feature that is often required is a better understanding of what is happening in the database cluster . When some queries pass worker When the node enters , It becomes more important .
We improved citus_dist_stat_activity View to display data from all client sessions on all nodes pg_stat_activity Information about , And one. global_pid( or gpid), It uniquely identifies a client session and all internal connections associated with that session .gpid The node of the node that initiated the query ID start , That is, the node to which the client is connected .
SELECT nodeid, global_pid, query FROM citus_dist_stat_activity where application_name = 'psql';
┌────────┬─────────────┬────────┬────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ nodeid │ global_pid │ state │ query │
├────────┼─────────────┼────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1 │ 10000001303 │ active │ SELECT nodeid, global_pid, state, query FROM citus_dist_stat_activity where application_name = 'psql'; │
│ 2 │ 20000001346 │ active │ select count(*), pg_sleep(300) from test; │
└────────┴─────────────┴────────┴────────────────────────────────────────────────────────────────────────────────────────────────────────┘
If you want to cancel a specific query , Just put the global_pid Pass to pg_cancel_backend. This applies to any node .
SELECT pg_cancel_backend(20000001346);
You can also use the new citus_stat_activity View to see everything happening in the cluster ( Distributed query and internal query ):
SELECT nodeid, global_pid, state, query, is_worker_query FROM citus_stat_activity WHERE global_pid = 20000001500;
┌────────┬─────────────┬────────┬──────────────────────────────────────────────────────────────────────────────────────────────────┬─────────────────┐
│ nodeid │ global_pid │ state │ query │ is_worker_query │
├────────┼─────────────┼────────┼──────────────────────────────────────────────────────────────────────────────────────────────────┼─────────────────┤
│ 2 │ 20000001500 │ active │ select count(pg_sleep(300)) from test; │ f │
│ 2 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102153 test WHERE true │ t │
│ 2 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102155 test WHERE true │ t │
│ 3 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102156 test WHERE true │ t │
│ 3 │ 20000001500 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102154 test WHERE true │ t │
└────────┴─────────────┴────────┴──────────────────────────────────────────────────────────────────────────────────────────────────┴─────────────────┘
If you are using pg_stat_activity View specific nodes , You can still be in application_name Find worker The query belongs to gpid:
select pid, application_name, state, query from pg_stat_activity where query like '%count%' and application_name <> 'psql';
┌──────┬─────────────────────────────────┬────────┬──────────────────────────────────────────────────────────────────────────────────────────────────┐
│ pid │ application_name │ state │ query │
├──────┼─────────────────────────────────┼────────┼──────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1548 │ citus_internal gpid=10000001547 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102153 test WHERE true │
│ 1550 │ citus_internal gpid=10000001547 │ active │ SELECT count(pg_sleep('300'::double precision)) AS count FROM public.test_102155 test WHERE true │
└──────┴─────────────────────────────────┴────────┴──────────────────────────────────────────────────────────────────────────────────────────────────┘
Because each node needs to be able to connect to Citus Every other node in the cluster , So we also introduced a new health check function , Used to check the connectivity of all possible paths . The result column indicates whether the connection attempt was successful
select * from citus_check_cluster_node_health();
┌───────────────┬───────────────┬─────────────┬─────────────┬────────┐
│ from_nodename │ from_nodeport │ to_nodename │ to_nodeport │ result │
├───────────────┼───────────────┼─────────────┼─────────────┼────────┤
│ localhost │ 1400 │ localhost │ 1400 │ t │
│ localhost │ 1400 │ localhost │ 1401 │ t │
│ localhost │ 1400 │ localhost │ 1402 │ t │
│ localhost │ 1401 │ localhost │ 1400 │ t │
│ localhost │ 1401 │ localhost │ 1401 │ t │
│ localhost │ 1401 │ localhost │ 1402 │ t │
│ localhost │ 1402 │ localhost │ 1400 │ t │
│ localhost │ 1402 │ localhost │ 1401 │ t │
│ localhost │ 1402 │ localhost │ 1402 │ t │
└───────────────┴───────────────┴─────────────┴─────────────┴────────┘
(9 rows)
Use these functions , Even if you execute all queries through the coordinator , You should also have a better understanding of what is happening in the cluster .
In distributed database , We often need consistency 、 Fault tolerance 、 Trade off between parallelism and other distributed systems .Citus Need to support PostgreSQL Interactive multi statement transaction block , This is particularly challenging in distributed environments .
for example ,Citus Expensive operations are often parallelized across Shards — For example, analyze queries and create_distributed_table() At every worker On multiple connections . When creating a database object ,Citus Through each worker A single connection to propagate it to worker node . Combining these two operations in a single multi statement transaction can cause problems , Because parallel connections will not see objects created through a single connection but not yet committed .
Consider a creation type 、 surface 、 Load data and distribute published transaction blocks :
BEGIN;
-- type creation over a single connection:
CREATE TYPE coordinates AS (x int, y int);
CREATE TABLE positions (object_id text primary key, position coordinates);
-- data loading thus goes over a single connection:
SELECT create_distributed_table(‘positions’, ‘object_id’);
\COPY positions FROM ‘positions.csv’
…
stay Citus 11.0 beta Before ,Citus Will be postponed to worker Create type on node , And is executing create_distributed_table Submit separately when . This makes create_distributed_table Data replication in can occur in parallel . However , This also means that the type does not always appear in Citus worker Node — Or if the transaction rolls back , It will only appear in worker Node . We can hide these inconsistencies , But eventually they can cause problems .
stay Citus 11.0 beta in , The default behavior is changed to take precedence between the coordinator and the work node schema Uniformity . This does have one drawback : If object propagation occurs after parallel commands in the same transaction , Then the transaction cannot be completed , As in the following code block ERROR highlight :
BEGIN;
CREATE TABLE items (key text, value text);
-- parallel data loading:
SELECT create_distributed_table(‘items’, ‘key’);
\COPY items FROM ‘items.csv’
CREATE TYPE coordinates AS (x int, y int);
ERROR: cannot run type command because there was a parallel operation on a distributed table in the transaction
If you encounter this problem , Yes 2 A simple solution :
1、 Use set citus.create_object_propagation to deferred; Return the old object propagation behavior , under these circumstances , There may be some inconsistencies between which database objects exist on different nodes .
2、 Use set citus.multi_shard_modify_mode to sequential To disable the parallelism of each node . Data loading in the same transaction may be slower .
As early as 2016 year , We will announce the abandonment of statement based sharding replication to achieve high availability (HA), Support streaming replication instead . When you are in Azure Database for PostgreSQL Enable on Hyperscale (Citus) High availability of , Each node will have a hot standby - This means that all shards on this node are replicated through stream replication . Even if you don't enable high availability , The data will also be copied internally by the managed disk , To prevent any data loss .
https://www.citusdata.com/blog/2016/12/15/citus-replication-model-today-and-tomorrow/
https://docs.microsoft.com/azure/postgresql/hyperscale/concepts-high-availability
Although abandoned , But we never delete statement based replication …… It can still be used to extend reading in specific scenarios , however , Abandoned HA Related logic often leads to problems , And prevent us from implementing metadata synchronization for replicated tables . therefore , As Citus 11.0 Part of the beta , We changed the behavior as follows :
stay Citus 11.0 Before beta , When the write of the copy shard fails at one of the shard positions ,Citus Mark the location as invalid - After that, the fragment must be copied again . This feature never works well , Because sporadic write failures may invalidate the placement and lead to expensive ( Write blocking ) To reproduce .
from Citus 11.0 beta Start , Write to copy shards always use 2PC — This means that they can only succeed if all placements have been started . Besides , The metadata of the replication table is synchronized , So you can query them from any node .
Today, open source users who use statement based fragment replication can upgrade to Citus 11.0 The beta —— however , When the node holding a replica fails , To continue to accept writes to shards , It should be through citus_disable_node Function disables the failed node . After replacing or reactivating the node , Still usable replicate_table_shards Copy the fragment again .
https://docs.citusdata.com/en/stable/develop/api_udf.html#citus-disable-node
https://docs.citusdata.com/en/latest/develop/api_udf.html#replicate-table-shards
If you want to use statement based replication to expand read throughput , You need to :
Before creating a distributed table citus.shard_replication_factor Set to 2, And will citus.task_assignment_policy Set to “round-robin( loop )” To load balance queries between replicas .
The disadvantage of using statement based replication to extend read throughput is that writes have higher response time , And updates and deletions are serialized to keep the copy synchronized .
And PostgreSQL equally ,Citus Maintain long-term backward compatibility . We make every effort to ensure that your application is upgrading Citus Continue working when necessary . however , Sometimes a function no longer meets Citus And hinder the development of . We decided to 11.0 Some... Were removed from the beta Citus function :
Invalid fragment placement : As mentioned in the previous section , When write fails , Tiles are no longer marked as invalid , Because this behavior has some defects and reduces reliability when using statement based replication .
Distributed append table :Citus The initial distribution method in is “append( Additional )” distribution , It is optimized for appending only data .Hash-distributed Tables are easier to use and have more functions , And it can also handle only additional data well through partitioning .Citus 11.0 beta Removed functionality for creating shards and loading new data into additional distributed tables . We are not aware of any additional distributed table users , But just in case : You can still upgrade to 11.0 beta, But these tables will become read-only . We recommend that you use the default hash-distribution New distributed tables for , And use INSERT .. SELECT Command to move data .
https://docs.citusdata.com/en/latest/develop/reference_ddl.html
branch Cloth style cstore_fdw surface ( Should switch to column access mode ): from 10.0 version ,Citus With built-in column storage . stay Citus 10.0 Before , You can use the now discarded cstore_fdw The extension will Citus Use with column storage . however ,cstore_fdw Important tasks such as streaming replication and backup are not supported PostgreSQL function , So in Citus 10 We seldom saw before Citus Customers use columns to store . Many companies now use it successfully Citus Built in column storage to store time series data , So we gave up on creating or using distributed cstore_fdw Table support . If you have distributed cstore_fdw surface , We recommend upgrading to 11.0 beta They were previously converted to column access methods .
https://github.com/citusdata/cstore_fdw
https://www.citusdata.com/blog/2021/10/22/how-to-scale-postgres-for-time-series-data-with-citus/
Citus Is the only one who acts completely as PostgreSQL Extend the implementation of the transaction and analyze the workload of the distributed database , It means Citus Massive support PostgreSQL The power of , And inherited PostgreSQL The stability of 、 performance 、 Versatility 、 Extensibility , And a huge tool ecosystem and Expand .
https://github.com/citusdata/citus
With the help of Citus Open source 11.0 Automatic metadata synchronization function in beta , You can now choose to query your... From any node Citus colony , So as to further improve Citus extensibility .
If you are interested in trying out the new Citus 11.0 beta, You can go to Citus Found in document beta Installation instructions for version . install Citus after , There are a lot of good information about how to get started on the getting started page , Including tutorials and videos . Last , If you want to know more about Citus Information on the internal working principle , Please check our SIGMOD The paper .
https://docs.citusdata.com/en/v11.0-beta/installation/multi_node.html
https://www.citusdata.com/getting-started/
https://dl.acm.org/doi/10.1145/3448016.3457551
Explore Python/Django Support distributed multi tenant database , Such as Postgres+Citus


This article is from WeChat official account. - Open Source Software Alliance PostgreSQL Branch (kaiyuanlianmeng).
If there is any infringement , Please contact the [email protected] Delete .
Participation of this paper “OSC Source creation plan ”, You are welcome to join us , share .
边栏推荐
- subject may not be empty [subject-empty]
- Game between apifox and other interface development tools
- Technology implementation | Apache Doris cold and hot data storage (I)
- flink-sql的kafka的这个设置,group-offsets,如果指定的groupid没有提
- Unity mobile game performance optimization spectrum CPU time-consuming optimization divided by engine modules
- 工作6年,月薪3W,1名PM的奋斗史
- 通过SCCM SQL生成计算机上一次登录用户账户报告
- 请教一个问题。adbhi支持保留一个ID最新100条数据库,类似这样的操作吗
- 全链路业务追踪落地实践方案
- 特尔携手微软发挥边云协同势能,推动AI规模化部署
猜你喜欢

The efficiency of okcc call center data operation

对国产数据库厂商提几个关于SQL引擎的小需求

Camera module and hardware interface of Camera1 camera

Write a positive integer to the node and return a floating-point number multiplied by 0.85 when reading the node

UART communication (STM32F103 library function)

微信小程序轮播图怎么自定义光标位置

华为机器学习服务语音识别功能,让应用绘“声”绘色

SaltStack State状态文件配置实例

Sr-gnn shift robot gnns: overlapping the limitations of localized graph training data

一文理解OpenStack网络
随机推荐
Set up your own website (8)
Freeswitch uses origin to dialplan
使用阿里云RDS for SQL Server性能洞察优化数据库负载-初识性能洞察
IBPS开源表单设计器有什么功能?
企业网络管理员必备的故障处理系统
Understanding openstack network
R语言 4.1.0软件安装包和安装教程
Buddha bless you that there will never be a bug
Download steps of STM32 firmware library
Huawei machine learning service speech recognition function enables applications to paint "sound" and color
敏捷之道 | 敏捷开发真的过时了么?
Steering gear control (stm32f103c8t6)
模块五
一文详解|Go 分布式链路追踪实现原理
LCD12864 (ST7565P) Chinese character display (STM32F103)
Landcover100, planned land cover website
佛祖保佑 永无BUG
AI时代生物隐私如何保护?马德里自治大学最新《生物特征识别中的隐私增强技术》综述,全面详述生物隐私增强技术
[leetcode] rotation series (array, matrix, linked list, function, string)
试驾 Citus 11.0 beta(官方博客)