当前位置:网站首页>CVPR 2022 oral | video text pre training new SOTA, HKU and Tencent arc lab launched excuse task based on multiple-choice questions
CVPR 2022 oral | video text pre training new SOTA, HKU and Tencent arc lab launched excuse task based on multiple-choice questions
2022-06-22 20:28:00 【Machine learning community】
This paper proposes a new excuse task for video text pre training , It's called a multiple-choice question (MCQ). Training assisted BridgeFormer Answer the multiple choice questions based on the video content , To learn fine-grained video and text features , And achieve efficient downstream retrieval . The study has been CVPR 2022 Included as Oral.
Two kinds of methods are mainly used in multimodal pre training for text video retrieval :“ Double current ” Method trains two separate coders to constrain video level and sentence level features , The local characteristics of each mode and the interaction between modes are ignored ;“ Single stream ” The method takes the video and text connection as the input of the joint encoder to fuse the modes , This leads to very inefficient downstream retrieval .
This paper presents a new excuse task with parameterized modules (pretext task), be called “ Multiple choice questions ”(MCQ), Through training BridgeFormer Answer the multiple choice questions based on the video content , To achieve fine-grained video and text interaction , And remove the auxiliary BridgeFormer, To ensure efficient retrieval efficiency .

Address of thesis :https://arxiv.org/abs/2201.04850
Code address :https://github.com/TencentARC/MCQ
1. background
A multimodal model for video text retrieval , Need to understand the video content 、 Text semantics 、 And the relationship between video and text . The existing video text pre training can be divided into two categories .
The first category “ Double current ” The method is shown in the figure below (a) Shown , Two separate coders are trained to acquire video level and sentence level features respectively , Use contrast to learn (contrastive learning) To optimize features . This method can achieve efficient downstream retrieval , Because we only need to use dot product to calculate the similarity of video and text features . But this method only constrains the final characteristics of the two modes , The local information of each mode is ignored , And fine-grained association between video and text .
The second category “ Single flow method ” Here's the picture (b) Shown , The video and text link is used as the input of the joint encoder to fuse the modes , And train a classifier to judge whether the video and text match . This approach can establish a correlation between local video and text features , But it is very inefficient in downstream retrieval , Because the text and every candidate video , Both need to be linked into the model to obtain the similarity .

The starting point of this paper is to set the advantages of the above two classes of methods , That is, while learning fine-grained video and text features , Achieve efficient downstream retrieval .
say concretely , Pictured above (c) Shown , Based on the structure of double encoder , This research further designs a parameterized module BridgeFormer As a link between local features of video and text . This study proposes a new excuse task to constrain BridgeFormer, because BridgeFormer It connects every layer of features of video and text , Yes BridgeFormer In turn, the constraints of will optimize the characteristics of video and text . Auxiliary BridgeFormer For pre training only , Removed during downstream retrieval , Thus, the efficient dual encoder structure can be used for retrieval .
2. inspire
Given a video and its corresponding text description , This study observed that the noun and verb phrases in the text contain rich semantic information .
As shown in the figure below , The text description of the video is :“ One is wearing shorts , The girl in the hat is dancing on the green grass ”. Among them , noun phrase “ shorts ” and “ Green grassland ” Corresponding to the local objects in the video , Verb phrases “ dance ” It can reflect the timing movement of the girl in the video . therefore , The research is done by erasing nouns and verb phrases from the text , To construct noun problem and verb problem respectively , Then the correct answer is naturally the erased phrase itself . For example, when you erase noun phrases “ Green grassland ”, It constitutes a noun problem “ One is wearing shorts , Where the girl in the hat is dancing ”, The answer is “ Green grassland ”. In the same way, delete the verb phrase “ dance ”, It forms the question of verbs “ One is wearing shorts , What is the girl in the hat doing on the green grass ”, The answer is “ dance ”.
This study proposes a parameterized module BridgeFormer The excuse task is called multiple choice (MCQ), Training BridgeFormer By asking for video features , Answer multiple-choice questions composed of text features , To achieve fine-grained video and text interaction . Remove on downstream retrieval BridgeFormer, To ensure efficient retrieval efficiency .

3. Method
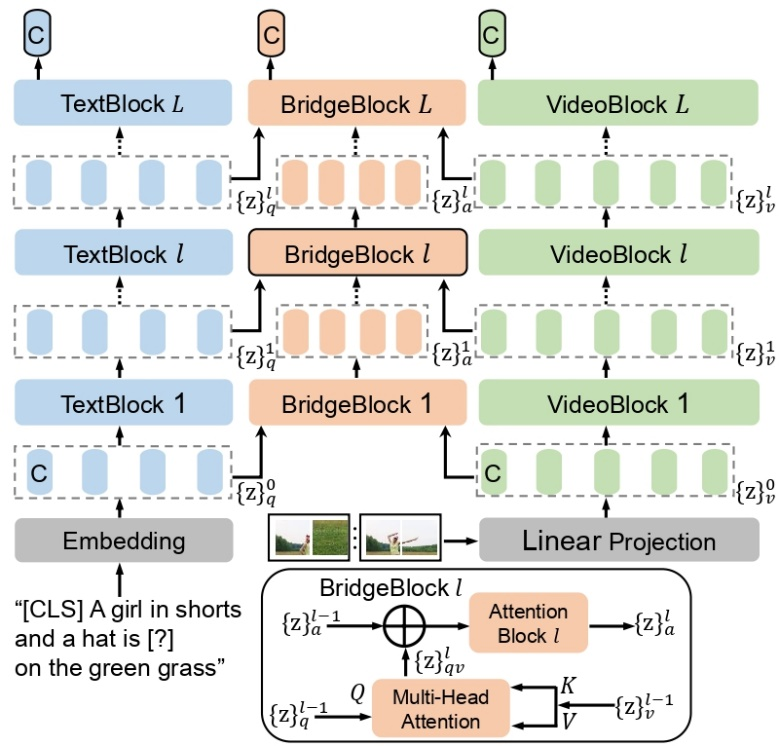
As shown in the figure below , The research method includes a video encoder VideoFormer, It is used to extract video features from the original video frames ; A text encoder TextFormer, Used to extract text features from natural language . This research is done by erasing noun phrases or verb phrases from text descriptions , To construct noun problem and verb problem respectively . In the form of comparative learning , Training BridgeFormer By asking for help VideoFormer Extracted local video features , Choose the right answer from multiple choices . here , Multiple options consist of all the erased phrases in a training batch .

This supplementary pre training goal will promote VideoFormer Extract the accurate spatial content in the video , bring BridgeFormer Be able to answer noun questions , And capture the sequential movement of objects in the video , bring BridgeFormer Be able to answer verb questions . Such a training mechanism makes VideoFormer It can better perceive local objects and temporal dynamics in the video . The association between local features of video and text has also been effectively established in the form of questions and answers . because BridgeFormer It connects every layer of features of video and text , Yes BridgeFormer The constraints of will further optimize the characteristics of video and text . So auxiliary BridgeFormer For pre training only , It can be removed during downstream retrieval , Thus, the efficient dual encoder structure is preserved .
4. Pre training process
As shown in the figure below , The study pre training process consists of three parts , To optimize the three unified contrastive learning (contrastive learning) Form of pre training objectives :
1. Shorten the distance between video and text positive samples , And the distance between the negative samples and the features ( A video and its corresponding text description are regarded as positive sample pairs , Otherwise, it is a negative sample pair ).
2. Training BridgeFormer Answer the noun question , That is to pull closer BridgeFormer The characteristics of the output noun responses and TextFormer The distance between the noun features of the output correct answer , It also widens the distance between noun response features and other noun features .
3. Training BridgeFormer Answer the verb question , That is to pull closer BridgeFormer The characteristics of the output verb responses and TextFormer The distance between the verb features of the output correct answer , It also widens the distance between verb response features and other verb features .

Here, the study uses contrastive learning to optimize the pre training objectives in the form of multiple-choice questions , Instead of using the traditional “masked word prediction”, That's random mask Some words in a sentence , The training model predicts that mask 's words . This approach has the following three advantages :
Conventional “masked word prediction” The constraint model predicts that mask 's words , Will make the model focus on decoding low-level The word itself , It destroys the pair of modes high-level Learning of feature expression . by comparison , Of the study MCQ Draw closer in the form of comparative learning BridgeFormer Output response characteristics and TextFormer The distance between the output answer features , So that the model can focus on learning between modes high-level Semantic information .
This research erases the verbs and noun phrases with clear semantic information in the text to construct meaningful problems , The traditional method is just random mask Some words that may not have any semantic information .
Because the characteristics of the question and the characteristics of the answer are determined by TextFormer obtain , This approach can be seen as an data augmentation, To enhance TextFormer Semantic understanding of natural language .
Ablation experiments also showed , Compared to traditional “masked word prediction”, The study contrasts learning forms with excuse tasks MCQ Better experimental results have been obtained in the downstream evaluation .
5. Model structure
As shown in the figure below , The research model includes a video encoder VideoFormer, A text encoder TextFormer, And an auxiliary encoder BridgeFormer. Each encoder consists of a series of transformer Module composition .TextFormer The output text features of each layer of questions are considered as query,VideoFormer The output video features of each layer are regarded as key and value, Sent in BridgeFormer The corresponding layer implements a cross modal attention mechanism , To get the response characteristics .
6. visualization
6.1 BridgeFormer How to answer the noun question
The following figure shows the attention between visual noun problem features and video features . In the second and fifth columns , The blue noun phrases in the text are erased , Constitute a noun problem Q1. In the third and sixth Columns , The green noun phrases in the text are erased , Constitute a noun problem Q2. In the first example , When “ An old couple ” Be erased , Constitute a problem “ Who is drinking coffee ”,BridgeFormer Focus on video features that depict people's faces . And when “ A plate of bread ” Be erased , Constitute a problem “ There was something on the table in front of them ”,BridgeFormer Focus on the object area on the table . In the fourth example , When “ football ” Be erased , Constitute a problem “ What are parents and children playing ”,BridgeFormer Focus on the can and verb “ play ” On the characteristics of the objects constituting the association . And when “ Country meadows ” Be erased , Constitute a problem “ Where do parents and children play football ”,BridgeFormer Focus on the background features of the video . We can observe that ,BridgeFormer Pay attention to the video area with specific object information to answer the noun question , It shows that the VideoFormer It can extract accurate spatial content from video , also TextFormer Can understand the text semantics of the problem .

6.2 BridgeFormer How to answer the verb question
The following figure shows the attention between visual verb problem features and video features . The following figure shows three frames sampled from a video in turn . The blue verb phrases in the text have been erased , Form a verb problem . In the example on the left , When “ cut ” The verb is erased , Constitute a problem “ How a pair of hands are handling pizza ”,BridgeFormer Watch the movement of the tableware on the pizza . In the example on the right , When “ drink ” The verb is erased , Constitute a problem “ The man standing by the river is how to operate the hot tea ”,BridgeFormer Watch the movement of the hand holding the cup . We can observe that ,BridgeFormer Answer the verb question by focusing on the movement of the object , This shows that VideoFormer Capture the video sequence dynamics .

7. experiment
7.1 Pre training data
The research is in the image data set Google Conceptual Captions And video data sets WebVid-2M Pre training on , The former includes 3.3M Image - The text is right , The latter includes 2.5M In the video - The text is right . Considering the amount of calculation , The study did not use large-scale HowTo100M Data sets for pre training . however , The study used HowTo100M For large-scale text to video zero-shot Retrieve evaluation .
7.2 Downstream tasks
Text to video retrieval
The study was conducted in MSR-VTT、MSVD、LSMDC、DiDeMo and HowTo100M On the Internet . Two evaluation criteria are adopted , Include zero-shot and fine-tune.
Action recognition
The study was conducted in HMDB51 and UCF101 On the Internet . Three evaluation criteria are adopted , Include linear、fine-tune and zero-shot. among zero-shot Motion recognition can be regarded as video to text retrieval , The name of the action category is regarded as the text description .
7.3 experimental result
stay MSR-VTT On dataset , The search results from text to video are shown in the following table . The row above the table shows zero-shot Evaluation results , The following line shows fine-tune The evaluation results of . You can see that the method in this article is compared with the previous method , It has been greatly improved under both evaluation benchmarks . The model used in this study directly takes the original video frame as the input , Do not rely on any pre extracted video features .

stay MSVD、LSMDC、DiDeMo On , The search results from text to video are shown in the following table . The model in this paper is also in zero-shot and fine-tune Under the benchmark of , Have achieved the best results .

The study further uses CLIP To initialize this model , stay MSR-VTT、MSVD and LSMDC On , The search results from text to video are shown in the following table . Excuse task of the study MCQ It can also be improved based on CLIP Video text pre training performance .

stay HMDB51 and UCF101 On the evaluation zero-shot The action recognition results are shown in the figure below (a) Shown , This method obviously goes beyond baseline. The study further passed the evaluation linear Motion recognition is used to measure the ability of unimodal video representation of the model . Here's the picture (b) Shown , In this paper, the method is pre trained on the video data with shorter duration , Ideal results have been achieved . This shows the excuse task of the study MCQ Through the effective use of text semantics , Enhance video representation learning .

More experimental results and ablation experiments , See paper .
8. summary
This paper proposes a new excuse task for video text pre training , It's called a multiple-choice question (MCQ). This excuse task enhances the fine-grained Association of local video and text features , And achieve efficient downstream retrieval . A parameterized module BridgeFormer Be trained by using video features , Answer multiple-choice questions composed of text features , And can be removed during downstream tasks . In this paper, the model is applied to text to video retrieval and zero sample motion recognition , Shows MCQ The effectiveness of this excuse task .
Technical communication
At present, a technical exchange group has been opened , Group friends have exceeded 2000 people , The best way to add notes is : source + Interest direction , Easy to find like-minded friends
- The way ①、 Send the following picture to wechat , Long press recognition , The background to reply : Add group ;
- The way ②、 WeChat search official account : Machine learning community , The background to reply : Add group ;
- The way ③、 You can add micro signals directly :mlc2060. Make a remark when adding : Research direction + School / company +CSDN, that will do . Then we can pull you into the group .

Research directions include : machine learning 、 data mining 、 object detection 、 Image segmentation 、 Target tracking 、 Face detection & distinguish 、OCR、 Attitude estimation 、 Super resolution 、SLAM、 Medical imaging 、Re-ID、GAN、NAS、 Depth estimation 、 Autopilot 、 Reinforcement learning 、 Lane line detection 、 Model pruning & Compress 、 Denoise 、 Defogging 、 Go to the rain 、 Style transfer 、 Remote sensing image 、 Behavior recognition 、 Video understanding 、 Image fusion 、 image retrieval 、 Paper Submission & communication 、PyTorch、TensorFlow and Transformer etc. .
Be sure to note : Research direction + School / company + nickname ( Such as Transformer Or target detection + Hand in + kaka ), Note according to the format , Can be passed and invited into the group faster .
边栏推荐
- 【Proteus仿真】74LS138译码器流水灯
- R语言数据预处理、把类型变量转化为因子变量,把数据集转化为h2o格式、数据集划分(训练集、测试集、验证集)
- Nestjs integrates config module and Nacos to realize configuration unification
- R语言基于h2o包构建二分类模型:使用h2o.glm构建正则化的逻辑回归模型、使用h2o.auc计算模型的AUC值
- Teach you how to create SSM project structure in idea
- Be careful with MySQL filesort
- 3个月自学自动化测试,薪资从4.5K到15K,鬼知道我经历了什么?
- Nestjs 集成 config module 与 nacos 实现配置化统一
- Which securities firm is better to choose for opening an account in flush? Is it safe to open a mobile account?
- Matplotlib set axis scale interval
猜你喜欢

Introduction to async profiler

ROS from entry to mastery (VIII) common sensors and message data

【Proteus仿真】8x8Led点阵数字循环显示
NFT 中可能存在的安全漏洞

He was in '98. I can't play with him

Three months of self-taught automatic test, salary from 4.5K to 15K, who knows what I have experienced?

怎样实现网页端im即时通讯中的@人功能

Storage structure of graph (adjacency matrix)

MySQL Basics - functions
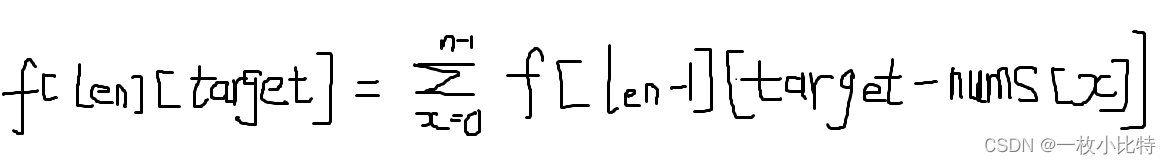
完全背包如何考虑排列问题
随机推荐
6月第3周B站榜单丨飞瓜数据UP主成长排行榜(哔哩哔哩平台)发布!
Oh, my God, it's a counter attack by eight part essay
Dynamicdatabasesource, which supports the master-slave database on the application side
元宇宙中的云计算,提升你的数字体验
阿波罗使用注意事项
【Proteus仿真】74LS138译码器流水灯
软件压力测试有哪些方法,如何选择软件压力测试机构?
年中大促 | 集成无忧,超值套餐 6 折起
关于放大器失真的原因你了解多少呢?
Cross domain cors/options
运用span-method巧妙实现多层table数据的行合并
Summer Challenge [FFH] Hongmeng machine learning journey from scratch NLP emotion analysis
【深入理解TcaplusDB技术】TcaplusDB 表管理——修改表
一文搞懂 MySQL 中 like 的索引情况
Containerd容器运行时(2):yum安装与二进制安装,哪个更适合你?
[deeply understand tcapulusdb technology] tcapulusdb table management - rebuild table
Goldfish rhca memoirs: do447 managing user and team access -- creating and managing ansible tower users
请你描述下从浏览器上输入一个url到呈现出页面的整个过程。
I wrote a telnet command myself
[resolved] -go_ out: protoc-gen-go: Plugin failed with status code 1.