当前位置:网站首页>Oracle concept II
Oracle concept II
2022-06-27 16:35:00 【_ Bar _ Illusion dans le vent】

Il y a deux types de personnes dans le monde
Les gens qui ont le courage de prendre les choses en main et de trouver des gens sur la colline
C'est mieux en montagne.
----《Scent of a Woman》
Table des matières
1、rank()/dense_rank() over(partition by ...order by ...)
2、min()/max() over(partition by ...)
3、lead()/lag() over(partition by ... order by ...)
lead() C'est après avoir pris NLes données de la ligne
lag() C'est avant de prendre NLes données de la ligne
Un..pivotFonctions
Ligne à colonne.
J'ai rencontré une affaire au travail , Une colonne de données est requise ( Cette colonne est généralement de différents types ,Comme le comté., Sujets, etc. ) Afficher plusieurs colonnes , Ou ligne à colonne .
Références:Blogs
Notes des élèves,Données brutes:
select class_name, student_name, course_type, result, created_date
from class_tmp_2;
Deux notes par élève , Deux données. ,Parce que les affaires ont besoin de, Quand il est montré à l'utilisateur , L'utilisateur veut juste une donnée par étudiant , Et montrer tous les résultats ,Par exemple,

La fonction LIGNE - colonne est nécessaire à ce moment PIVOT.
SELECT class_name, student_name, Langues, Mathématiques, created_date
FROM (SELECT CLASS_NAME, STUDENT_NAME, COURSE_TYPE, RESULT, CREATED_DATE
FROM CLASS_TMP_2) T
PIVOT(SUM(RESULT)
FOR COURSE_TYPE IN('Langues' AS Langues, 'Mathématiques' AS Mathématiques));Gris clair sql Et les données originales ci - dessus sqlC'est pareil, Regarde derrière. PIVOTSection.
sum(result):Somme des résultats(PIVOT Fonction d'agrégation interne requise )
for course_type in ('Langues' asLangues, 'Mathématiques' asMathématiques):Oui.course_typeColonne Valeur du champ convertie en nom de colonne ,Parmi eux,La valeur du champ est'Langues', Conversion en colonnes linguistiques ,La valeur du champ est'Mathématiques', Convertir en colonne mathématique , Valeurs des champs pour ces deux colonnes ,C'est - à - dire devantsum(result).
Cet exemple est dû à la même classe , Ainsi, vous pouvez également utiliser la requête suivante pour implémenter
select t1.class_name,
t1.student_name,
t1.result Langues,
t2.result Mathématiques,
t1.created_date
from (select a.class_name,
a.student_name,
a.course_type,
a.result,
a.created_date
from class_tmp_2 a
where a.course_type = 'Langues') t1,
(select a.class_name,
a.student_name,
a.course_type,
a.result,
a.created_date
from class_tmp_2 a
where a.course_type = 'Mathématiques') t2
where t1.class_name = t2.class_name
and t1.student_name = t2.student_name;2..unpivotFonctions
Colonne en ligne.
Les données originales sont les suivantes:

Les résultats escomptés sont les suivants

C'est - à - dire, Si vous rencontrez plus d'une colonne que vous voulez trouver dans la base de données, placez toutes les colonnes dans la même colonne pour afficher plus d'une ligne. , Leurs données correspondantes sont placées dans une autre catégorie ,C'est juste en dessousresult,Utilisez cette fonction.
select class_name, student_name, course_type, result, created_date
from class_tmp
unpivot(result for course_type in(chinese_result,math_result));Description:
Données bruteschinese_resultColonnes etmath_resultNom de la colonne(Gris clair), Convertir en Nouvelle Colonne course_typeValeur du champ pour, Indique le type de cours .
Données bruteschinese_resultColonnes etmath_result Valeur du champ pour la colonne , Convertir en Nouvelle Colonne resultValeur du champ pour,Indique le score.
Trois.with as
with asPhrases,Aussi connu sous le nom de sous - Requête,Est de définirsqlFragment, Ce fragment est très grand. sql Il est souvent utilisé dans les déclarations , Son utilisation est alors limitée à ---Utilisation multiple, Un scénario commercial avec peu de données ,AjoutersqlLisibilité, Réduire les temps de balayage (Ça marche.F5 Vous pouvez voir si c'est une table de base ou une table temporaire en mémoire. ), Réduire la réécriture du Code ;with as Est l'équivalent d'une table temporaire en mémoire , C'est pour ça qu'il est rapide. , Il va bien. , Donc la quantité de données ne peut pas être énorme ;
Syntaxe:
Principales méthodes d'écriture :
with query1 AS
(select ...from ....where ..),
query2 AS
(select...from ...where..),
query3 AS
(select...from ...where..)
SELECT ...FROM query1,quer2,query3
where ....;Par exemple,:
with
e as
(select * from scott.emp),
d as
(select * from scott.dept)
select * from e, d where e.deptno = d.deptno;Comme plusieurs. union all:
with
sql1 as
(select to_char(a) s_name from test_tempa),
sql2 as
(select to_char(b) s_name
from test_tempb
where not exists (select s_name from sql1 where rownum = 1))
select * from sql1
union all
select * from sql2
union all .. .. ..Quatre.leadingFonctions
/*+LEADING(TABLE)*/ /*+LEADING(table1,table2....)*/
Utiliser la table spécifiée comme première table dans l'ordre des liens ,leading L'invite peut être suivie de plusieurs noms de table , Il est utilisé pour représenter dans les associations de tableaux connexes , Quelle table est utilisée comme table d'entraînement .UtiliserleadingAprès le rappel, L'optimiseur n'envisagera plus from Ordre des tableaux suivants .
En termes simples, il s'agit de définir ce qui est la table d'entraînement , En général, c'est une petite montre. ;Parfoisoracle L'optimiseur désignera la grande table comme la table d'entraînement , Cela augmente le nombre de scans ;
Comme une affaire récente ,En raison des exigences de confidentialité, Une déclaration similaire est la suivante:
select a...
from A a
left join B b
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.idid- Oui.ABCD Clé primaire pour quatre tables , Donc ça veut dire qu'il y a des index , Alors regardez le plan de scan et découvrez AAvecB Toutes les tables sont scannées. ,BTableaucostÇa prend beaucoup de temps, Durée totale 45 Dans quelques secondes. ,ALes données du tableau sont100Article (s),BOui.30Dix mille;
Contre ce phénomène , La première direction d'optimisation est de faire B Table walk Forcing Index ,Donc l'optimisation est la suivante:
select /*+index(B)*/ a...
from A a
left join B
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.idVoir les résultats du plan d'exécution B La table est indexée. , Donc la vitesse est arrivée d'un coup 0.2Secondes.
Continuez avec l'exemple ci - dessus , En fait, l'optimisation finale qui a suivi était comme ça :
select /*+leading(A B) index(B)*/ a...
from A a
left join B
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.idAttention!:Si⼀ Tables indexées ,⼀ Les tableaux n'ont pas d'index ,ORACLE Les tables non indexées seront utilisées comme tables motrices . Si les deux tableaux ont un index , L'extérieur sert de tableau d'entraînement. . Si aucun des deux n'est indexé , C'est aussi l'apparence qui fait la montre d'entraînement .Pensez à l'utiliser à ce moment - là.leading La fonction est spécifiée selon le plan de numérisation .
Cinq.connect byRécursion
Syntaxe de base
select t.*,level from table t [start with condition1]
connect by [prior] id=parentidCette fonction est généralement utilisée pour trouver des données qui ont une relation parent - enfant , Tableau hiérarchique ;
start with condition1 Est utilisé pour limiter les données de la première couche , Ou les données du noeud racine ; Utilisez ces données pour trouver des données de niveau 2 , Ensuite, trouvez les données de niveau 3 avec les données de niveau 2 et ainsi de suite. .
Etconnect by prior id=parentidOuconnect by id=prior parentidQuelle différence?
Prenons un exemple.:
Créer des données , Prenons l'exemple d'un arbre à moitié droit. :
-- Create table
create table BANK
(
id NUMBER(8) not null,
funcid NUMBER(8),
parentid NUMBER(8),
funcname VARCHAR2(20),
parentname VARCHAR2(20)
);
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1001, 0, ' Président Nakano Watanabe ', null);
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1002, 1001, ' Sanli vice President ', ' Président Nakano Watanabe ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1003, 1002, ' OHADA Executive ', ' Sanli vice President ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1005, 1003, ' Ministre Izzo Yama ', ' OHADA Executive ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1006, 1005, 'Genévrier', ' Ministre Izzo Yama ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1007, 1003, ' Watanabe! ', ' OHADA Executive ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1004, 1002, ' Gibbon Executive ', ' Sanli vice President ');
commit;Requête comme indiqué dans la figure ,La hiérarchie est:Le Président-Vice President-Permanent-Minister-Travailleurs

C'est souvent utilisé au travail , Par exemple, certains tableaux contiennent des données sur les relations organisationnelles. , Il y en a dans le menu de gauche , C'est souvent le cas pour les tableaux organisationnels utilisés dans des entreprises complexes. .
Pour la syntaxe ci - dessus , Il y a un mot clé dedans. prior, Ceci peut être à gauche et à droite du signe égal ,level Oui ou non. , Utilisé uniquement pour indiquer à quel niveau les données de la ligne appartiennent .
select t.*,level from tablename t
start with Conditions1
connect by prior Sous - Champsid= Champ parent id
where Conditions3;Si à gauche , Vérifier les noeuds de feuilles basés sur la condition 1 ;
Si à droite, Le noeud supérieur basé sur la condition 1 est vérifié. .
À gauche.
De1001C'est parti.,Interroger ses noeuds enfants;
select t.*,level from bank t
start with t.funcid=1001
connect by prior t.funcid=t.parentid
order by funcid;
A droite
Regarde.1001 Parent de départ , Donc il n'y a qu'une seule donnée ;
select t.*, level
from bank t
start with t.funcid = 1001
connect by t.funcid = prior t.parentid
order by funcid;
Six.keepFonctions
keep- Oui.oracle Fonction d'analyse suivante ,Oracle Pour résoudre le problème de la valeur maximale de la requête dans le Sous - ensemble ,J'ai proposéKEEP()Syntaxe,C'est - à - dire Après avoir trié un champ sous le même groupe , Obtient la valeur la plus basse ou la plus grande pour le champ spécifié .
La syntaxe est la suivante::
min | max(column1) keep (dense_rank first | last order by column2) over (partion by column3);
Voici quelques exemples:Construire une montre, Avec le Haut with as Créer un tableau provisoire comme suit: :
WITH workers AS(
SELECT 'DOM1' dept, 'zhangsan' names , 23 age, 4000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'lisi' names , 35 age, 9000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'wangwu' names , 26 age, 6500 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'maliu' names , 28 age, 6000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'zhaoqi' names , 26 age, 5000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'liba' names , 23 age, 3000 salaries FROM dual
)
select * from workers;Les requêtes sont les suivantes:

Objectifs opérationnels: Parmi les plus jeunes du secteur de l'accès , Record des salaires les plus élevés ;
Alors on peut utiliserkeep(dense_rank first/last)Pour s'en occuper., Remplacer le dessus sf..works,Par exemple,
SELECT w.dept,
max(w.salaries) KEEP(dense_rank first order by w.age) max_salary
FROM workers w
GROUP BY dept;
Ça veut dire... Rechercher le salaire maximum par âge , Parce que c'est l'âge le plus jeune ,C'est pour ça quefirst, Si l'âge est le plus élevé, ,Aveclast;
Explication
1.keepÇa veut dire:“Tiens bon.”, Les dossiers qui remplissent les conditions entre parenthèses seront conservés ,Avecorder by Il y en aura naturellement plus tard. firstEtlastC'est,C'est une écriture fixe.;
2.dense_rank Est la stratégie de tri , Généralement par défaut ;
3.first/last Est de filtrer les données , Ici, on passe au crible. ageEnregistrement minimal;
4. En raison de l'utilisation de la fonction d'agrégation , Donc, à la fin, group by;
Sept.overFonctions
Syntaxe:rank()/dense_rank over(partition by A order by B)
over Est une fonction analytique ,Selon le champA Partitionner les résultats , Trier par champs dans chaque partition ;
overNe peut pas être utilisé seul,Les besoins sont liés àrow_number(),rank()Etdense_rank,lag()Etlead(),sum()Utilisation équivalente
Description:
- over() Sur quelles conditions? ;
- partition by Groupe par quel champ ;
- order by Trier par quel champ;
Attention!:
- Utiliserrank()/dense_rank() Heure,Il faut l'apporter.order bySinon, c'est illégal.;
- rank(): Tri des sauts , S'il y a deux niveaux , Ensuite, le troisième niveau. .
- dense_rank(): Séquençage continu, S'il y a deux niveaux , Ensuite, il y a encore le niveau 2 .
Par exemple,:
Créer un tableau et insérer des données :
create table EMP
(
empno NUMBER(4) not null,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
)
alter table EMP
add constraint PK_EMP primary key (EMPNO);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, to_date('20-02-1981', 'dd-mm-yyyy'), 1600, 300, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, to_date('22-02-1981', 'dd-mm-yyyy'), 1250, 500, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, to_date('02-04-1981', 'dd-mm-yyyy'), 2975, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, to_date('28-09-1981', 'dd-mm-yyyy'), 1250, 1400, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, to_date('17-11-1981', 'dd-mm-yyyy'), 5000, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698, to_date('08-09-1981', 'dd-mm-yyyy'), 1500, 0, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, to_date('03-12-1981', 'dd-mm-yyyy'), 950, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, to_date('03-12-1981', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, to_date('23-01-1982', 'dd-mm-yyyy'), 1300, null, 10); Requête comme indiqué dans la figure :
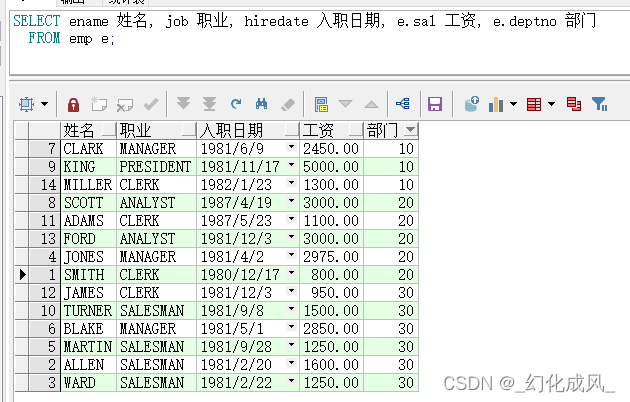
1、rank()/dense_rank() over(partition by ...order by ...)
Opérations I: Demander des renseignements sur les employés les mieux rémunérés de chaque ministère
L'écriture commune commune est :
select *
from (select ename Nom,
job Profession,
hiredate Date d'entrée en fonction,
e.sal Salaire,
e.deptno Secteur
from emp e,
(select deptno, max(sal) sal from emp group by deptno) t
where e.deptno = t.deptno
and e.sal = t.sal)
order by Secteur; 
UtiliseroverLa fonction est:
select empno, ename, job, hiredate, sal, deptno
from (select empno,
ename,
job,
hiredate,
sal,
deptno,
rank() over(partition by deptno order by sal desc) r
from emp)
where r = 1;
select empno, ename, job, hiredate, sal, deptno
from (select empno,
ename,
job,
hiredate,
sal,
deptno,
dense_rank() over(partition by deptno order by sal desc) r
from emp)
where r = 1 Les résultats de ces deux opérations sont conformes à ceux ci - dessus ,
Par secteur(deptno) Après le zonage selon le salaire (sal)Trier de haut en bas, Et un seul résultat par district est le salaire maximum ;
Autre: Si vous cherchez le salaire minimum ,descLire comme suit:ascC'est tout.;
2、min()/max() over(partition by ...)
Opérations II: Demander des renseignements sur l'employé et calculer le salaire maximal de l'employé et du Ministère / Différence de salaire minimum
Attention!:min/maxNon, non.order by
L'écriture commune est :
select ename Nom,
job Profession,
hiredate Date d'entrée en fonction,
e.deptno Secteur,
e.sal Salaire,
e.sal - me.min_sal Différence minimale ,
me.max_sal - e.sal Différence maximale
from emp e,
(select deptno, min(sal) min_sal, max(sal) max_sal
from emp
group by deptno) me
where e.deptno = me.deptno
order by e.deptno, e.sal;
UtiliseroverPour:
select ename Nom,
job Profession,
hiredate Date d'entrée en fonction,
deptno Secteur,
sal Salaire,
min(sal) over(partition by deptno) Salaire minimum sectoriel ,
max(sal) over(partition by deptno) Salaire maximal du Ministère ,
nvl(sal - min(sal) over(partition by deptno), 0) Différence de salaire minimum sectoriel ,
nvl(max(sal) over(partition by deptno) - sal, 0) Écart salarial maximal du Ministère
from emp
order by deptno, sal; 
RequêteÉcart Les résultats concordent avec ceux qui sont communs , Et moins de code que ci - dessus ;
Et si vous regardez les scans de Code des deux côtés ?Comme le montre la figure ci - dessous.:

Et il n'y a eu qu'un seul balayage complet en bas

Donc, en résumé, , Optimisé en fonction des besoins opérationnels .
D'autres questions. :
Pourquoi pas?order by salC'est?
order by Par défautascTrier de petit à grand, Écrivez comme suit:
select ename Nom,
job Profession,
hiredate Date d'entrée en fonction,
deptno Secteur,
sal Salaire,
min(sal) over(partition by deptno order by sal) Salaire minimum sectoriel ,
max(sal) over(partition by deptno order by sal) Salaire maximal du Ministère ,
nvl(sal - min(sal) over(partition by deptno order by sal), 0) Différence de salaire minimum sectoriel ,
nvl(max(sal) over(partition by deptno order by sal) - sal, 0) Écart salarial maximal du Ministère
from emp
order by deptno, sal; 
Le salaire personnel correspond au salaire maximal du Ministère. , Alors la différence est 0,La raison n'est pas claire, N'oubliez pas d'utiliser min/maxEn attendant la fonction d'agrégationover Les champs de l'agrégat ne peuvent pas être utilisés à l'intérieur order by, Ça veut dire qu'il n'y a pas besoin d'écrire. order byC'est.
3、lead()/lag() over(partition by ... order by ...)
Première explicationleadFonctions,Non, pas du tout.leading;
Ces deux fonctions, Est une fonction offset ;
Son but est:: Vous pouvez trouver la valeur suivante ou précédente pour chaque ligne d'enregistrement dans le même champ .
lead() C'est après avoir pris NLes données de la ligne
select ename Nom,
job Profession,
hiredate Date d'entrée en fonction,
deptno Secteur,
sal Salaire,
lead(sal) over(order by deptno) Offset1,
lead(sal,2) over(order by deptno) Offset2
from emp
order by deptno, sal;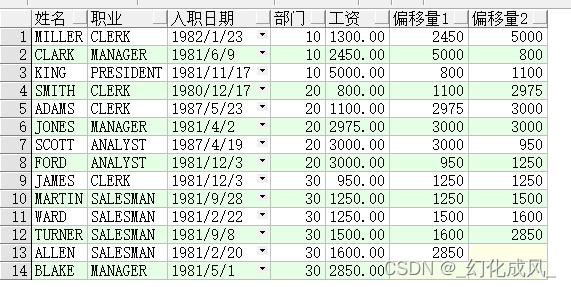
Comme le montre la figure,Par exemple, le décalage est1DeNo2La ligne commence à14D'accordVoilà.NLigne de données, C'est ce qu'on appelle la récupération. ND'accord;
- lead(column,num,flag)
- col_nameEst un nom de colonne;num Est la première valeur sous orientation ;flagC'est un signe, C'est - à - dire si la valeur suivante est nulle flag;
- Par exemplelead(column,1,null) C'est une valeur descendante , Si cette valeur est vide, appuyez sur NULL , Bien sûr, vous pouvez aussi remplacer par d'autres valeurs .
lag() C'est avant de prendre NLes données de la ligne
select ename Nom,
job Profession,
hiredate Date d'entrée en fonction,
deptno Secteur,
sal Salaire,
lag(sal) over(order by deptno) Offset1,
lag(sal,2,0) over(order by deptno) Offset2
from emp
order by deptno, sal;

Comme le montre la figure,Par exemple, le décalage est1DeNo13La ligne commence à1D'accordVoilà.NLigne de données, C'est ce qu'on appelle la pré - extraction. ND'accord;
C'est bon, Maintenant, Parlons affaires. :
Activité III: Calculer le salaire d'une personne dans le même ministère par rapport à un salaire supérieur à lui - même / Différence de salaire inférieure
select ename Nom,
job Profession,
sal Salaire,
deptno Secteur,
lead(sal, 1, 0) over(partition by deptno order by sal) Le salaire de la personne précédente est plus élevé que le sien ,
lag(sal, 1, 0) over(partition by deptno order by sal) Ce dernier a un salaire inférieur à son propre salaire ,
nvl(lead(sal) over(partition by deptno order by sal) - sal, 0) Une différence de salaire plus élevée que la sienne ,
nvl(sal - lag(sal) over(partition by deptno order by sal), 0) Différence inférieure à son propre salaire
from emp;
Fonction décrite ,Pas d'explication;
Ensuite, énumérez quelques façons courantes d'écrire la fonction d'agrégation de collocation
select ename Nom, job Profession, sal Salaire, deptno Secteur,
first_value(sal) over(partition by deptno) first_sal,
last_value(sal) over(partition by deptno) last_sal,
min(sal) over(partition by deptno) min_sal,
max(sal) over(partition by deptno) max_sal,
sum(sal) over(partition by deptno) Total des salaires sectoriels ,
avg(sal) over(partition by deptno) Salaire moyen sectoriel,
count(1) over(partition by deptno) Nombre total de départements,
row_number() over(partition by deptno order by sal) Numéro de série
from emp; 
Extrait deBlogs Et plus de détails
边栏推荐
- Domain name binding dynamic IP best practices
- 【Pygame小遊戲】這款“吃掉一切”遊戲簡直奇葩了?通通都吃掉嘛?(附源碼免費領)
- 特殊函数计算器
- # Cesium实现卫星在轨绕行
- [pyGame games] this "eat everything" game is really wonderful? Eat them all? (with source code for free)
- 等保三级密码复杂度是多少?多久更换一次?
- Introduce you to ldbc SNB, a powerful tool for database performance and scenario testing
- Bit. Store: long bear market, stable stacking products may become the main theme
- 事务的隔离级别详解
- Unity 阴影——阴影平坠(Shadow pancaking)
猜你喜欢

What is RPC

关于#mysql#的问题:问题遇到的现象和发生背景

Alibaba cloud liupeizi: Inspiration from cloud games - innovation on the end
阿里云刘珅孜:云游戏带来的启发——端上创新

LeetCode每日一练(无重复字符的最长子串)

Leetcode daily practice (main elements)

What should the ultimate LAN transmission experience be like

【多线程】线程通信调度、等待集 wait() 、notify()

Cesium realizes satellite orbit detour
P. Simple application of a.r.a method in Siyuan (friendly testing)

随机推荐
NFT dual currency pledge liquidity mining DAPP contract customization
面试半年,上个月成功拿到阿里P7offer,全靠我啃烂了这份2020最新面试题!
事务的隔离级别详解
Introduce you to ldbc SNB, a powerful tool for database performance and scenario testing
Qt5 signal and slot mechanism (demonstrate the correlation between the control's own signal and slot function)
Four characteristics of transactions
Julia constructs diagonal matrix
Oracle概念三
树莓派初步使用
Principle Comparison and analysis of mechanical hard disk and SSD solid state disk
Mode setting of pulseaudio (21)
锚文本大量丢失的问题
智慧风电 | 图扑软件数字孪生风机设备,3D 可视化智能运维
What should the ultimate LAN transmission experience be like
What is the level 3 password complexity of ISO? How often is it replaced?
【多线程】线程通信调度、等待集 wait() 、notify()
Solving Poisson equation by tensorflow
What is RPC
LeetCode每日一练(主要元素)
10 minutes to master the installation steps of MySQL