当前位置:网站首页>基于流的深度生成模型
基于流的深度生成模型
2022-06-28 01:39:00 【鬼道2022】
1 引言
到目前为止,两种生成模型 G A N \mathrm{GAN} GAN和 V A E \mathrm{VAE} VAE并不能准确地从真实数据 x ∈ D {\bf{x}}\in \mathcal{D} x∈D中学习出概率分布 p ( x ) p({\bf{x}}) p(x)。以隐变量的生成模型为例,在计算积分 p ( x ) = ∫ p ( x ∣ z ) d z p({\bf{x}})=\int p({\bf{x}}|{\bf{z}})d{\bf{z}} p(x)=∫p(x∣z)dz时,需要遍历所有的隐变量 z {\bf{z}} z的取值这是非常困难,且不切实际的。基于 F l o w \mathrm{Flow} Flow的生成模型在正则化流(正则化流是估计概率分布非常有力的工具)帮助下可以更好的解决这个问题。一个的概率分布 p ( x ) p({\bf{x}}) p(x)好的估计可以完成很多任务,比如说数据生成,预测未来事件概率估计,数据样本增强等。
2 生成模型的种类
当前生成模型的种类可以主要分为三种,分别是基于 G A N \mathrm{GAN} GAN的生成模型,基于 V A E \mathrm{VAE} VAE的生成模型和基于 F l o w \mathrm{Flow} Flow的生成模型:
- 生成对抗网络(GAN): GAN是由两个神经网络组成,分别是生成器和判别器。生成器的目的是从噪声 z {\bf{z}} z中学习生成真实的数据样本 x ′ {\bf{x}}^{\prime} x′,而判别器的目的是区分出真实的样本 x {\bf{x}} x和生成的样本 x ′ {\bf{x}}^{\prime} x′。在训练的过程中,两个网络在玩一个 min - max \min\text{-}\max min-max的博弈游戏中相互促进相互提高。
- 变分自动编码器(VAE): GAN是也是由两个神经网络组成,分别是编码器和解码器。编码器是将数据样本 x {\bf{x}} x编码成隐向量 z {\bf{z}} z,解码器将隐向量 z {\bf{z}} z映射回样本数据 x ′ { {\bf{x}}^{\prime}} x′。VAE是在最大化变分下界中,粗略地优化数据的对数似然估计。
- 基于 F l o w {\mathrm{Flow}} Flow的生成模型: 一个基于 F l o w {\mathrm{Flow}} Flow的生成模型是由一系列的可逆变换器组成。它可以使得模型能够更加精确的学习到数据分布 p ( x ) p({\bf{x}}) p(x),它的损失函数是一个负对数似然函数。

3 预备知识
在了解基于 F l o w \mathrm{Flow} Flow的生成模型之前,需要知道三个关键的数学概念,分别是雅可比矩阵,行列式和变量替换定理。
3.1 雅可比矩阵和行列式
给定一个映射函数 f : R n → R m f:\mathbb{R}^n \rightarrow \mathbb{R}^m f:Rn→Rm,将 n n n维输入向量 x {\bf{x}} x映射为 m m m维的输出向量。雅可比矩阵是函数 f f f关于输入向量 x {\bf{x}} x所有分量的一阶偏导数
J = [ ∂ f 1 ∂ x 1 ⋯ ∂ f 1 ∂ x n ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ⋯ ∂ f m ∂ x n ] {\bf{J}}=\left[\begin{array}{ccc}\frac{\partial f_1}{\partial x_1}& \cdots & \frac{\partial f_1}{\partial x_n}\\\vdots & \ddots & \vdots\\ \frac{\partial f_m}{\partial x_1} & \cdots &\frac{\partial f_m}{\partial x_n}\end{array}\right] J=⎣⎢⎡∂x1∂f1⋮∂x1∂fm⋯⋱⋯∂xn∂f1⋮∂xn∂fm⎦⎥⎤而行列式是用于计算一个方阵的,结果为一个实值标量。行列式的绝对值可以被认为是“矩阵的乘法扩展或收缩了多少空间”的度量。一个 n × n n\times n n×n方阵 M M M的行列式如下所示 d e t ( M ) = d e t ( [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] ) = ∑ j 1 j 2 ⋯ j n ( − 1 ) τ ( j 1 j 2 ⋯ j n ) a 1 j 1 a 2 j 2 ⋯ a n j n \mathrm{det}(M)=\mathrm{det}\left(\left[\begin{array}{cccc}a_{11}&a_{12}&\cdots&a_{1n}\\a_{21}&a_{22}&\cdots&a_{2n}\\\vdots& \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn}\end{array}\right]\right)=\sum\limits_{j_1j_2\cdots j_n}(-1)^{\tau(j_1j_2\cdots j_n)}a_{1j_1}a_{2j_2}\cdots a_{nj_n} det(M)=det⎝⎜⎜⎜⎛⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤⎠⎟⎟⎟⎞=j1j2⋯jn∑(−1)τ(j1j2⋯jn)a1j1a2j2⋯anjn其中求和下的下标 j 1 j 2 ⋯ j n j_1j_2\cdots j_n j1j2⋯jn是集合 { 1 , ⋯ , n } \{1,\cdots,n\} { 1,⋯,n}的所有置换,共有 n ! n! n!项。 τ \tau τ表示的是置换的符号。方阵 M M M行列式取值为 0 0 0时,则不可逆,反之亦然。行列式乘积公式为 d e t ( A B ) = d e t ( A ) ⋅ d e t ( B ) \mathrm{det}(AB)=\mathrm{det}(A)\cdot \mathrm{det}(B) det(AB)=det(A)⋅det(B)
3.2 变量替换定理
给定一个单变量随机变量 z z z,已知它的概率分布为 z ∼ π ( z ) z\sim \pi(z) z∼π(z),如果想要用一个映射函数 f f f构造一个新的随机变量 x x x,即 x = f ( z ) x=f(z) x=f(z),其中 f f f是可逆的,即 z = f − 1 ( x ) z=f^{-1}(x) z=f−1(x),则新随机变量的概率分布推导如下所示 ∫ p ( x ) d x = ∫ π ( z ) d z = 1 \int p(x)dx =\int \pi (z)dz=1 ∫p(x)dx=∫π(z)dz=1 p ( x ) = π ( z ) d z d x = π ( f − 1 ( x ) ) d f − 1 d x = π ( f − 1 ( x ) ) ∣ ( f − 1 ) ′ ( x ) ∣ p(x)=\pi(z)\frac{dz}{dx}=\pi(f^{-1}(x))\frac{d f^{-1}}{dx}=\pi(f^{-1}(x))|(f^{-1})^{\prime}(x)| p(x)=π(z)dxdz=π(f−1(x))dxdf−1=π(f−1(x))∣(f−1)′(x)∣根据定义可知,积分 ∫ π ( z ) d z \int \pi(z)dz ∫π(z)dz是无穷多个宽度 Δ z \Delta z Δz无穷小的矩形之和。该位置 z z z处矩形的高度是密度函数 π ( z ) \pi(z) π(z)的值。当进行变量替换时,由 z = f − 1 ( x ) z=f^{-1}(x) z=f−1(x)得到 Δ z Δ x = ( f − 1 ( x ) ) ′ \frac{\Delta z}{\Delta x}=(f^{-1}(x))^{\prime} ΔxΔz=(f−1(x))′和 Δ z = ( f − 1 ( x ) ) ′ \Delta z =(f^{-1}(x))^{\prime} Δz=(f−1(x))′。 ∣ f − 1 ( x ) ∣ ′ |f^{-1}(x)|^{\prime} ∣f−1(x)∣′表示在两个不同的变量坐标中定义矩形面积之间的比例。多变量的版本如下所示:
z ∼ π ( z ) , x = f ( z ) , z = f − 1 ( x ) {\bf{z}}\sim \pi({\bf{z}}), \text{ }{\bf{x}}=f({\bf{z}}),\text{ }{\bf{z}}=f^{-1}({\bf{x}}) z∼π(z), x=f(z), z=f−1(x) p ( x ) = π ( z ) ⋅ d e t ( d z d x ) = π ( f − 1 ( x ) ) ⋅ d e t ( d f − 1 d x ) p({\bf{x}})=\pi({\bf{z}})\cdot \mathrm{det} \left(\frac{d{\bf{z}}}{d{\bf{x}}}\right)=\pi(f^{-1}({\bf{x}}))\cdot\mathrm{det}\left(\frac{d f^{-1}}{d{\bf{x}}}\right) p(x)=π(z)⋅det(dxdz)=π(f−1(x))⋅det(dxdf−1)其中 d e t ( ∂ f ∂ z ) \mathrm{det}\left(\frac{\partial f}{\partial {\bf{z}}}\right) det(∂z∂f)为雅可比矩阵的行列式。
4 标准化流
对概率分布进行良好的密度估计在许多机器学习问题中有直接的应用,但这是非常困难的。例如,由于我们需要在深度学习模型中运行反向传播,因此嵌入变量的概率分布(即后验 p ( z ∣ x ) p(\mathbf{z}\vert\mathbf{x}) p(z∣x))预计足够简单,可以轻松有效地计算导数。这就是为什么在隐变量生成模型中经常使用高斯分布的原因,尽管大多数真实世界的分布比高斯分布复杂得多。标准化流模型则可以用于更好、更强大的分布近似。标准化流通过应用一系列可逆变换函数将简单分布转换为复杂分布。通过一系列变换,根据变量替换定理反复替换新变量,最终得到最终目标变量的概率分布。
如上图的图示,对应则有以下公式
z i − 1 ∼ p i − 1 ( z i − 1 ) z i = f i ( z i − 1 ) , z i − 1 = f i − 1 ( z i ) p i ( z i ) = p i ( f i − 1 ( z i ) ) ⋅ d e t d f i − 1 d z i \begin{aligned}{\bf{z}}_{i-1}&\sim p_{i-1}({\bf{z}}_{i-1})\\{\bf{z}}_i&=f_i({\bf{z}}_{i-1}), \text{ }{\bf{z}}_{i-1}=f_i^{-1}({\bf{z}}_i)\\ p_i({\bf{z}}_i)&=p_{i}(f^{-1}_i({\bf{z}}_i))\cdot \mathrm{det}\frac{d f_i^{-1}}{d {\bf{z}}_i}\end{aligned} zi−1zipi(zi)∼pi−1(zi−1)=fi(zi−1), zi−1=fi−1(zi)=pi(fi−1(zi))⋅detdzidfi−1根据以上公式可以推知概率分布 p i ( z i ) p_i({\bf{z}}_i) pi(zi)表示为 p i ( z i ) = p i − 1 ( f i − 1 ( z i ) ) ⋅ d e t ( d f i − 1 d z i ) = p i − 1 ( z i − 1 ) ⋅ d e t ( d f i d z i − 1 ) − 1 = p i − 1 ( z i − 1 ) ⋅ [ d e t ( d f i d z i − 1 ) ] − 1 log p i ( z i ) = log p i − 1 ( z i − 1 ) − log d e t ( d f i d z i − 1 ) \begin{aligned}p_i({\bf{z}}_i)&=p_{i-1}(f_i^{-1}({\bf{z}}_i))\cdot \mathrm{det}\left(\frac{d f^{-1}_i}{d {\bf{z}}_i}\right)\\&=p_{i-1}({\bf{z}}_{i-1})\cdot \mathrm{det}\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)^{-1}\\&=p_{i-1}({\bf{z}}_{i-1})\cdot \left[\mathrm{det}\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)\right]^{-1}\\\log p_i({\bf{z}}_i)&=\log p_{i-1}({\bf{z}}_{i-1})-\log \mathrm{det}\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)\end{aligned} pi(zi)logpi(zi)=pi−1(fi−1(zi))⋅det(dzidfi−1)=pi−1(zi−1)⋅det(dzi−1dfi)−1=pi−1(zi−1)⋅[det(dzi−1dfi)]−1=logpi−1(zi−1)−logdet(dzi−1dfi)以上公式推导中用到了反函数定理,即如果 y = f ( x ) y=f(x) y=f(x)且 x = f − 1 ( y ) x=f^{-1}(y) x=f−1(y),进而则有
d f − 1 ( y ) d y = d x d y = ( d y d x ) − 1 = ( d f ( x ) d x ) − 1 \frac{d f^{-1}(y)}{dy}=\frac{dx}{dy}=\left(\frac{dy}{dx}\right)^{-1}=\left(\frac{d f(x)}{dx}\right)^{-1} dydf−1(y)=dydx=(dxdy)−1=(dxdf(x))−1雅可比矩阵的反函数定理为:一个可逆矩阵逆的行列式为这个矩阵行列式的倒数,即 d e t ( M − 1 ) = ( d e t ( M ) ) − 1 \mathrm{det}({M}^{-1})=(\mathrm{det}(M))^{-1} det(M−1)=(det(M))−1,因为 d e t ( M ) ⋅ d e t ( M − 1 ) = d e t ( M ⋅ M − 1 ) = d e t ( I ) = 1 \mathrm{det}({M})\cdot\mathrm{det}(M^{-1})=\mathrm{det}(M\cdot M^{-1})=\mathrm{det}(I)=1 det(M)⋅det(M−1)=det(M⋅M−1)=det(I)=1。给定这样一系列概率密度函数,我们知道每对连续变量之间的关系。所以可以通过输出 x {\bf{x}} x直到追溯到初始分布 z 0 {\bf{z}}_0 z0。 x = z k = f K ∘ f K − 1 ∘ ⋯ f 1 ( z 0 ) log p ( x ) = log π K ( z K ) = log π K − 1 ( z K − 1 ) − log d e t ( d f K d z K − 1 ) = log π K − 2 ( z K − 2 ) − log d e t ( d f K − 1 d z K − 2 ) − log d e t ( d f K d z K − 1 ) = ⋯ = log π 0 ( z 0 ) − ∑ i = 1 K log det ( d f i d z i − 1 ) \begin{aligned}{\bf{x}}={\bf{z}}_k&=f_K \circ f_{K-1}\circ \cdots f_1({\bf{z}}_0)\\\log p({\bf{x}})=\log\pi_K ({\bf{z}}_K)&= \log \pi_{K-1}({\bf{z}}_{K-1})-\log \mathrm{det}\left(\frac{d f_K}{d {\bf{z}}_{K-1}}\right)\\&=\log \pi_{K-2}({\bf{z}}_{K-2})-\log \mathrm{det}\left(\frac{d f_{K-1}}{d {\bf{z}}_{K-2}}\right)-\log \mathrm{det}\left(\frac{d f_K}{d {\bf{z}}_{K-1}}\right)\\&=\cdots\\&=\log \pi_0({\bf{z}}_0)-\sum\limits_{i=1}^K \log \det\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)\end{aligned} x=zklogp(x)=logπK(zK)=fK∘fK−1∘⋯f1(z0)=logπK−1(zK−1)−logdet(dzK−1dfK)=logπK−2(zK−2)−logdet(dzK−2dfK−1)−logdet(dzK−1dfK)=⋯=logπ0(z0)−i=1∑Klogdet(dzi−1dfi)随机变量 z i = f i ( z i − 1 ) {\bf{z}}_i=f_i({\bf{z}}_{i-1}) zi=fi(zi−1)穿过的路径就是一条流,连续分布 π i \pi_i πi形成的全链被称为标准化流。根据方程的计算要求,变换函数应该满足两个特性,分别是函数可逆和雅可比矩阵行列式计算容易。
5 标准化流
通过标准化流求输入数据的精确对数似然变得更加容易,基于流的生成模型的训练损失函数为训练数据集上的负对数似然 L ( D ) = − 1 ∣ D ∣ ∑ x ∈ D log p ( x ) \mathcal{L}(\mathcal{D})=-\frac{1}{|\mathcal{D}|}\sum\limits_{ {\bf{x}}\in \mathcal{D}}\log p({\bf{x}}) L(D)=−∣D∣1x∈D∑logp(x)
5.1 RealNVP
RealNVP模型通过叠加可逆双射变换函数序列来实现标准化流。在每个双射 f : x → y f:{\bf{x}}\rightarrow {y} f:x→y中,输入维度分为两部分:
- d d d维度保持不变;
- 第 d + 1 d+1 d+1维度到 D D D维度,进行仿射变换(“缩放和平移”),缩放和平移参数都是第一维度的函数。 y 1 : d = x 1 : d y d + 1 : D = x d + 1 : D ⊙ exp ( s ( x 1 : d ) ) + t ( x 1 : d ) \begin{aligned}{\bf{y}}_{1:d}&={\bf{x}}_{1:d}\\{\bf{y}}_{d+1:D}&={\bf{x}}_{d+1:D} \odot \exp (s({\bf{x}}_{1:d}))+t({\bf{x}}_{1:d})\end{aligned} y1:dyd+1:D=x1:d=xd+1:D⊙exp(s(x1:d))+t(x1:d)其中 s ( ⋅ ) s(\cdot) s(⋅)和 t ( ⋅ ) t(\cdot) t(⋅)是缩放和平移函数,映射都为 R d → R D − d \mathbb{R}^d \rightarrow \mathbb{R}^{D-d} Rd→RD−d, ⊙ \odot ⊙操作符表示的按元素乘积。
对于标准化流的条件1为函数可逆在RealNVP模型中是非常容易实现的,具体函数如下所示 { y 1 : d = x 1 : d y d + 1 : D = x d + 1 : D ⊙ exp ( s ( x 1 : d ) ) + t ( x 1 : d ) * { x 1 : d = y 1 : d x d + 1 : D = ( y d + 1 : D − t ( y 1 : d ) ) ⊙ exp ( − s ( y 1 : d ) ) \left\{\begin{aligned}{\bf{y}}_{1:d}&={\bf{x}}_{1:d}\\{\bf{y}}_{d+1:D}&={\bf{x}}_{d+1:D}\odot \exp(s({\bf{x}}_{1:d}))+t({\bf{x}}_{1:d})\end{aligned}\right. \iff \left\{\begin{aligned}{\bf{x}}_{1:d}&={\bf{y}}_{1:d}\\{\bf{x}}_{d+1:D}&=({\bf{y}}_{d+1:D}-t({\bf{y}}_{1:d}))\odot \exp(-s({\bf{y}}_{1:d}))\end{aligned}\right. { y1:dyd+1:D=x1:d=xd+1:D⊙exp(s(x1:d))+t(x1:d)*{ x1:dxd+1:D=y1:d=(yd+1:D−t(y1:d))⊙exp(−s(y1:d))
对于标准化流条件2中雅可比行列式容易计算在RealNVP模型同样可以实现,其雅可比矩阵为下三角矩阵,具体矩阵如下所示 J = [ I d 0 d × ( D − d ) ∂ y d + 1 : D ∂ x 1 : d d i a g ( exp ( s ( x 1 : d ) ) ) ] {\bf{J}}=\left[\begin{array}{cc}\mathbb{I}_{d}&{\bf{0}}_{d\times(D-d)}\\\frac{\partial {\bf{y}}_{d+1:D}}{\partial {\bf{x}}_{1:d}}& \mathrm{diag}(\exp(s({\bf{x}}_{1:d})))\end{array}\right] J=[Id∂x1:d∂yd+1:D0d×(D−d)diag(exp(s(x1:d)))]因此,行列式只是对角线上的项的乘积。 d e t ( J ) = ∏ j = 1 D − d exp ( s ( x 1 : d ) ) j = exp ( ∑ j = 1 D − d s ( x 1 : d ) j ) \mathrm{det}({\bf{J}})=\prod_{j=1}^{D-d}\exp(s({ {\bf{x}}}_{1:d}))_j=\exp\left(\sum\limits_{j=1}^{D-d}s({\bf{x}}_{1:d})_j\right) det(J)=j=1∏D−dexp(s(x1:d))j=exp(j=1∑D−ds(x1:d)j)到目前为止,仿射耦合层看起来非常适合构建标准化流。更好的是,由于计算 f − 1 f^{-1} f−1不需要计算 s s s或 t t t的逆,并且计算雅比行列式不涉及计算 s s s或 t t t的雅可比矩阵,因此这些函数可以是任意复杂的,两者都可以用深层神经网络建模。在一个仿射耦合层中,某些维度(通道)保持不变。为了确保所有的输入都有机会被更改,模型颠倒了每一层中的顺序,以便不同的模块组件保持不变。按照这种交替模式,在一个转换层中保持相同的单元集总是在下一个转换层中修改。批量标准化有助于使用非常深的耦合层堆栈来训练模型。此外,RealNVP可以在多尺度体系结构中工作,为大型输入构建更高效的模型。多尺度体系结构将若干“采样”操作应用于普通仿射层,包括空间棋盘模式掩蔽、压缩操作和通道掩蔽。
NICE模型是RealNVP的前作,NICE中的变换是没有尺度项的仿射耦合层,称为加性耦合层 { y 1 : d = x 1 : d y d + 1 : D = x d + 1 : D + m ( x 1 : d ) * { x 1 : d = y 1 : d x d + 1 : D = y d + 1 : D − m ( y 1 : d ) \left\{\begin{aligned}{\bf{y}}_{1:d}&={\bf{x}}_{1:d}\\{\bf{y}}_{d+1:D}&={\bf{x}}_{d+1:D}+m({\bf{x}}_{1:d})\end{aligned}\right.\iff \left\{\begin{aligned}{\bf{x}}_{1:d}&={\bf{y}}_{1:d}\\{\bf{x}}_{d+1:D}&={\bf{y}}_{d+1:D}-m({\bf{y}}_{1:d})\end{aligned}\right. { y1:dyd+1:D=x1:d=xd+1:D+m(x1:d)*{ x1:dxd+1:D=y1:d=yd+1:D−m(y1:d)
5.2 Glow
G l o w \mathrm{Glow} Glow模型扩展了以前的可逆生成模型 N I C E \mathrm{NICE} NICE和 R e a l N V P \mathrm{RealNVP} RealNVP,并通过用可逆 1 × 1 1\times 1 1×1卷积替换通道排序上的反向置换操作来简化架构。 G l o w \mathrm{Glow} Glow中的一个流程中的一个步骤包含三个子步骤:
- 激活归一化: 它使用每个通道的比例和偏置参数执行仿射变换,类似于批量归一化,但适用于批量大小为 1 1 1。参数是可训练的,但已初始化,因此小批量数据在激活归一化之后具有均值为 0 0 0和标准差为 1 1 1。
- 可逆 1 × 1 1\times 1 1×1卷积: 在 R e a l N V P \mathrm{RealNVP} RealNVP流的各层之间,通道的顺序是相反的,因此所有数据维度都有机会被更改。具有相同数量的输入和输出通道的 1 × 1 1\times1 1×1卷积是任何通道排序排列的泛化。假设有一个输入张量维度为张量 h ∈ R h × w × c {\bf{h}}\in \mathbb{R}^{h\times w \times c} h∈Rh×w×c的可逆 1 × 1 1\times1 1×1卷积,其权重矩阵为 W ∈ R c × c {\bf{W}}\in\mathbb{R}^{c\times c} W∈Rc×c。 输出是一个 h × w × c h\times w \times c h×w×c的张量,记为 f = c o n v 2 d ( h ; W ) f=\mathrm{conv2d}({\bf{h}};{\bf{W}}) f=conv2d(h;W)。 为了应用变量替换定理,需要计算雅可比行列式 ∣ d e t ( ∂ f ∂ h ) ∣ \left|\mathrm{det}\left(\frac{\partial f }{\partial {\bf{h}}}\right)\right| ∣∣∣det(∂h∂f)∣∣∣。 h {\bf{h}} h中的每个元素 x i j ( i = 1 , ⋯ , h , j = 1 , ⋯ , 2 ) {\bf{x}}_{ij}(i=1,\cdots,h,j=1,\cdots,2) xij(i=1,⋯,h,j=1,⋯,2)是一个 c c c通道数的向量,每个元素乘以权重矩阵分别得到输出矩阵中对应的元素 y i j {\bf{y}}_{ij} yij。每个元素的导数为 ∂ x i j W ∂ x i j = W \frac{\partial {\bf{x}}_{ij}{\bf{W}}}{\partial {\bf{x}}_{ij}}={\bf{W}} ∂xij∂xijW=W,并且总计有共有 h × w h\times w h×w个元素:
log det ( ∂ c o n v 2 d ( h ; W ) ∂ h ) = log ( ∣ d e t ( W ) ∣ h ⋅ w ) = h ⋅ w ⋅ log ∣ det ( W ) ∣ \log \det\left(\frac{\partial \mathrm{conv2d({\bf{h}};{\bf{W}})}}{\partial {\bf{h}}}\right)=\log(|\mathrm{det}({\bf{W}})|^{h\cdot w})=h\cdot w \cdot \log |\det ({\bf{W}})| logdet(∂h∂conv2d(h;W))=log(∣det(W)∣h⋅w)=h⋅w⋅log∣det(W)∣可逆 1 × 1 1\times1 1×1卷积取决于逆矩阵 W {\bf{W}} W。 由于权重矩阵比较小,所以矩阵行列式和求逆的计算量还是在可控范围内的。 - 仿射耦合层: G l o w \mathrm{Glow} Glow的仿射耦合层的结构设计与 R e a l N V P \mathrm{RealNVP} RealNVP的仿射耦合层相同。
6 自回归流的模型
自回归约束是一种对序列数据 x = [ x 1 , ⋯ , x D ] {\bf{x}}=[x_1,\cdots,x_D] x=[x1,⋯,xD]建模的方法:每个输出只依赖于过去观察到的数据,而不依赖于未来的数据。换句话说,观察的概率 x i x_i xi是依赖于序列数据 x 1 , ⋯ , x i − 1 x_1,\cdots,x_{i-1} x1,⋯,xi−1,这些条件概率的乘积为提供了观察完整序列的概率: p ( x ) = ∏ i = 1 D p ( x i ∣ x 1 , ⋯ , x i − 1 ) = ∏ i = 1 D p ( x i ∣ x 1 : i − 1 ) p({\bf{x}})=\prod_{i=1}^D p(x_i|x_1,\cdots,x_{i-1})=\prod_{i=1}^D p(x_i|x_{1:i-1}) p(x)=i=1∏Dp(xi∣x1,⋯,xi−1)=i=1∏Dp(xi∣x1:i−1)
6.1 MADE
M A D E \mathrm{MADE} MADE是一种专门设计的架构,可以有效地在自编码器中执行自回归属性。当使用自动编码器来预测条件概率时, M A D E \mathrm{MADE} MADE不是向自动编码器提供不同观察窗口时间的输入,而是通过乘以二进制掩码矩阵来消除某些隐藏单元的贡献,以便每个输入维度仅从给定的先前维度重构进行一次性传播。给定一个有 L L L个隐层的全连接神经网络,其权重矩阵为 W 1 , ⋯ W L {\bf{W}}^1,\cdots{\bf{W}}^L W1,⋯WL,和一个输出层的权重矩阵 V {\bf{V}} V,输出的每个维度有 x ^ i = p ( x i ∣ x 1 : i − 1 ) \hat{x}_i=p(x_i|x_{1:i-1}) x^i=p(xi∣x1:i−1),当没有掩码矩阵的时候,神经网络前向传播的过程为如下所示: h 0 = x h l = a c t i v a t i o n l ( W l h l − 1 + b l ) x ^ = σ ( V h L + c ) \begin{aligned}{\bf{h}}^0&={\bf{x}}\\{\bf{h}}^l&=\mathrm{activation}^l({\bf{W}}^l {\bf{h}}^{l-1}+{\bf{b}}^l)\\\hat{ {\bf{x}}}&=\sigma({\bf{V}}{\bf{h}}^L+{\bf{c}})\end{aligned} h0hlx^=x=activationl(Wlhl−1+bl)=σ(VhL+c)为了将层之间的一些连接归零,可以简单地将每个权重矩阵按元素乘以一个二进制掩码矩阵。每个隐藏节点都分配有一个随机的“连接整数”,介于 1 1 1和 D − 1 D-1 D−1之间; 第 k k k层中第 l l l个单元的分配值表示为 m k l m^l_k mkl。通过逐元素比较两层中两个节点的值来确定二进制掩码矩阵,则有 h l = a c t i v a t i o n l ( ( W l ⊙ M W l ) h l − 1 + b l ) x ^ = σ ( ( V ⊙ M V ) h L + c ) M k ′ , k W l = 1 m k ′ l ≥ m k l − 1 = { 1 , i f m k ′ l ≥ m k l − 1 0 , o t h e r w i s e M d , k V = 1 d ≥ m k L = { 1 , i f d > m k L 0 , o t h e r w i s e \begin{aligned}{\bf{h}}^l&=\mathrm{activation}^l(({\bf{W}}^l \odot {\bf{M}}^{ {\bf{W}}^l}){\bf{h}}^{l-1}+{\bf{b}}^l)\\\hat{ {\bf{x}}}&=\sigma(({\bf{V}}\odot{\bf{M}}^{\bf{V}}){\bf{h}}^L+{\bf{c}})\\ M_{k^{\prime},k}^{ {\bf{W}}^l}&={\bf{1}}_{m^l_{k^{\prime}}\ge m^{l-1}_k}=\left\{\begin{array}{ll}1,& \mathrm{if}\text{ }m^l_{k^{\prime}}\ge m_k^{l-1}\\0,&\mathrm{otherwise}\end{array}\right.\\M_{d,k}^{ {\bf{V}}}&={\bf{1}}_{d\ge m^L_k}=\left\{\begin{array}{ll}1,&\mathrm{if}\text{ }d>m_k^L\\0,&\mathrm{otherwise}\end{array}\right.\end{aligned} hlx^Mk′,kWlMd,kV=activationl((Wl⊙MWl)hl−1+bl)=σ((V⊙MV)hL+c)=1mk′l≥mkl−1={ 1,0,if mk′l≥mkl−1otherwise=1d≥mkL={ 1,0,if d>mkLotherwise如下图的例子所示,当前层中的一个单元只能连接到前一层中具有相同或更小随机数的其它单元,并且这种类型的依赖关系很容易通过网络传播到输出层。一旦将随机数字分配给所有单元和层,输入维度的顺序就固定了,并且相对于它产生了条件概率。为了确保所有隐单元都通过一些路径连接到输入和输出层,采样 m k l m^l_k mkl等于或大于前一层中的最小连接整数 min k ′ m k ′ l − 1 \min_{k^{\prime}} m^{l-1}_{k^\prime} mink′mk′l−1
6.2 WaveNet
W a v e N e t \mathrm{WaveNet} WaveNet由一堆因果卷积组成,这是一种旨在尊重排序的卷积操作:在某个时间戳的预测只能消耗过去观察到的数据,不依赖于未来。 W a v e N e t \mathrm{WaveNet} WaveNet中的因果卷积只是将输出移动多个时间戳到未来,以便输出与最后一个输入元素对齐。卷积层的一大缺点是感受视野的大小非常有限。 输出几乎不能依赖于数百或数千个时间步之前的输入,这可能是对长序列建模的关键要求。 因此, W a v e N e t \mathrm{WaveNet} WaveNet采用扩张卷积,其中内核应用于输入的更大感受视野中均匀分布的样本子集。 W a v e N e t \mathrm{WaveNet} WaveNet使用门控激活单元作为非线性层,因为它被发现在建模一维音频数据方面比 R e L U \mathrm{ReLU} ReLU工作得更好,在门控激活之后应用残差连接,具体公式如下所示 z = t a n h ( W f , k ⊗ x ) ⊙ σ ( W g , k ⊗ x ) {\bf{z}}=\mathrm{tanh}({\bf{W}}_{f,k}\otimes {\bf{x}})\odot \sigma({\bf{W}}_{g,k}\otimes {\bf{x}}) z=tanh(Wf,k⊗x)⊙σ(Wg,k⊗x)其中 W f , k {\bf{W}}_{f,k} Wf,k和 W g , k {\bf{W}}_{g,k} Wg,k分别是第 k k k层的卷积滤波器和门权重矩阵,两者都是可学习的。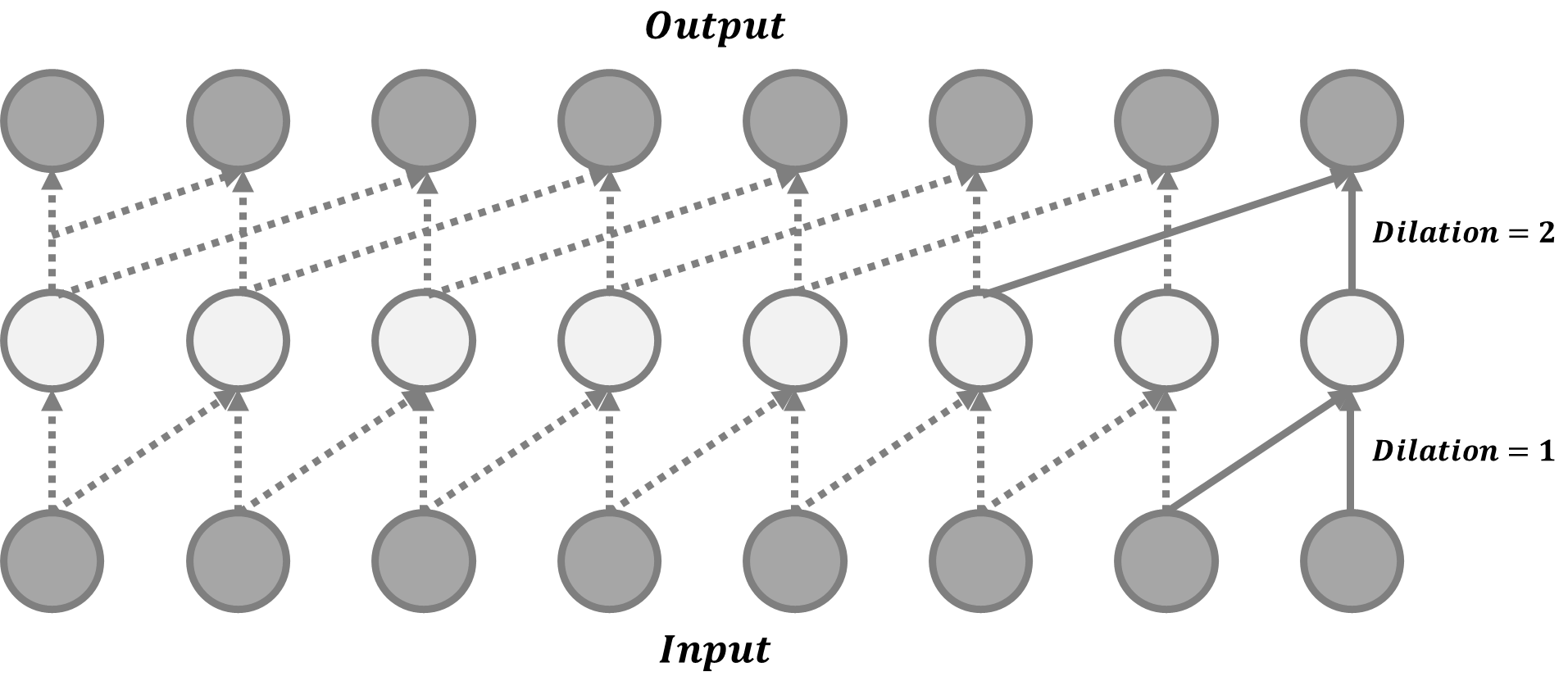
6.3 MAF
M A F \mathrm{MAF} MAF是一种标准化流,其中转换层构建为自回归神经网络。 M A F \mathrm{MAF} MAF与后面介绍的 I A F \mathrm{IAF} IAF 非常相似。给定两个随机变量 z ∼ π ( z ) {\bf{z}}\sim \pi({\bf{z}}) z∼π(z)和 x ∼ p ( x ) {\bf{x}}\sim p({\bf{x}}) x∼p(x),并且概率密度函数 π ( z ) \pi({\bf{z}}) π(z)已知, M A F \mathrm{MAF} MAF旨在学习 p ( x ) p({\bf{x}}) p(x)。 M A F \mathrm{MAF} MAF生成每个 x i x_i xi以过去的维度 x 1 : i − 1 {\bf{x}}_{1:i-1} x1:i−1为条件。准确地说,条件概率是 z {\bf{z}} z的仿射变换,其中尺度和移位项是 x {\bf{x}} x的观察部分的函数。数据生成时,会产生出一个新的 x {\bf{x}} x,公式如下所示 x i ∼ p ( x i ∣ x 1 : i − 1 ) = z i ⊙ σ i ( x 1 : i − 1 ) + μ i ( x 1 : i − 1 ) x_i\sim p(x_i|{ {\bf{x}}_{1:i-1}})=z_i\odot \sigma_i({\bf{x}}_{1:i-1})+\mu_i({\bf{x}}_{1:i-1}) xi∼p(xi∣x1:i−1)=zi⊙σi(x1:i−1)+μi(x1:i−1)给定 x {\bf{x}} x时,密度估计为 p ( x ) = ∏ i = 1 D p ( x i ∣ x 1 : i − 1 ) p({\bf{x}})=\prod_{i=1}^D p(x_i|{\bf{x}}_{1:i-1}) p(x)=i=1∏Dp(xi∣x1:i−1)该框架的方法优点在于生成过程是顺序的,因此设计速度很慢。而密度估计只需要使用 M A D E \mathrm{MADE} MADE等网络架构。变换函数对逆很简单,雅可比行列式也很容易计算。
6.4 IAF
与 M A F \mathrm{MAF} MAF类似,逆自回归流 I A F \mathrm{IAF} IAF也将目标变量的条件概率建模为自回归模型,但采用反向流动,从而实现了非常有效的采样过程。 M A F \mathrm{MAF} MAF中的仿射变换为: z i = x i − μ i ( x 1 : i − 1 ) σ i ( x 1 : i − 1 ) = − μ i ( x 1 : i − 1 ) σ i ( x 1 : i − 1 ) + x i ⊙ 1 σ i ( x 1 : i − 1 ) z_i=\frac{x_i -\mu_i({\bf{x}}_{1:i-1})}{\sigma_i({\bf{x}}_{1:i-1})}=-\frac{\mu_i({\bf{x}}_{1:i-1})}{\sigma_i({\bf{x}}_{1:i-1})}+x_i \odot \frac{1}{\sigma_i({\bf{x}}_{1:i-1})} zi=σi(x1:i−1)xi−μi(x1:i−1)=−σi(x1:i−1)μi(x1:i−1)+xi⊙σi(x1:i−1)1如果令
x ~ = z , p ~ ( ⋅ ) = π ( ⋅ ) , x ~ ∼ p ~ ( x ~ ) x ~ = x , π ~ ( ⋅ ) = p ( ⋅ ) , z ~ ∼ π ~ ( z ~ ) μ ~ i ( z ~ 1 : i − 1 ) = μ ~ i ( x 1 : i − 1 ) = − μ i ( x 1 : i − 1 ) σ i ( x 1 : i − 1 ) σ ~ ( z ~ 1 : i − 1 ) = σ ~ ( x 1 : i − 1 ) = 1 σ i ( x 1 : i − 1 ) \begin{aligned}&\tilde{ {\bf{x}}}={\bf{z}},\text{ }\tilde{p}(\cdot)=\pi(\cdot),\text{ }\tilde{ {\bf{x}}}\sim\tilde{p}(\tilde{\bf{x}})\\&{\tilde{\bf{x}}}={\bf{x}}\text{ },\tilde{\pi}(\cdot)=p(\cdot),\text{ }{\bf{\tilde{z}}}\sim\tilde{\pi}({\bf{\tilde{z}}})\\&\tilde{\mu}_i(\tilde{\bf{z}}_{1:i-1})=\tilde{\mu}_i({\bf{x}}_{1:i-1})=-\frac{\mu_i({\bf{x}}_{1:i-1})}{\sigma_i({\bf{x}}_{1:i-1})}\\&\tilde{\sigma}(\tilde{ {\bf{z}}}_{1:i-1})=\tilde{\sigma}({\bf{x}}_{1:i-1})=\frac{1}{\sigma_i({\bf{x}}_{1:i-1})}\end{aligned} x~=z, p~(⋅)=π(⋅), x~∼p~(x~)x~=x ,π~(⋅)=p(⋅), z~∼π~(z~)μ~i(z~1:i−1)=μ~i(x1:i−1)=−σi(x1:i−1)μi(x1:i−1)σ~(z~1:i−1)=σ~(x1:i−1)=σi(x1:i−1)1则有 x ~ i ∼ p ( x ~ i ∣ z ~ 1 : i ) = z ~ i ⊙ σ ~ i ( z ~ 1 : i − 1 ) + μ ~ i ( z ~ 1 : i − 1 ) , w h e r e z ~ ∼ π ~ ( z ~ ) {\tilde{x}}_i\sim p(\tilde{x}_i|{\bf{\tilde{z}}}_{1:i})=\tilde{z}_i\odot \tilde{\sigma}_i({\bf{\tilde{z}}}_{1:i-1})+\tilde{\mu}_i({\bf{\tilde{z}}}_{1:i-1}),\quad \mathrm{where}\text{ }{\tilde{\bf{z}}}\sim \tilde{\pi}({\bf{\tilde{z}}}) x~i∼p(x~i∣z~1:i)=z~i⊙σ~i(z~1:i−1)+μ~i(z~1:i−1),where z~∼π~(z~)如下图示所示, I A F \mathrm{IAF} IAF打算估计已知 π ~ ( z ~ ) \tilde{\pi}(\tilde{\bf{z}}) π~(z~)的给定 x ~ \tilde{\bf{x}} x~的概率密度函数。逆流也是自回归仿射变换,与 M A F \mathrm{MAF} MAF相同,但尺度和移位项是已知分布 π ~ ( z ~ ) \tilde{\pi}(\tilde{\bf{z}}) π~(z~)中观察变量的自回归函数。
单个元素 x ~ i \tilde{x}_i x~i的计算不相互依赖,因此它们很容易并行化。已知 x ~ \tilde{\bf{x}} x~的密度估计效率不高,因为必须按顺序恢复 z ~ i \tilde{z}_i z~i的值,即为 z ~ i = ( x ~ i − μ ~ i ( z ~ 1 : i − 1 ) ) / σ ~ i ( z 1 : i − 1 ) \tilde{z}_i=(\tilde{x}_i-\tilde{\mu}_i(\tilde{\bf{z}}_{1:i-1}))/\tilde{\sigma}_i({\bf{z}}_{1:i-1}) z~i=(x~i−μ~i(z~1:i−1))/σ~i(z1:i−1),因此总计需要 D D D次估计。
边栏推荐
- [inverted pendulum control] Simulink simulation of inverted pendulum control based on UKF unscented Kalman filter
- Gateway微服务路由使微服务静态资源加载失败
- Unity WebGL打包后怎么运行(火狐配置)
- Desai wisdom number - histogram (column folding mixed graph): ratio of rental price to rental income in the graduation quarter of 2021
- RichView TRVStyle
- adb双击POWER键指令
- [today in history] June 10: Apple II came out; Microsoft acquires gecad; The scientific and technological pioneer who invented the word "software engineering" was born
- [today in history] June 5: Lovelace and Babbage met; The pioneer of public key cryptography was born; Functional language design pioneer born
- Why are so many people keen on big factories because of the great pressure and competition?
- 分布式事务—基于消息补偿的最终一致性方案(本地消息表、消息队列)
猜你喜欢
![抓包整理外篇fiddler————了解工具栏[一]](/img/5f/24fd110a73734ba1638f0aad63c787.png)
抓包整理外篇fiddler————了解工具栏[一]

Why are so many people keen on big factories because of the great pressure and competition?

英特尔锐炫A380显卡即将在中国面市

TensorRT 模型推理优化实现

3年功能测试拿8K,被刚来的测试员反超,其实你在假装努力

Severe Tire Damage:世界上第一个在互联网上直播的摇滚乐队

树莓派-环境设置和交叉编译

2021年软件测试工具总结——模糊测试工具
R language penalty logistic regression, linear discriminant analysis LDA, generalized additive model GAM, multiple adaptive regression splines Mars, KNN, quadratic discriminant analysis QDA, decision
![[today in history] June 8: the father of the world wide web was born; PHP public release; IPhone 4 comes out](/img/1b/31b5adbec5182207c371a23e41baa3.png)
[today in history] June 8: the father of the world wide web was born; PHP public release; IPhone 4 comes out
随机推荐
CMU提出NLP新范式—重构预训练,高考英语交出134高分
分布式事务解决方案Seata-Golang浅析
Summary of software testing tools in 2021 - fuzzy testing tools
Intel Ruixuan A380 graphics card will be launched in China
[elevator control system] design of elevator control system based on VHDL language and state machine, using state machine
Windows 2003 64 bit system PHP running error: 1% is not a valid Win32 Application
Initial linear regression
[today in history] June 17: the creator of the term "hypertext" was born; The birth of Novell's chief scientist; Discovery channel on
Is it reliable to invest in the inter-bank certificate of deposit fund? Is the inter-bank certificate of deposit fund safe
Thesis reading: General advantageous transformers
无代码软件发展简史及未来趋势
Why are so many people keen on big factories because of the great pressure and competition?
isEmpty 和 isBlank 的用法区别
Tips for visiting the website: you are not authorized to view the recovery method of this page
be fond of the new and tired of the old? Why do it companies prefer to spend 20K on recruiting rather than raise salaries to retain old employees
apache、iis6、ii7独立ip主机屏蔽拦截蜘蛛抓取(适用vps云主机服务器)
Domain Name System
Writing based on stm32
Severe Tire Damage:世界上第一个在互联网上直播的摇滚乐队
测试要掌握的技术有哪些?软件测试必懂的数据库设计大全篇