当前位置:网站首页>How to solve the problem of large distribution gap between training set and test set
How to solve the problem of large distribution gap between training set and test set
2022-07-24 05:57:00 【Didi'cv】
StratifiedKFold
You can borrow sklearn Medium StratifiedKFold Come to realize K Crossover verification , At the same time, split the data according to the proportion of different categories in the label , So as to solve the problem of sample imbalance .
#!/usr/bin/python3
# -*- coding:utf-8 -*-
""" @author: xcd @file: StratifiedKFold-test.py @time: 2021/1/26 10:14 @desc: """
import numpy as np
from sklearn.model_selection import KFold, StratifiedKFold
X = np.array([
[1, 2, 3, 4],
[11, 12, 13, 14],
[21, 22, 23, 24],
[31, 32, 33, 34],
[41, 42, 43, 44],
[51, 52, 53, 54],
[61, 62, 63, 64],
[71, 72, 73, 74]
])
y = np.array([1, 1, 1, 1, 1, 1, 0, 0])
sfolder = StratifiedKFold(n_splits=4, random_state=0, shuffle=True)
folder = KFold(n_splits=4, random_state=0, shuffle=False)
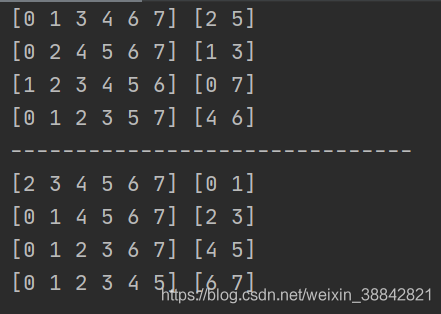
for train, test in sfolder.split(X, y):
print(train, test)
print("-------------------------------")
for train, test in folder.split(X, y):
print(train, test)
for fold, (train_idx, val_idx) in enumerate(sfolder.split(X, y)):
train_set, val_set = X[train_idx], X[val_idx]
Follow KFold There is a clear contrast ,StratifiedKFold Usage is similar. Kfold, But it is stratified sampling , Make sure the training set , The proportion of samples in the test set is the same as that in the original data set .
###
Parameters
n_splits : int, default=3
Number of folds. Must be at least 2.
shuffle : boolean, optional
Whether to shuffle each stratification of the data before splitting into batches.
random_state :
int, RandomState instance or None, optional, default=None
If int, random_state is the seed used by the random number generatorIf RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used
by `np.random`. Used when ``shuffle`` == True.
###
边栏推荐
- OpenWRT快速配置Samba
- [MYCAT] MYCAT sets up read-write separation
- 绘制轮廓 cv2.findContours函数及参数解释
- AD1256
- 学习率余弦退火衰减之后的loss
- 读取csv文件的满足条件的行并写入另一个csv中
- [activiti] process variables
- tensorflow和pytorch框架的安装以及cuda踩坑记录
- js星星打分效果
- Delete the weight of the head part of the classification network pre training weight and modify the weight name
猜你喜欢







![[activiti] process variables](/img/5e/34077833f6eb997e64f186d4773e89.png)
随机推荐
字符串方法以及实例
【USB Host】STM32H7 CubeMX移植带FreeRTOS的USB Host读取U盘,USBH_Process_OS卡死问题,有个值为0xA5A5A5A5
[MYCAT] Introduction to MYCAT
Raspberry pie is of great use. Use the campus network to build a campus local website
删除分类网络预训练权重的的head部分的权重以及修改权重名称
学习率优化策略
Numpy cheatsheet
信号与系统:希尔伯特变换
谷歌/火狐浏览器管理后台新增账号时用户名密码自动填入的问题
[deep learning] handwritten neural network model preservation
DeepSort 总结
String methods and instances
[USB host] stm32h7 cubemx porting USB host with FreeRTOS to read USB disk, usbh_ Process_ The OS is stuck. There is a value of 0xa5a5a5
[activiti] process variables
《统计学习方法(第2版)》李航 第22章 无监督学习方法总结 思维导图笔记
【深度学习】手写神经网络模型保存
PyTorch 单机多卡分布式训练
列表写入txt直接去除中间的逗号
Xshell远程访问工具
"Statistical learning methods (2nd Edition)" Li Hang Chapter 15 singular value decomposition SVD mind map notes and after-school exercise answers (detailed steps) SVD matrix singular value Chapter 15