当前位置:网站首页>无人驾驶: 对多传感器融合的一些思考
无人驾驶: 对多传感器融合的一些思考
2022-06-24 19:49:00 【naca yu】
前言
感谢商汤学术 2022/06/22 带来的基于BEV环视感知直播课程,借助这次机会,总结了我前段时间的工作,主要内容如下:
- FOV和BEV的常用方案,对两种视角在视觉检测技术与原理上进行对比,并总结两者的优缺点;
- 两视角下的融合方案进行了总结:尤其是在当前学术界较为“冷门”的毫米波雷达(Radar) 与“热门”的激光雷达(lidar) 的融合方案进行对比,不同于激光雷达,编者提出了自认为较为合适的针对于Radar融合方案。
编者在本领域的研究不深、对工业界的布局更是了解甚少,仅作为自己学习总结和知识分享,如有不妥和错误,烦请指出,谢谢~
一、FOV视角

FOV作为一种最接近人类的视角,拥有悠久的历史,如今的2D\3D object detection皆从FOV视角做起,感官上来说,FOV视角能够提供丰富的纹理信息、深度信息,同时能够满足常用的目标检测视角需求如口罩检测、人脸识别等任务,另一方面,FOV的数据信息易于收集标注如imagenet、coco等。但是,FOV的信息也有一些缺点:遮挡问题,尺度问题(不同的物体在不同深度下尺度不同)、难以与其他模态融合、融合损失高(Lidar Radar等适合于BEV视角)等。
1.1 常用方案
这里把技术方案分为两个部分,一方面,简要介绍纯视觉检测方法,另一方面,重点讲解FOV视角下的融合技术,分为lidar+camera与radar+camera两类,两类在融合技术方面相似度很高,许多Radar的融合方法都是启发自Lidar融合方法。
1.1.1 FOV纯视觉下的检测方法
这里不过多介绍,主要分为one-stage, two-stage, anchor-based, anchor-free。
除此之外,3D检测领域具有一些代表性的方法:
改进的2D检测方法:FCOS3D

论文作者在FCOS基础上,对Reg分支进行部分修改,使其能够回归centerpoint的同时,加入其他指标:中心偏移、深度、3D bbox大小等,实现了将2D检测器用于3D检测器的跨越。除此之外,包括YOLO3D等工作,将传统的2D detector经过简单修改直接用于3D检测的方法,虽然修改取得了一定成效,但是图像本身缺乏精准的深度信息,加之结构并没有较之前的2D检测加入一定的先验结构,导致效果一般。图像生成伪点云方法:Pseudo-Lidar

由公式可知,深度信息对于我们估算目标的位置非常重要,已知像素坐标和相机内参,我们还需要知道深度才能确定目标的位置,因此深度信息对于3D目标检测来说非常关键。

获取深度信息也成为3D目标检测的关键任务:解决方法主要分为:
一训练专门的backbone编码深度信息但是这种方法并不准确,二将深度信息处理成pseudo-lidar作为点云信息。三是通过BEV方式学习BEV特征到图像的映射,避免直接预测深度信息带来的误差损失。
这里介绍第二种学习方式,一篇论文名为”Pseudo-LiDAR from Visual Depth Estimation“,将立体或双目采集的深度信息或者单目深度估计作为深度信息并处理为伪激光点云,后利用基于点云的检测头进行3D目标检测。
- 传统的2D检测方法:CenterNet

CenterNet是基于锚点的检测方法,这种基于锚点的检测方式,不仅能够回归目标的2D属性,对于depth,orientation等3D属性也能够进行预测,因此这种方法也能够用于人体姿态识别,3D目标检测等。
- 总结
综上,当前基于FOV的检测方法仍然逃不出传统2D检测框架的范式,但是传统框架在3D中我认为有以下问题:1. 预训练模型未能在训练时引入距离信息,导致一些预训练模型直接微调用于深度估计难以得到较大提升。2. 3D目标检测不同于2D检测,不同物体之间存在遮挡,且FOV视角中进行检测存在物体变形的问题。
1.1.2 FOV视角的融合方法
FOV视角的融合方法,主要分为:lidar+camera 与 radar+camera两种。
- FOV:Lidar + Camera
Lidar与Camera的FOV视角融合,有以下几种经典方案:
PointPainting:图像辅助点云检测,并行

作者认为,FOV to BEV方法深度信息不准确会导致融合效果不佳,在FOV检测上纯点云检测的稀疏性导致了点云的误识别问题和分类效果不佳问题,为解决纯激光雷达点云存在的纹理信息缺少等问题,以PointPainting为首的融合方法将图像分割结果融入点云图像,丰富点云语义,提高了检测性能。MV3D:lidar辅助图像,并行
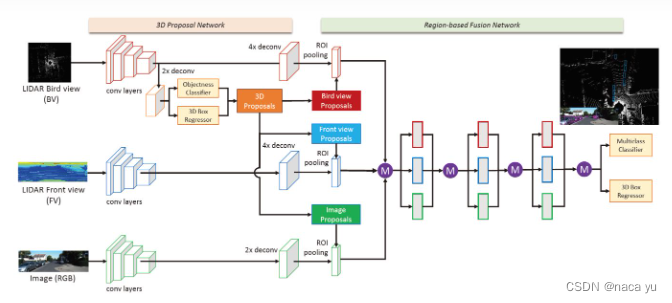
作者认为,雷达点云主要存在以下问题:1)稀疏性(2)无序性(3)冗余性,这里通过在BEV视角中初次进行region proposal后投影到激光雷达FV与图像FV层进行目标的ROI Pooling,再通过deep fusion融合特征,最后进行3D回归和分类。F-PointNet:图像辅助雷达,串行

在 RGB 图像上运行的 2D detector,产生的2D bbox用于界定3D视锥包含前景目标点云。然后基于这些视锥区域中的 3D 点云(centerfusion的灵感来源于此),使用PointNet++ 网络实现 3D实例分割并随后实现3D 边界框估计。
- 总结:
综上,我们列举的基于FOV视角的融合网络,主要分为图像辅助型如pointpainting,proposal-level类型如MV3D,串行图像辅助雷达型如F-PointNet,这三者都是在FOV下,将图像或者雷达数据作为引出或者辅助去帮助另一种模态进行检测,在FOV视角下:一是虽然FOV对于图像模态较为有利,但是以图像模态为主会限制雷达的深度与形状能力,例如将点云投影到图像,对于同深度的目标雷达特征相似度高但是同一物体的不同部分雷达相似度较低,这种情况与相机相反。二是以雷达点云为主会限制图像的丰富纹理,例如pointpainting小物体虽然具有丰富纹理仅少部分对应稀疏的雷达点导致信息缺失。
- FOV: Radar + Camera:之前我写过一篇博客总结,这里不再赘述 - >文章链接
二、BEV视角

BEV特征具有以下优点:1. 能够支持多传感器融合,方便下游多任务共享feature。2. 不同物体在BEV视角下没有变形问题,能够使模型集中于解决分类问题。3. 能够融合多个视角解决遮挡问题和物体重叠问题。但是,BEV特征也有一些问题,例如grid的大小影响检测的细粒度,并且存在大量背景的存储冗余,因为BEV存储了全局的语义信息。
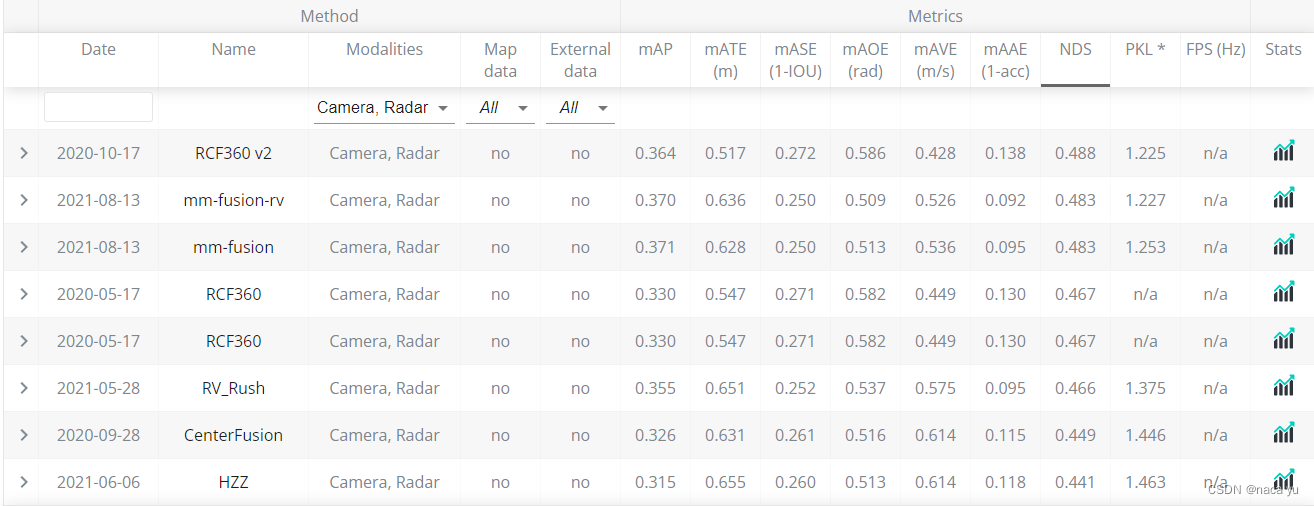
可以看到,下图中BEV检测的方法已经名列前茅,我猜测:一方面是由于BEV特征近期大火,学术界对于BEV的研究导致了最近的模型偏向于BEV,另一方面可能BEV特征更比FOV适合于自动驾驶场景下的3D目标检测。
2.1 常用方案
- Pure Camera
DETR3D:隐含BEV特征

作者仿照DETR的方法,使用900个object queries作为query,途径6个decoder完成注意力建模,在最后通过set-prediction方式预测目标的3D属性,作者的创新点在decoder中的"object queries refinement",也就是将queries用来预测queries对应的3D位置,然后通过相机与点云的转换矩阵转换为2D位置并通过双线性插值提取局部特征add到raw queries中作为下一个decoder block的输入,总结来说就是通过queries隐式融合图像特征,进行一种离散的BEV特征构建并进行预测。
但是这种方法对于大目标检测并不好,其中之一就是只通过F.grid_sample()提取局部的图像信息,缺乏全局的语义信息。BEVFormer:显式BEV特征
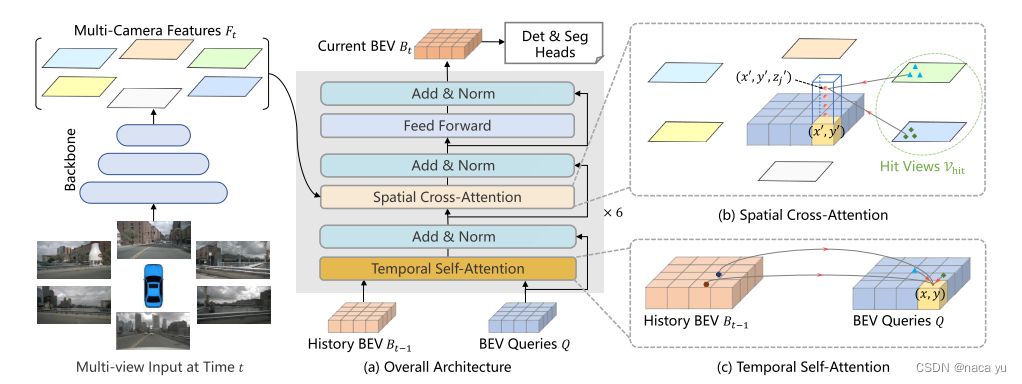
作者通过初始化一个HWC的规则、显式BEV queries作为queries。同时,加入了上一时刻的时序信息,当前时刻的空间信息。两个主要创新点模块伪:TSA和SCA,也就是时间注意力和空间注意力。具体来说,每一个时刻对上一时刻的BEV queries做deformable式的局部注意力,同时每一个grid划分为多个高度,同一方格的多个高度的方格对不同图像做空间局部注意力,最后生成原BEV queries大小的BEV特征作为下一帧的输入,同时作为特征图用于下游任务为地图分割和目标检测。
编者认为,这种BEV feature目前只用于单模态的信息,对于如何融合多种模态,尤其是在引入Radar等稀疏点云时,如何融入到BEV中,第二,如何在检测精度和grid大小之间做衡量也是一个问题,再者,BEV特征的引入限制了最大的检测距离,在高速公路场景,检测远处目标非常重要,如何权衡BEV的大小与检测距离也是一个需要考虑的问题。
- Lidar + camera

Transfusion

作者考虑了如下问题:1. lidar本身特征稀疏尤其是远处的特征稀疏性会导致检测性能下降问题。2. 图像缺乏空间信息,难以直接用于3D检测这种具有空间信息需求的任务。3. 无论是lidar-to-camera导致的空间位置损失问题还是camera-to-lidar导致的语义特征丢失问题,传统的融合方法都难以兼容空间和纹理特征的需求。
基于以上问题,作者提出了Transfusion:首先,两类特诊分别用各自的通用backbone提取特征信息,后LidarBEV通过image guidance使queries带有图像信息,加入一定先验能够更快地使模型收敛,结果更加准确。后将lidar decoder的输出用于lidar-camera decoder部分的queries对图像特征进行融合检测。DeepFusion

这里主要提出:一:inverse aug与learnable align,分别解决数据增强后模态融合的对齐问题以及实现模态之间的自适应对齐,这里融合的方式为将lidar作为主要的数据来源作为queries融合作为kv的图像特征,并将与query对应的图像特征提取后与雷达特征进行concat并融合用于特征检测。BEVFusion

这篇工作务必要看:"Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D"这篇文章,这篇BEVFusion的本质工作就是在LSS的基础上,加速了深度概率分布估计过程,并在基础上引入了雷达BEV特征并做了融合。这篇文章可谓是BEV融合方式的开篇之作,至今仍然占据着榜首,同时这篇文章的另一版本主要介绍的是模型的鲁棒性(对于另一种模态缺失做了消融实验),这一片着重于强调其高效性,如加速了几十倍的深度概率估计过程。
- Radar + Camera:对于BEV视角做融合的方案,目前我还没有看到今年的融合方案采用,但是前几年有一篇论文直接将图像像素投影到BEV并结合Radar特征用于检测。
2.2 总结
2.2.1 融合的视角问题

2.2.2 融合方式的对比
上述BEV融合的方式中,一种是以一种模态作为另一种模态的q去与另一种模态(作为k、v)做注意力并提取相应的特征用于融合,一种是将两种模态单独处理,转移到BEV视角中进行融合:
- 第一种方式的关键在于两种模态的对齐,lidar常作为Q融合图像特征,这种不仅会存在由于lidar特征稀疏导致的查询遗漏问题,还有由于lidar密集致使多个q映射到同一目标的问题。
- 第二种方式的关键在于图像从FOV视角转化到BEV视角的对准率问题,结果也取决于能否找到一种较好的方式将FOV特征投影到BEV中,这种投影方式包括LSS提到的深度概率划分等多种方式,可参考链接,但是这种方式在深度上具有较强的离散性,对于深度的准确估计仍然存在许多问题:例如物体边界模糊,与真实场景差别大等。
三、Lidar目标检测
基于Lidar的检测不做过多介绍,可参考链接。
3.1 PointNet

3.2 PointPillars

3.3 VoxelNet

3.4 Pseudo-lidar
上面已经介绍
四、Radar与Camera融合的未来
4.1 Radar在NuScenes各项任务刷榜现状

雷达检测性能较差,而且工业界多个公司除去了Radar的部署,我认为无非有以下几个原因:
- 雷达点存在噪点问题,传统的卷积学习方式相比传统的Pooling池化方式虽然能够使模型提高在前景物体的置信值,但是仍然不能有效滤除背景噪声,背景噪声指周围的背景物体反射点云,在多数场景下,点云大部分为背景噪声,这种原因是雷达信号本身缺乏图像信息且具备的稀疏性导致,仅通过雷达本身的深度、位置、反射强度等信息无法判断点云语义的关系
- 雷达点存在闪点问题,由于一些Ghost point(灰尘中的金属等)会导致闪点问题而引起的急刹故障,此类问题在单帧下无法避免,通常的解决方法是将此前多帧图像投影到当前帧,但是这会由于目标物体运动而导致雷达点偏移误差,究其原因,是缺少时序信息滤除
- 雷达和相机数据的融合方式:此前的工作都是基于CNN,其对于数据具有平移不变性和局部相关性假设,而且对于纹理信息有着先天的优越性,但是对于雷达这种模态,我们通过可视化特征图,发现融合后雷达特征图仅是起到了对前景物体的增强辅助效果,对两者的融合具有对图像模态的偏重,并不能有效利用雷达模态本身优势
- 雷达的稀疏性

4.2 业界融合方案现状
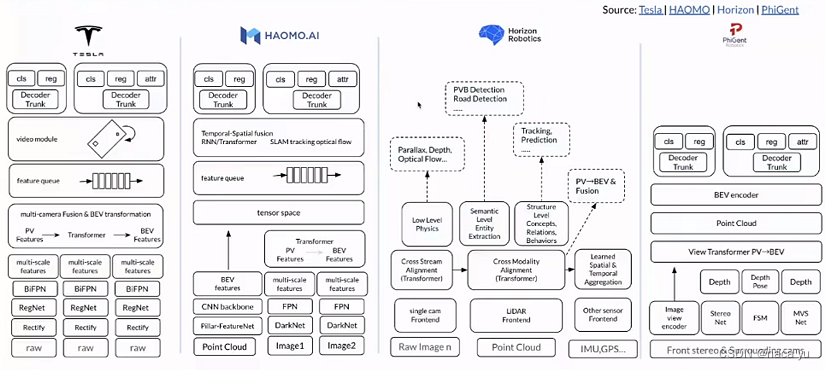
如上图,业界采用的融合方式已经趋于统一的BEV范式,下游从特征提取,特征转化,到上游的时序信息引入都具有较高相似度,且都共享统一的场景特征,并利用多个head分别执行不同的下游任务,地平线将下游任务划分为low,semantic等不同层级的任务,这一点略微不同。
5.3 Radar & lidar与相机的融合趋势
BEV特征目前在学术界和工业界趋于认同,主要是由于其在融合、感知鲁棒性、多下游任务的适应性等特点,尤其是在最近的各类榜单中BEV模型的卓越表现,BEV虽然感觉上更加接近真理,但是要承认,如今的BEV特征仍然不能够媲美多模态的BEV特征,同时多模态的BEV特征也仍有亟待解决的许多问题。
对于Radar的融合问题,不能直接将lidar的方案用于Radar,有以下几个原因:第一,毫米波雷达噪声等占比高,难以学习;第二,毫米波雷达特征稀疏,难以用为q对图像特征索引;第三,毫米波雷达穿透性强对金属反射强,这些特征利用能够有效提高对于恶劣天气的检测性能;
对于如何在BEV视角下融合Radar和Camera呢?有挑战性的几点:1. 如何将稀疏的毫米波雷达引入BEV视角?2. 如何减小毫米波雷达的噪声带来的问题?3. 如何将毫米波雷达充分利用,使其能够在其他模态不稳定时提高一定的鲁棒性?
参考文献:待整理
边栏推荐
- Tape SVG animation JS effect
- Report on operation mode and future development trend of global and Chinese propenyl isovalerate industry from 2022 to 2028
- Ultra vires vulnerability & Logic vulnerability (hot) (VIII)
- The file containing the file operation vulnerability (6)
- svg线条动画背景js特效
- Arbitrary file download of file operation vulnerability (7)
- Hibernate学习2 - 懒加载(延迟加载)、动态SQL参数、缓存
- SAP PA certificate for no birds, which can be tested by new peers
- MySQL日志管理
- Hibernate学习3 - 自定义SQL
猜你喜欢

QT display RGB data

svg+js键盘控制路径

Why do more and more physical stores use VR panorama? What are the advantages?

∞ symbol line animation canvasjs special effect

【面试题】什么是事务,什么是脏读、不可重复读、幻读,以及MySQL的几种事务隔离级别的应对方法

Tiktok practice ~ upload and release app video

Time unified system

Ultra vires vulnerability & Logic vulnerability (hot) (VIII)

VR全景制作的优势是什么?为什么能得到青睐?

Sword finger offer merges two sorted lists
随机推荐
Classic interview questions and answers for embedded engineers
Global and Chinese tetrahydrofurfuryl butyrate industry operation pattern and future prospect report 2022 ~ 2028
【面试题】instancof和getClass()的区别
∞ symbol line animation canvasjs special effect
DO280OpenShift访问控制--加密和ConfigMap
Leetcode No.10 regular expression matching
Analysis report on operation mode and future development of global and Chinese methyl cyclopentanoate industry from 2022 to 2028
[proteus simulation] example of using timer 0 as a 16 bit counter
创意SVG环形时钟js特效
The new employee of the Department after 00 is really a champion. He has worked for less than two years. The starting salary of 18K is close to me when he changes to our company
Signal integrity (SI) power integrity (PI) learning notes (I) introduction to signal integrity analysis
Investment analysis and prospect forecast report of global and Chinese triglycine sulfate industry from 2022 to 2028
Start QT program
水库大坝安全监测
Global and Chinese 3-Chlorobenzaldehyde industry operation mode and future development trend report 2022 ~ 2028
JPA学习1 - 概述、JPA、JPA核心注解、JPA核心对象
Sitelock helps you with the top ten common website security risks
技术分享| WVP+ZLMediaKit实现摄像头GB28181推流播放
Tremblement de terre réel ~ projet associé unicloud
Human body transformation vs digital Avatar