当前位置:网站首页>Rebeco: using machine learning to predict stock crash risk
Rebeco: using machine learning to predict stock crash risk
2022-06-25 03:28:00 【Zhiyuan community】
1. Preface
Major developments in big data and machine learning are driving the frontier of quantitative investment . The enhancement of computing power promotes the deployment and use of machine learning models . Compared with the rule-based model , These models adopt a completely data-driven approach , Be able to model complex nonlinear relationships . It can potentially reveal systematic and repetitive patterns that simple linear models cannot capture .
for example , Some variables may only be when they exceed a certain threshold , Or when they are combined with other variables , Or they may only be able to predict underperforming stocks , To predict stock returns . In this white paper , We explored in depth how to use ML Technology can drive quantitative modeling to the next level . Let's also look at a specific example , Using machine learning model to predict individual stock price collapse .
The different uses of machine learning technology in quantitative investment are increasingly recognized by the academic literature . These models include relatively simple variable selection models , And a model that can identify the lead lag relationship between different asset returns . Machine learning technology has also been used in the complex depth learning model of statistical arbitrage . Overfitting has always been a key problem in quantitative strategy . When the amount of data and the number of variables increase , This is a bigger problem .
The risk here is , One can find the coincidence relationship between the variables observed in the past , And use it as a signal to build the portfolio , But in fact , This relationship will not be repeated in the future , Because there is no real underlying phenomenon . However , The machine learning toolkit contains solutions to avoid over fitting , Like regularization ( Variable selection ), Model averaging and cross validation .
2. Forecasting companies facing financial difficulties
Avoid investing in companies that will later encounter financial difficulties , It can help investors win the market . in other words , It is far from easy to find the companies that are most likely to face difficulties in the future . Although there are many features that can help predict this result , But they may do this most effectively in a non-linear way or in a particular combination . Fortunately, ,ML Technology is designed to meet this challenge .
One way to mark troubled companies is to look at bankruptcy filings or credit downgrades . However , There may be a fall in share prices before these events occur . For stock investors , It is more meaningful to predict stock price decline than to correctly predict bankruptcy filing or credit rating downgrade , Because these events may have been digested at the time of occurrence . therefore , We define a crash as a sharp fall in a company's share price relative to other stocks . This indicator captures Special risks , Not the turbulence of the whole market , We think it is very suitable for stock selection model , It is not used in asset allocation or factor timing models .
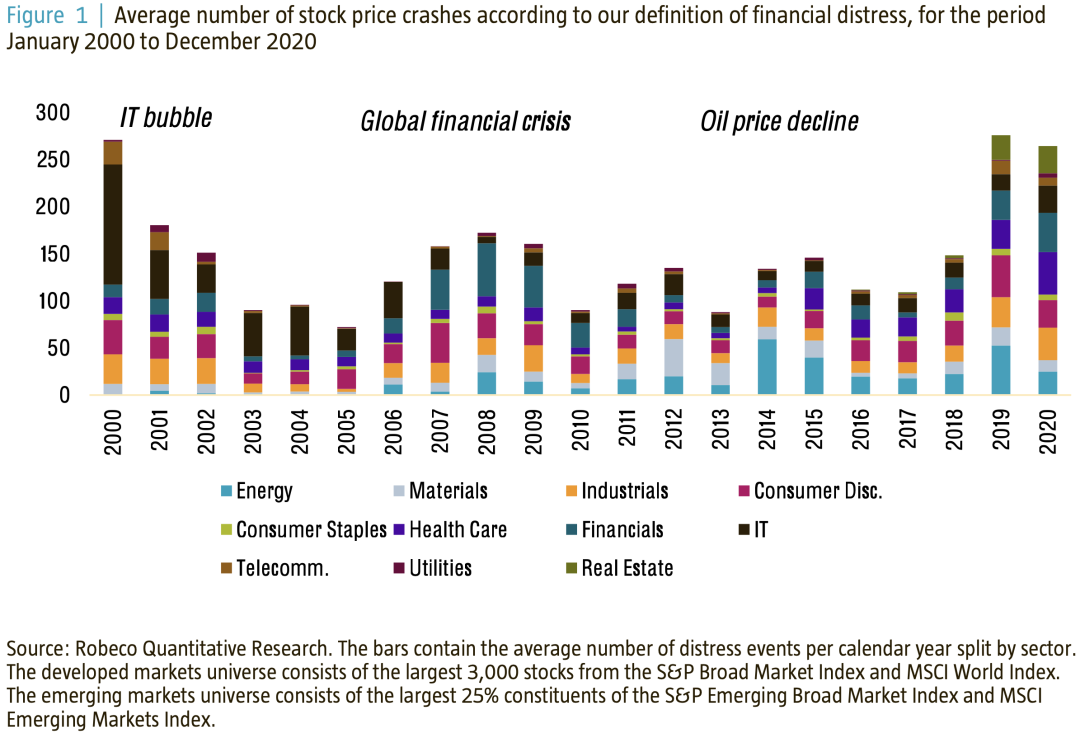
According to our definition of financial distress , chart 1 Show , The identified distress events are not concentrated in a few industries , But across multiple industries . in other words , The more troubled the industry , The more events that usually happen . in general , The number of share price crashes changes over time , Because cross-sectional fluctuations are usually higher in times of crisis .
If we want to use ML Model to identify companies facing financial difficulties , We need to provide it with a set of variables that may contain predictive information about the collapse of stock prices . stay ML In terms of , These predictors are called characteristics , The predicted variables are called targets .
Select the feature set as input to the algorithm , The purpose is to find the predictive relationship with the target , This is an important modeling step for any predictive model . For our purposes , The variables we choose include the classic financial crisis indicators , Such as distance-to-default, volatility, and return on equity. however , because ML The model aims to select the most important features from a larger set of variables , We also decided to obtain more granular features from the financial statements , Such as operating cash flow and short-term and long-term debt .
In our model , We only include features that we believe may be relevant to the identification of companies with the risk of share price collapse . for example , The initials of the company name or the color of the logo are not included , Because we can't relate them to economic principles , To explain why they might be able to predict crash risk . Because many company characteristics are only snapshots of a certain point in time , For example, profitability , We also include some characteristic time series in the model . In our view , This allows the algorithm to identify a series of events , If profitability declines , How to affect the risk of distress .
majority ML The algorithm is designed to filter out uncorrelated predictors from a large number of features , This process is also useful in avoiding over fitting . We believe that , Fewer redundant features reduce the opportunity to make investment decisions based on noise data . Besides , Reducing the number of features can speed up the training process of the algorithm . For our application , We trained three statistical models : Regularized logistic regression 、 Random forest and gradient enhanced tree .
Regularized logistic regression is a method based on classical linear regression model , But through logical transformation ( Measurements on a linear scale are converted to probabilities ), The probability used to predict binary results : In our case , Whether a company is in financial trouble . Regularization is ML Terms selected in the model , in other words , The technique selects only those variables that help predict binary results .
meanwhile , Random forest classification is based on multiple decision trees ( So there is the term forest ) The nonlinear model of , Take randomly selected features as nodes , Most of them voted to classify ( Determine which group an observation belongs to ), In our application, it is a binary decision . Last , Gradient enhanced tree algorithm is also based on decision tree , But it does not depend on a majority vote , Instead, change the weight of the feature , To reduce the number of false predictions .
These three prediction models are retrained annually according to their cross validation indicators . After retraining the model , We build signals for the coming year based on data we haven't seen before . When setting up this training test configuration , It is extremely important to ensure that there are no data leaks . This refers to the process of model training , When there is a data leak that has not been seen before , It will happen . Data leakage will lead to better backtracking test results , This is impossible to achieve in practice , Because the information that can be accessed in the future is obviously not available .
Each model makes independent predictions , These predictions are then combined into a set of predictions . In our view , A set is ML The only free lunch , This is similar to diversification in investment . chart 2 It shows the stock price of American financial stocks , And the overall distress risk predicted over time . In this case , We see 2007 After the middle of the year , Its probability of crisis is higher than 75%, And in the following months, it surpassed 90%. We also observed that , The company's share price is at 2007 year 1 Monthly peak , But from 2008 year 3 The month began to fall sharply , until 2008 year 9 In June the company filed for bankruptcy .

We use this method to generate 2000 - 2020 The probability of financial distress for a separate sample of developed and emerging market stocks during the year . For comparison , We also consider other predictors of distress risk , Such as stock return volatility 、 The stock market beta And default distance . For each subsample , We form according to the ranking of the probability of stock price collapse 20 Portfolio , And calculate their return over the next period of time .
chart 3 Describe the performance of the market , And the portfolio with the highest probability of financial distress among the four distress risk measures . For developed markets , The average market return during this period is 10.0%. meanwhile , be based on ML The bottom portfolio yield of the method strategy is only 2.3%. This is much lower than based on other traditional variables ( from 4.2% To 5.0%) The highest predication of the plight of the constructed portfolio yields .
In the case of emerging markets , We see even greater improvements . The average market return is 11.6%, The return rate of the portfolio based on other traditional crisis prediction indicators is 4.5% to 7.0% Between . On the other hand , be based on ML The portfolio of methods produces 1.5% The loss of , Therefore, it produces better results than the other three schemes .


This shows that , advanced ML Technology can potentially help us identify stocks with high distress risk . let me put it another way , If we avoid investing in these stocks , It is possible for us to improve the return of the quantitative stock portfolio .
3. The interpretability of the model
Just to understand ML How to help predict financial distress , We first examined 5% Industry classification of the riskiest stocks . Although we hope ML The method can automatically identify the industries that may encounter difficulties , But we don't want it to be dominated by industry choices . For our ML Model , We have no such restrictions on it , Because we do not include sector information in its feature set .
chart 5 Shows the industry distribution of the stock subset over time . We observed that , Most distressed stocks appear in 21 The information technology sector at the beginning of the century , And then there was 2008 - 2010 The financial sector during the year , The second is 2015 - 2019 Energy sector during the year . Although over time , There is a clear preference for these troubled industries , But we noticed that , The identified distress events are not just concentrated in a few industries . therefore , We believe this makes our ML Technology is a good candidate for use in the stock selection process .

It is also important to assess the importance of each selected feature .SHAP Value is the average value of the marginal contribution of the feature when predicting the target . This approach enables us to understand the economic principles behind our forecasts .
In the figure 6 In this example , Our prediction model contains only three features : Volatility 、 P / E ratio (PE) And stock turnover . Without considering any features , We assume that the model will predict the average probability of distress of the training sample as 10%. then , If only volatility is considered 、 P / E ratio or stock turnover information , We will see the probability of a stock's distress rise to 15%、12% or 11%. Besides , We show that when two variables are included at the same time , When all three characteristics are considered , Predict changes in probability .
The average marginal contribution of each feature , or SHAP value , Calculate on the right . In this case , Stock volatility contributes the most , by 4.5%. This includes adding to the baseline 5% The average increase in , As the next line 9 When adding the second feature of 4.5% The average increase in , And as the bottom section 3 When adding variables 4% Increase of . Again , P / E ratio SHAP The value is 1.5%, The marginal contribution of turnover rate is the smallest ,SHAP The value is 1.0%. in general ,SHAP The values add up to 7%, Constitute the predicted value of the model 17% And the baseline value 10% Differences between . In this way , We can deconstruct the importance of each feature to each observation .

our ML The importance of features in the model is shown in the figure 7 Shown . The color of each point indicates the size of the feature , Red indicates high characteristic value , Blue indicates low characteristic value . These characteristics are ranked from top to bottom in importance . for example , features 25 Is the most important , This shows that it is SHAP There is the biggest difference in the value .
As the red dot shows , features 25 A high value of will lead to a substantial increase in the probability of financial distress , Because these points are more to the right than any other feature . On the other hand , Lower value , As highlighted by the blue dot , It means that the probability of financial difficulties is reduced , Because the blue dot is on the negative side of the scale . by comparison , features 4 The minimum value of is on the far left , So these values may be better than the characteristic 25 The minimum value of has a greater negative impact on the probability of distress . features 5 The effect of is nonlinear , Because high values have a great positive effect on probability , Low values have only a small negative effect .

In order to better understand the nonlinear and interaction effects between characteristics and the probability of financial distress , We looked at the figure 8 Partial dependency graph in . These graphs show the marginal effect of a single feature on the predicted probability of distress .
chart 8 The chart on the left side of the middle shows , Lower Distance-to-default Will increase the probability of distress . But the overall shape is convex to the origin Distance-to-default Reduced pair of SHAP The greater the marginal contribution . This is a clear example , Explain why nonlinear models are useful , Because the cross-sectional values of the whole range are unequal information .

up to now , We have shown the relationship between characteristics and the probability of financial distress ( It could be nonlinear ) Relationship , This helps us understand the behavior of input based prediction models . However , It is also possible to go deep into what seems to be a black box to explain individual disaster predictions . Deep mining of raw data enables us to clearly understand why a stock is or is not recognized as a low-priced stock .
For every observation , We can all show exactly which features increase the probability of distress , Which features reduce the probability of distress . chart 9 In, we describe the situation of a certain stock in our investment field .
For each relevant feature , We describe the input values and their impact on the estimated probability of distress . The red bar chart contains eigenvalues that increase the probability of distress , The blue bar chart contains eigenvalues that reduce the probability of distress . By using these visualizations , We can ensure that our ML The application is a glass box, not a black box , And we can drill down to the source data , To better understand the ruin probability of each stock in our stock pool .

4. be based on ML The future of stock selection
We have officially run several ML Model . for example , We use naturallanguageprocessing technology to interpret a large number of news , To test emotions , Or analyze the information disclosed by the company , To determine the possible contribution of the company to the United Nations sustainable development goals . This is a comparison of the method described in this paper to predict the risk of stock price collapse ML Technology supplement . We believe that these tools can help us better identify companies that may perform poorly in the future . Avoiding investing in such stocks may improve investment performance .
In our view , New quantitative research techniques —— Such as ML—— It challenges the traditional wisdom in the field of quantitative investment , And it is possible to improve the investment results . In this paper , We explained ML How to deal with difficult events in developed and emerging markets ( For example, bankruptcy filing or credit rating downgrade ) Help investors find troubled enterprises before they happen . We have evaluated ML The added value of the model , Because they can consider the complexity of nonlinearity and interaction , Especially compared with the simpler traditional linear model .
ML A key advantage of the algorithm is , We can provide them with economically reasonable and well performing input parameters , And analyze in detail whether their choice is logical over time . Because we are still aware of the risk of over fitting , We used a cross validation framework , We believe that , as time goes on , Prudent data-driven changes can be made in terms of predictability . Besides , We have the ability to scrutinize the source data , This enables us to explain why a stock in our portfolio has a specific probability of distress risk . In short , We are based on ml The application of distress risk prediction and Robeco The concept of quantitative investment is consistent .
There is a high possibility that future innovative research projects will reveal complex prediction relationships or lead to better interpretation of unstructured data . The downside of financial market data is , The stock price may be affected by many known and unknown factors , And over time , The relationship between enterprise characteristics is complex and unstable . This makes it difficult to predict stock returns .
therefore , Standard statistical methods may not be able to find complex patterns , Or the complex patterns in the data may be random , So it may not be repeated in the future . We are in the crisis prediction ML The application shows that ,ML The toolbox may contain methods to reveal the true signals of future financial crises , At the same time, the noise data in asset prices and company characteristics are ignored .
When moving from a rule-based model to a rule-based model ml The model of , The role of researchers has changed from a mentor to a coordinator . In the traditional way , The researchers instructed the computer to test certain rules of input data , See if they help predict output . stay ML aspect , The researchers input and output data into the computer , Let it evaluate what the best rules are . This is in ML In terminology, it is called supervised learning .
This change in role enables researchers to deal with more complex problems . But people need to be cautious , And pay attention to the interpretability and over fitting of the model . That's the only way , Quantitative researchers can sit in the driver's seat , layout ML The process , Instead of instructing the algorithm how to behave . therefore , We believe that ML Technology can drive quantitative modeling to a new level within the scope of our proven investment philosophy . in fact , Evidence based research 、 Economic rationality and prudent investment are ML Key factors that play a role in the investment environment .
边栏推荐
- 什么是SSL证书,拥有一个SSL证书有什么好处?
- Can the polardb database be connected to the data source through MySQL
- Pytorch learning notes (VII) ------------------ vision transformer
- Yarn: unable to load file c:\users\xxx\appdata\roaming\npm\yarn PS1 because running scripts is prohibited on this system
- How to click DOM to automatically locate the corresponding code line in vscode
- Call system function security scheme
- 网上开户股票安全吗?怎么开户呢?
- Mall project pc--- product details page
- 软件测试周刊(第77期):只要放弃一次,就会滋生放弃的习性, 原本可以解决的问题也会变得无法解决。
- SkyWalking 实现跨线程 Trace 传递
猜你喜欢

Easynvr fails to use onvif to detect the device. What is the reason why "no data" is displayed?

Introduction to database system

记一次beego通过go get命令后找不到bee.exe的坑

Array - fast and slow pointer in one breath

Copilot免费时代结束!学生党和热门开源项目维护者可白嫖
Rebeco:使用机器学习预测股票崩盘风险

MATLAB主窗口与编辑器窗口分开为两个界面的解决办法

Performance rendering of dSPACE

14 bs对象.节点名称.name attrs string 获取节点名称 属性 内容

MySQL learning notes -- addition, deletion, modification and query on a single table
随机推荐
Egg 服务搭建微信公众号的基础服务
EasyNVR使用Onvif探测设备失败,显示“无数据”是什么原因?
@PostConstruct
Is it safe to open an online stock account?
There is the word "Internet" in the concept of industrial Internet, but it is an existence that is not related to the Internet
2022年海外电商运营三大关键讲解
leecode学习笔记-机器人走到终点的最短路径
Once beego failed to find bee after passing the go get command Exe's pit
Is it safe to open an account by fraud
网上开户股票安全吗?怎么开户呢?
爱
做自媒体不知道怎样变现?7大变现方法分享
CMakeLists中的add_definitions()函数
指南针在上面开户安全吗?靠谱吗?
Use xxl-job to customize tasks and schedule them
Xiaomi routing R4A Gigabit version installation feed+openwrt tutorial (the full script does not need to be hard modified)
VSCode中如何实现点击DOM自动定位到相应代码行
Tutoriel d'installation MySQL
vie的刷新机制
How does the administrator prohibit another person from kicking himself?