当前位置:网站首页>Xiaodu Xiaodu is here!
Xiaodu Xiaodu is here!
2022-08-05 06:15:00 【Chengyun Technology】
What is Intelligent Speech Recognition?
Simply put
Intelligent speech recognition is the human voice signal
The process of converting to text.
We usually come into contact with
Speech recognition, face recognition, OCR, etc.
All belong to the perceptual intelligence in artificial intelligence
Its core function is
Transforms information from the physical world into computer-processable information
Provide the foundation for subsequent cognitive intelligence.
The hierarchy of needs that speech recognition can meet
01Information synchronization between people
The voice information converted into text, due to the lack of time axis constraints, can be obtained by human eyes much faster than ears in the same order of magnitude.
02Search & Semantic Extraction
Using semantic modeling to retrieve words/semantics that are more concerned in some business scenarios, or extract them and record them in a structured way.
03Human Interaction
Interact with machines/virtual assistants in a more natural way, enabling anthropomorphic conversations, manipulating devices, or obtaining answers to questions.
04Data Mining
By clustering data or opening up with various dimensional data systems, value mining can be performed on the semantic data of individuals/populations/specific fields.
Closed Domain Identification
1 Definition:
The recognition range is a pre-specified set of words/words.
The algorithm only performs speech recognition within the set of closed-domain recognition words preset by the developer, and will reject speech outside the range.
2. Product form :
Streaming - Simultaneous acquisition.
3. Typical application scenarios:
Scenarios that do not involve multiple rounds of interaction and multiple semantic statements.
For example, for smart home and TV boxes with simple command interaction, the voice control commands are generally only "open the curtains", "open the central station" and so on.
Open Domain Identification
1. Definition
There is no need to specify a set of recognized words in advance, the algorithm will recognize the entire range of the large set of languages.
2. Product form
1. Streaming upload - synchronous acquisition
The application/software will automatically record the speaker's voice and upload it to the cloud continuously, and the speaker can see the returned text in real time after speaking.
2. Recorded audio file upload - asynchronous acquisition
Audio duration is generally <3/5 hours.The user needs to call the software interface or the hardware platform to pre-record the audio in the specified format, and use the interface provided by the voice cloud service provider to upload the audio. After the upload is complete, the connection can be disconnected.The user obtains the result by polling the voice cloud server or using the callback interface.
3.The recorded audio file is uploaded and obtained synchronously. The audio duration is generally less than <1 minute.Users need to pre-record the audio in the specified format and upload the audio using the interface provided by the voice cloud service provider.
4. Typical application scenarios
1. Mainly in input scenarios, such as input method, real-time subtitles during conferences/court trials.
2. Audio/video subtitle configuration that has been recorded; customer service voice quality inspection and UGC voice content review scenarios with low real-time requirements.
3. As a supplement to the first two, it is suitable for scenarios where the audio recording interface cannot be used to upload real-time audio streams, or the real-time requirements for result acquisition are relatively high.
边栏推荐
- Getting Started 04 When a task depends on another task, it needs to be executed in sequence
- OpenCV3.0 is compatible with VS2010 and VS2013
- ACL 和NAT
- Call the TensorFlow Objection Detection API for object detection and save the detection results locally
- 【Day5】软硬链接 文件存储,删除,目录管理命令
- js动态获取屏幕宽高度
- spark source code - task submission process - 1-sparkSubmit
- Cloud computing - osi seven layers and TCP\IP protocol
- [Day8] (Super detailed steps) Use LVM to expand capacity
- 错误类型:反射。ReflectionException:无法设置属性“xxx”的“类”xxx”与价值“xxx”
猜你喜欢

Mongodb query analyzer parsing
![[Day6] File system permission management, file special permissions, hidden attributes](/img/ec/7fb3fa671fac8abf389844c0f4fbe7.png)
[Day6] File system permission management, file special permissions, hidden attributes

Switch principle

VLAN详解及实验

云计算——osi七层与TCP\IP协议
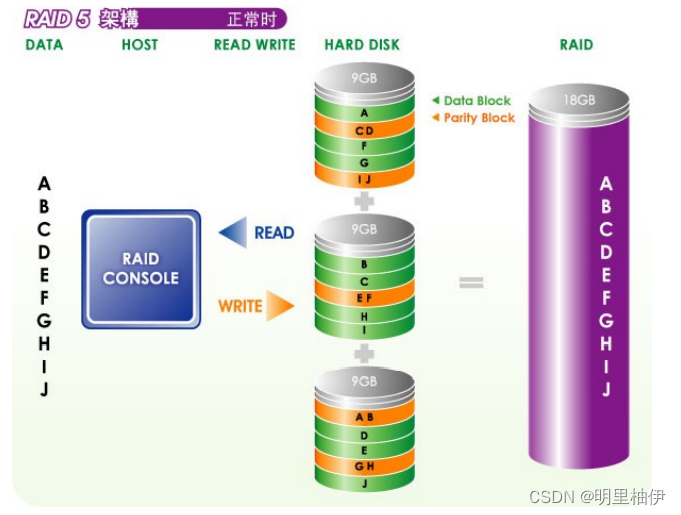
【Day8】RAID Disk Array

Network wiring and digital-to-system conversion
正则表达式小实例--验证邮箱地址

Getting Started 04 When a task depends on another task, it needs to be executed in sequence
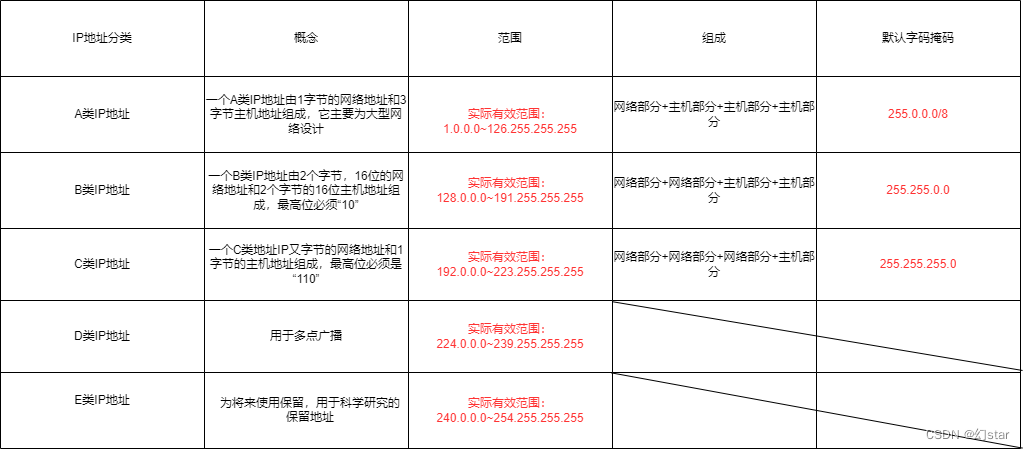
IP地址及子网的划分
随机推荐
Quick question and quick answer - FAQ of Tencent Cloud Server
VLAN介绍与实验
Apache configure reverse proxy
硬盘分区和永久挂载
The problem of redirecting to the home page when visiting a new page in dsf5.0
To TrueNAS PVE through hard disk
lvm logical volume and disk quota
vim的三种模式
VLAN details and experiments
图片压缩失效问题
[Day5] Soft and hard links File storage, deletion, directory management commands
增长:IT运维发展趋势报告
入门文档05-2 使用return指示当前任务已完成
Getting Started Documentation 12 webserve + Hot Updates
Getting Started 11 Automatically add version numbers
lvm逻辑卷及磁盘配额
Spark source code-task submission process-6.1-sparkContext initialization-create spark driver side execution environment SparkEnv
Logical volume creation
【Machine Learning】1 Univariate Linear Regression
实力卷王LinkSLA,实现运维工程师快乐摸鱼