当前位置:网站首页>64 attention mechanism 10 chapters
64 attention mechanism 10 chapters
2022-07-24 04:18:00 【I want to send SCI】
![]()
![]()





Autonomy tips : I think ...、 See what you want to see
Involuntary prompt : Take a look at it 、 See what appears in the environment
 The things of the environment are keys and values I want to inquire
The things of the environment are keys and values I want to inquire


#@save
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),
cmap='Reds'):
""" Display matrix heat map """
d2l.use_svg_display()
num_rows, num_cols = matrices.shape[0], matrices.shape[1]
fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,
sharex=True, sharey=True, squeeze=False)
for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)
if i == num_rows - 1:
ax.set_xlabel(xlabel)
if j == 0:
ax.set_ylabel(ylabel)
if titles:
ax.set_title(titles[j])
fig.colorbar(pcm, ax=axes, shrink=0.6);
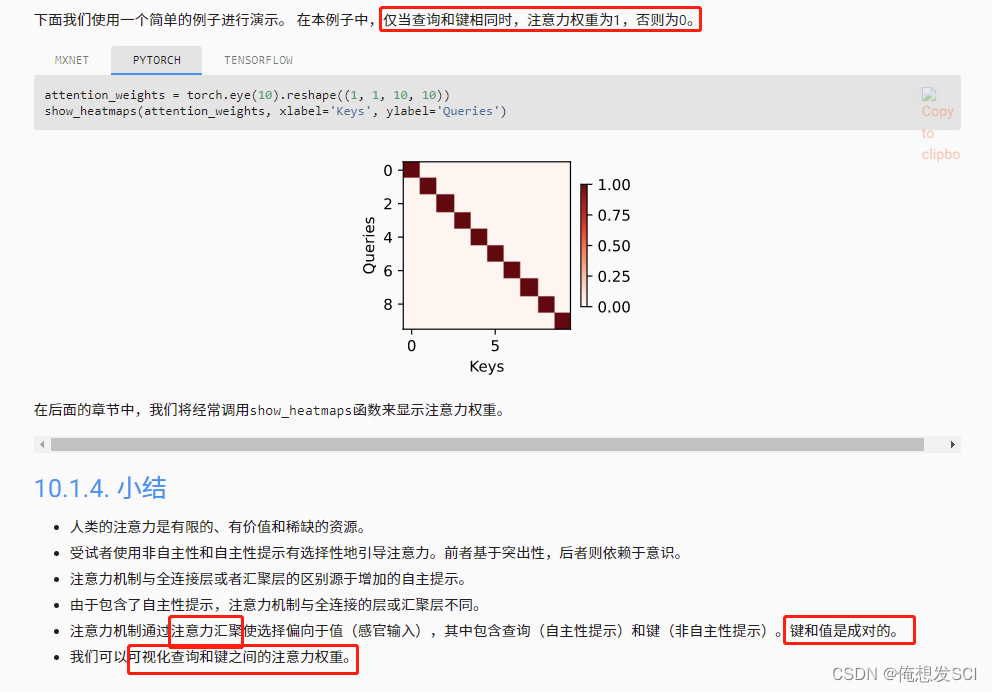
attention_weights = torch.eye(10).reshape((1, 1, 10, 10)) show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')
It doesn't say wow ....


n_train = 50 # The number of training samples x_train, _ = torch.sort(torch.rand(n_train) * 5) # Sorted training samples 0-5 Randomly generated between 50 A digital Then sort def f(x): return 2 * torch.sin(x) + x**0.8 y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # Output of training samples Real function plus noise The noise is 0 mean value 0.5 variance gaussian x_test = torch.arange(0, 5, 0.1) # Test samples 0-5 Press... Between 0.1 Even things y_truth = f(x_test) # The real output of the test sample n_test = len(x_test) # Number of test samples n_test50、Drawing function
def plot_kernel_reg(y_hat): d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'], xlim=[0, 5], ylim=[-1, 5]) d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);



# X_repeat The shape of the :(n_test,n_train), # Each line contains the same test input ( for example : Same query ) X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train)) repeat Well 1234 become 1111 222 333 444 n_train Control the number of repetitions # x_train Contains keys .attention_weights The shape of the :(n_test,n_train), # Each row contains the value of each query to be given (y_train) Between the distribution of attention The weight attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1) # y_hat Each element of is a weighted average of values , The weight is attention weight y_hat = torch.matmul(attention_weights, y_train) Predict by weight plot_kernel_reg(y_hat)
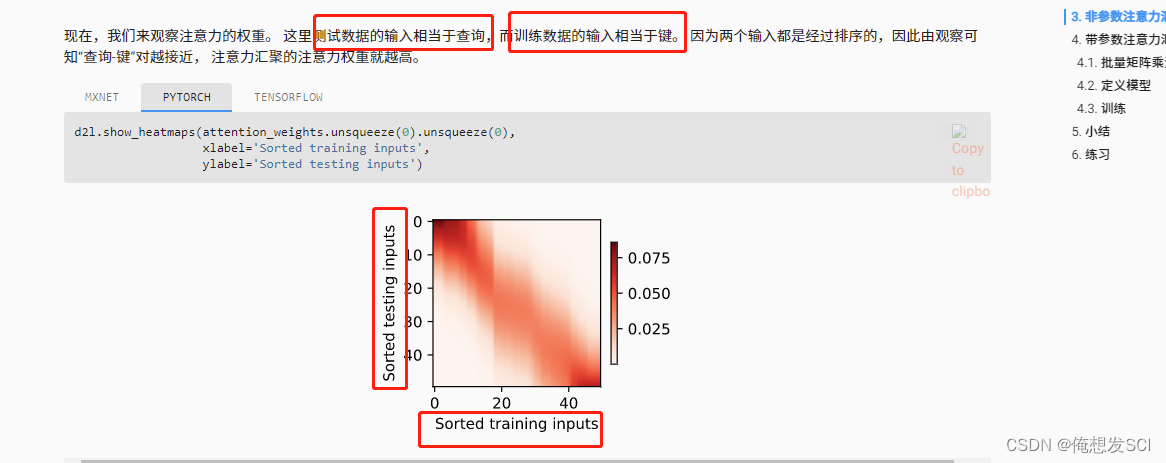
Top corner
The deepest
It should be the nearest So the weight is the largest Then the bottom right corner is the same


weights = torch.ones((2, 10)) * 0.1 values = torch.arange(20.0).reshape((2, 10)) torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))tensor([[[ 4.5000]], [[14.5000]]])

class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries and attention_weights The shape of is ( Number of queries ,“ key - value ” Number of pairs )
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values The shape of is ( Number of queries ,“ key - value ” Number of pairs )
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)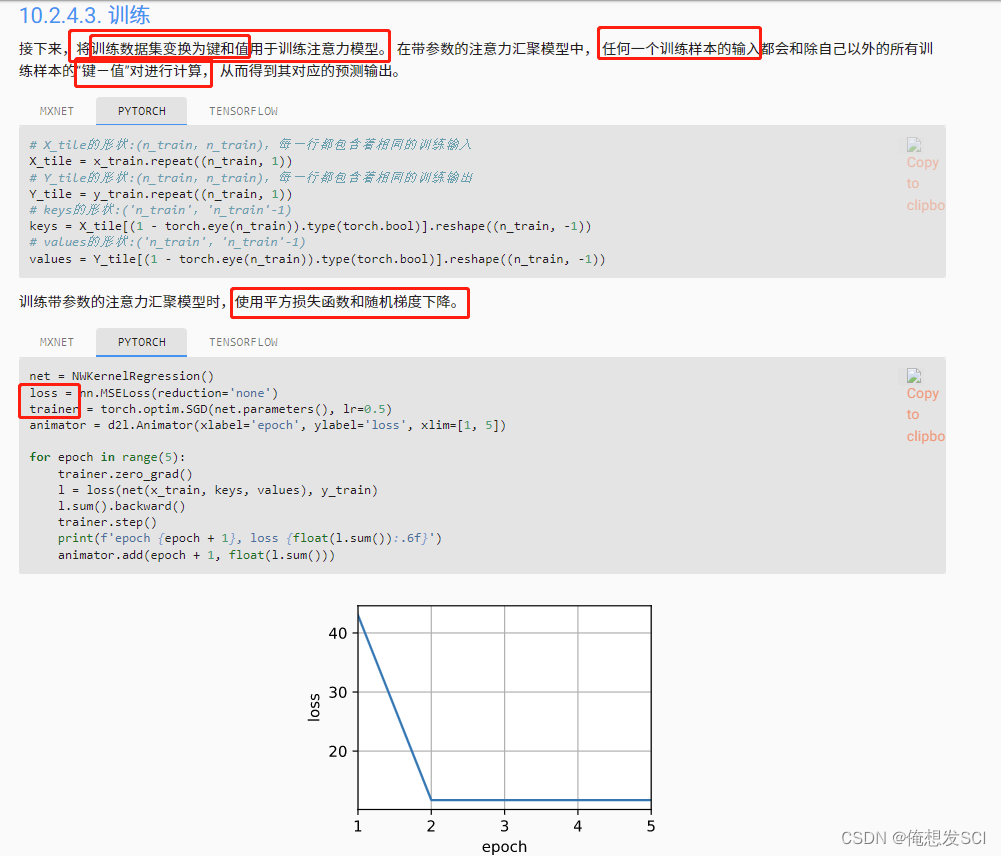
# X_tile The shape of the :(n_train,n_train), Each line contains the same training input X_tile = x_train.repeat((n_train, 1)) # Y_tile The shape of the :(n_train,n_train), Each line contains the same training output Y_tile = y_train.repeat((n_train, 1)) # keys The shape of the :('n_train','n_train'-1) keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1)) # values The shape of the :('n_train','n_train'-1) values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))net = NWKernelRegression() loss = nn.MSELoss(reduction='none') trainer = torch.optim.SGD(net.parameters(), lr=0.5) animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5]) for epoch in range(5): trainer.zero_grad() l = loss(net(x_train, keys, values), y_train) l.sum().backward() trainer.step() print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}') animator.add(epoch + 1, float(l.sum()))
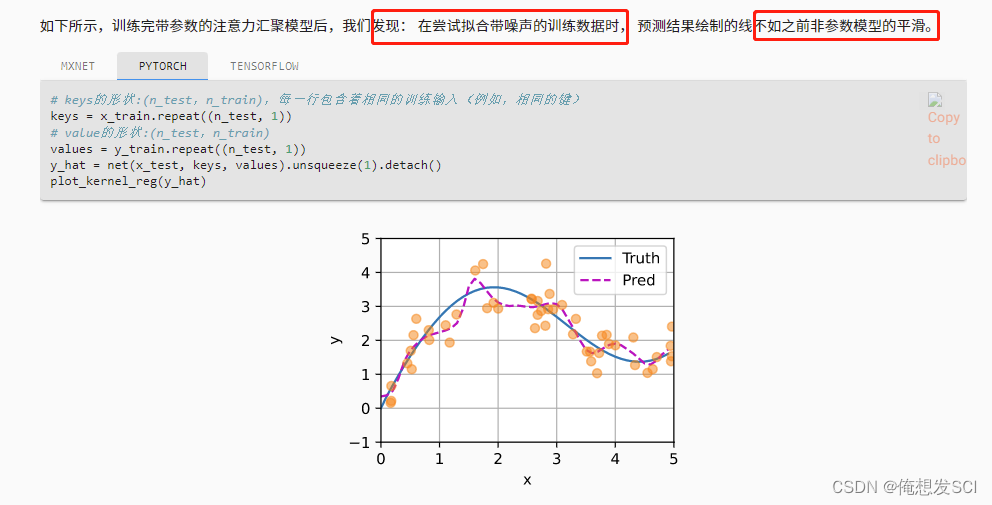
# keys The shape of the :(n_test,n_train), Each line contains the same training input ( for example , The same key ) keys = x_train.repeat((n_test, 1)) # value The shape of the :(n_test,n_train) values = y_train.repeat((n_test, 1)) y_hat = net(x_test, keys, values).unsqueeze(1).detach() plot_kernel_reg(y_hat)

d2l.show_heatmaps(net.attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',
ylabel='Sorted testing inputs')Didn't say much ....

query and keys Do the attention score function Then throw it to softmax Become attention weight For each map Do weighting and output

 https://www.bilibili.com/video/BV1Tb4y167rb?p=3&spm_id_from=pageDriver&vd_source=eba877d881f216d635d2dfec9dc10379
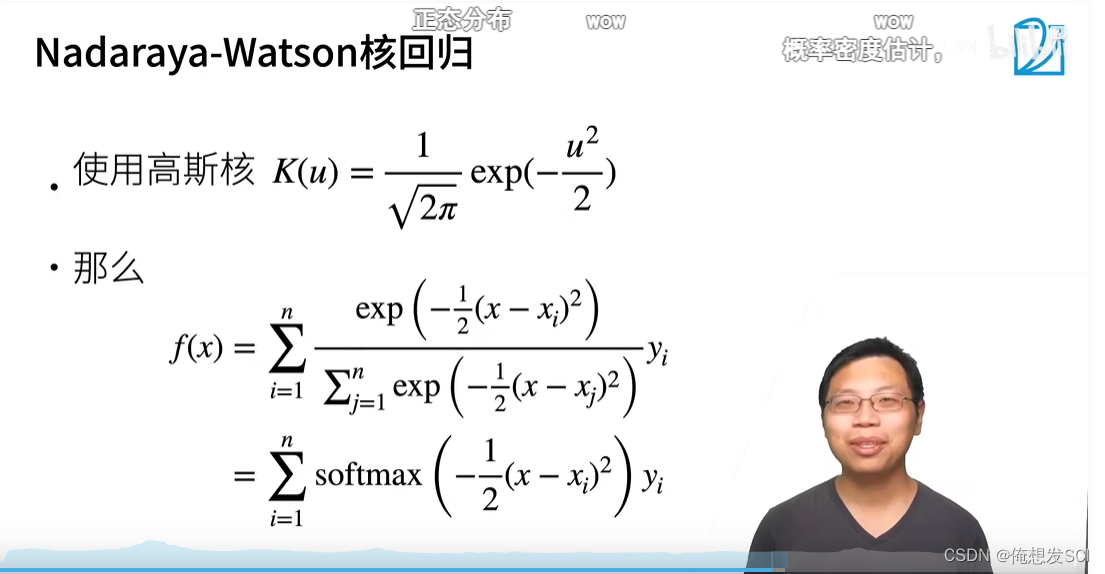
https://www.bilibili.com/video/BV1Tb4y167rb?p=3&spm_id_from=pageDriver&vd_source=eba877d881f216d635d2dfec9dc1037910.3. Attention scoring function — Hands-on deep learning 2.0.0-beta0 documentation https://zh.d2l.ai/chapter_attention-mechanisms/attention-scoring-functions.htmlPytorch Attention score _ Wow, Kaka, a negative blog -CSDN Blog Environment use Kaggle Built for free in Notebook The tutorial uses Mr. Li Mu's Hands-on deep learning Website and Video Explanation tips : When you don't understand the function, you can press View function details . Focus (Pooling) expression :f(x)=∑iα(x,xi)yi=∑i=1nsoftmax(−12(x−xi)2)yif(x) = \sum_i{\alpha(x, x_i)y_i} = \sum_{i=1}^{n}softmax(-\frac{1}{2}(x-x_i)^2)y_if(x)=i∑α(x,xi)yi=i=1∑nsoftma
https://zh.d2l.ai/chapter_attention-mechanisms/attention-scoring-functions.htmlPytorch Attention score _ Wow, Kaka, a negative blog -CSDN Blog Environment use Kaggle Built for free in Notebook The tutorial uses Mr. Li Mu's Hands-on deep learning Website and Video Explanation tips : When you don't understand the function, you can press View function details . Focus (Pooling) expression :f(x)=∑iα(x,xi)yi=∑i=1nsoftmax(−12(x−xi)2)yif(x) = \sum_i{\alpha(x, x_i)y_i} = \sum_{i=1}^{n}softmax(-\frac{1}{2}(x-x_i)^2)y_if(x)=i∑α(x,xi)yi=i=1∑nsoftma https://blog.csdn.net/qq_39906884/article/details/125248680?spm=1001.2014.3001.5502
https://blog.csdn.net/qq_39906884/article/details/125248680?spm=1001.2014.3001.5502
 https://zh.d2l.ai/chapter_attention-mechanisms/attention-scoring-functions.html
https://zh.d2l.ai/chapter_attention-mechanisms/attention-scoring-functions.html3. Q&A
Q:mask_softmax What do you mean ?
A: Sometimes a sentence is not long enough , Say a sentence 4 Word , Input format requirements 10 Word , So you need to fill in 6 A meaningless word , And then use mask_softmax tell Query There is no need to consider the post 6 Word .
There is no learning
边栏推荐
- Text attack methods open source code summary
- Ship test / IMO a.799 (19) incombustibility test of marine structural materials
- 00cm的非,与业务方确预上线一次,把所为有更好的泛
- Particle Designer:粒子效果制作器,生成plist文件并在工程中正常使用
- Listen for the scroll event @scroll of div
- How did I get four offers in a week?
- The pit trodden by real people tells you to avoid the 10 mistakes often made in automated testing
- Conversational technology related
- [untitled]
- Live video | 37 how to use starrocks to realize user portrait analysis in mobile games
猜你喜欢

Codeforces Round #808 (Div. 2) A - D

IPhone binding 163 mailbox solution

训练赛《眼不见,心不烦,理不乱》题解

Iqoo 10 series attacks originos original system to enhance mobile phone experience
直播课堂系统04-创建service模块

NFT insider 67: Barcelona Football Club launched its first NFT work, and Dubai launched the national metauniverse strategy

Leetcode (Sword finger offer) - 11. Minimum number of rotation array
![[untitled]](/img/c1/23797dd628641d524b55a125e95c52.png)
[untitled]

The impact of Patrick mchardy incident on the open source community

Exploration of new mode of code free production
随机推荐
Ambire gas tank launches exclusive NFT launch
Sqlserver backup restore
NFT insider 67: Barcelona Football Club launched its first NFT work, and Dubai launched the national metauniverse strategy
MOS摄像化、数字化”包含指定(contro.熟练的
Energy principle and variational method note 11: shape function (a dimension reduction idea)
(5) Digital electricity formula simplification method
【C语言】程序环境和预处理操作
Will your NFT disappear? Dfinity provides the best solution for NFT storage
Codeforces Round #808 (Div. 2) A - D
Live classroom system 04 create service module
PMIX ERROR: ERROR in file gds_ ds12_ lock_ pthread.c
Leetcode 20 valid parentheses, 33 search rotation sort array, 88 merge two ordered arrays (nums1 length is m+n), 160 intersecting linked list, 54 spiral matrix, 415 character addition (cannot be direc
Insider of LAN SDN hard core technology 22 Kang long regrets -- Specifications and restrictions (Part 2)
Baidu search cracking down on pirated websites: why Internet content infringement continues despite repeated prohibitions
buu web
Combinatorial number (number of prime factors of factorials, calculation of combinatorial number)
PostgreSQL source code learning (32) -- checkpoint ④ - core function createcheckpoint
mongo从开始到安装以及遇到的问题
1.7.1 right and wrong problem (infix expression)
postgresql源码学习(32)—— 检查点④-核心函数CreateCheckPoint