当前位置:网站首页>CEPH operation and maintenance common instructions
CEPH operation and maintenance common instructions
2022-06-26 10:48:00 【BOGO】
One 、 colony
1、 Start a ceph process
start-up mon process
service ceph start mon.node1
start-up msd process
service ceph start mds.node1
start-up osd process
service ceph start osd.0
2、 Check the monitoring status of the machine
[[email protected] ~]# ceph health
HEALTH_OK
3、 see ceph The real-time running state of
[[email protected] ~]# ceph -w
4、 Check information status information
[[email protected] ~]# ceph -s
5、 see ceph Storage space
[[email protected] ~]# ceph df
6、 Delete all... Of a node ceph Data packets
[[email protected] ~]# ceph-deploy purge node1
[[email protected] ~]# ceph-deploy purgedata node1
7、 by ceph Create a admin Users are not admin The user creates a key , Save the key to /etc/ceph Under the table of contents :
ceph auth get-or-create client.admin mds 'allow' osd 'allow *' mon 'allow *' > /etc/ceph/ceph.client.admin.keyring
or
ceph auth get-or-create client.admin mds 'allow' osd 'allow *' mon 'allow *' -o /etc/ceph/ceph.client.admin.keyring
8、 by osd.0 Create a user and create one key
ceph auth get-or-create osd.0 mon 'allow rwx' osd 'allow *' -o /var/lib/ceph/osd/ceph-0/keyring
9、 by mds.node1 Create a user and create one key
ceph auth get-or-create mds.node1 mon 'allow rwx' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mds/ceph-node1/keyring
10、 see ceph Authenticated users in a cluster and related key
ceph auth list
11、 Delete an authenticated user in the cluster
ceph auth del osd.0
12、 View the detailed configuration of the cluster
[[email protected] ~]# ceph daemon mon.node1 config show | less
13、 See the cluster health details
[[email protected] ~]# ceph health detail
14、 see ceph log The directory where the log is located
[[email protected] ~]# ceph-conf --name mon.node1 --show-config-value log_file
Two 、mon
1、 see mon Status information
[[email protected] ~]# ceph mon stat
2、 see mon The state of the election
[[email protected] ~]# ceph quorum_status
3、 see mon Mapping information for
[[email protected] ~]# ceph mon dump
4、 Delete one mon node
[[email protected] ~]# ceph mon remove node1
5、 Get a running mon map, For binary mon.bin
[[email protected] ~]# ceph mon getmap -o mon.bin
6、 Check out the above map
[[email protected] ~]# monmaptool --print mon.bin
[[email protected] ~]#
7、 Put the above mon map Inject new nodes
ceph-mon -i node4 --inject-monmap mon.bin
8、 see mon Of amin socket
[email protected] ~]# ceph-conf --name mon.node1 --show-config-value admin_socket
9、 see mon Detailed state
[[email protected] ~]# ceph daemon mon.node1 mon_status
10、 Delete one mon node
[[email protected] ~]# ceph mon remove os-node1
3、 ... and 、msd
1、 see msd state
[[email protected] ~]# ceph mds stat
2、 see msd Mapping information for
[[email protected] ~]# ceph mds dump
3、 Delete one mds node
[[email protected] ~]# ceph mds rm 0 mds.node1
Four 、osd
1、 see ceph osd Running state
[[email protected] ~]# ceph osd stat
2、 see osd The mapping information
[[email protected] ~]# ceph osd dump
3、 see osd Directory tree for
[[email protected] ~]# ceph osd tree
4、down Drop one osd Hard disk
[[email protected] ~]# ceph osd down 0 #down fall osd.0 node
5、 Remove one... From the cluster osd Hard disk
[[email protected] ~]# ceph osd rm 0
removed osd.0
6、 Remove one... From the cluster osd Hard disk crush map
[[email protected] ~]# ceph osd crush rm osd.0
7、 Remove one... From the cluster osd Of host node
[[email protected] ~]# ceph osd crush rm node1
removed item id -2 name 'node1' from crush map
Look at the largest osd The number of
[[email protected] ~]# ceph osd getmaxosd
max_osd = 4 in epoch 514 # The default maximum is 4 individual osd node
8、 Set the largest osd The number of ( When it expands osd You have to expand this value when you create a node )
[[email protected] ~]# ceph osd setmaxosd 10
9、 Set up osd crush The weight for 1.0
ceph osd crush set {id} {weight} [{loc1} [{loc2} ...]]
for example :
[[email protected] ~]# ceph osd crush set 3 3.0 host=node4
set item id 3 name 'osd.3' weight 3 at location {host=node4} to crush map
[[email protected] ~]# ceph osd tree
Or in the following way
[[email protected] ~]# ceph osd crush reweight osd.3 1.0
reweighted item id 3 name 'osd.3' to 1 in crush map
[[email protected] ~]# ceph osd tree
10、 Set up osd The weight of
[[email protected] ~]# ceph osd reweight 3 0.5
11、 Put one osd The node is evicted from the cluster
[[email protected] ~]# ceph osd out osd.3
12、 Get rid of osd To join the cluster
[[email protected] ~]# ceph osd in osd.3
13、 Pause osd ( After the pause, the entire cluster no longer receives data )
[[email protected] ~]# ceph osd pause
set pauserd,pausewr
14、 Turn it on again osd ( Turn it on and receive data again )
[[email protected] ~]# ceph osd unpause
unset pauserd,pausewr
15、 Look at a cluster osd.2 Parameter configuration
ceph --admin-daemon /var/run/ceph/ceph-osd.2.asok config show | less
16、 If osd broken , If the process is still in progress
ceph tell osd.1740 bench # Go to osd.1740 Writing data , The process will kill myself 17、 adjustment osd Recovery priority of
ceph daemon /var/run/ceph/ceph-osd.$id.asok config set osd_max_backfills 105、 ... and 、PG Group
1、1、 see pg Group mapping information
[[email protected] ~]# ceph pg dump
dumped all in format plain
version 1164
stamp 2014-06-30 00:48:29.754714
last_osdmap_epoch 88
last_pg_scan 73
full_ratio 0.95
nearfull_ratio 0.85
pg_stat objects mip degr unf bytes log disklog state state_stamp v reported up up_primary acting acting_primary last_scrub scrub_stamp last_deep_scrudeep_scrub_stamp
0.3f 39 0 0 0 163577856 128 128 active+clean 2014-06-30 00:30:59.193479 52'128 88:242 [0,2] 0 [0,2] 0 44'25 2014-06-29 22:25:25.282347 0'0 2014-06-26 19:52:08.521434
The following sections are omitted
2、 View one PG Of map
[[email protected] ~]# ceph pg map 0.3f
osdmap e88 pg 0.3f (0.3f) -> up [0,2] acting [0,2] # Among them [0,2] Represents stored in osd.0、osd.2 node ,osd.0 Represents the storage location of the primary replica
3、 see PG state
[[email protected] ~]# ceph pg stat
v1164: 448 pgs: 448 active+clean; 10003 MB data, 23617 MB used, 37792 MB / 61410 MB avail
4、 Query a pg Details of
[[email protected] ~]# ceph pg 0.26 query
5、 see pg in stuck The state of
[[email protected] ~]# ceph pg dump_stuck unclean
ok
[[email protected] ~]# ceph pg dump_stuck inactive
ok
[[email protected] ~]# ceph pg dump_stuck stale
ok
6、 Show all of the... In a cluster pg Statistics
ceph pg dump --format plain
7、 Recover a lost pg
ceph pg {pg-id} mark_unfound_lost revert
8、 Showing abnormal state pg
ceph pg dump_stuck inactive|unclean|stale
6、 ... and 、pool
1、 see ceph In the cluster pool Number
[[email protected] ~]# ceph osd lspools
0 data,1 metadata,2 rbd,
2、 stay ceph Create a pool
ceph osd pool create jiayuan 100 # there 100 refer to PG Group
3、 For one ceph pool Configure quotas
ceph osd pool set-quota data max_objects 10000
4、 Remove one... From the cluster pool
ceph osd pool delete testpool testpool --yes-i-really-really-mean-it # The cluster name needs to be repeated twice
5、 Show in cluster pool Details of
[[email protected] ~]# rados df
[[email protected] ~]#
6、 Give me a pool Create a snapshot
[[email protected] ~]# ceph osd pool mksnap data date-snap
created pool data snap date-snap
7、 Delete pool Snapshot
[[email protected] ~]# ceph osd pool rmsnap data data-snap
removed pool data snap date-snap
8、 see data Pooled pg Number
[[email protected] ~]# ceph osd pool get data pg_num
pg_num: 64
9、 Set up data The maximum storage space of the pool is 100T( The default is 1T)
[[email protected] ~]# ceph osd pool set data target_max_bytes 100000000000000
set pool 0 target_max_bytes to 100000000000000
10、 Set up data The number of copies of the pool is 3
[[email protected] ~]# ceph osd pool set data size 3
set pool 0 size to 3
11、 Set up data The minimum copy of a pool that can accept write operations is 2
[[email protected] ~]# ceph osd pool set data min_size 2
set pool 0 min_size to 2
12、 Look at all of... In the cluster pool Copy size of
[[email protected] mycephfs]# ceph osd dump | grep 'replicated size'
pool 2 'rbd' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 owner 0 flags hashpspool stripe_width 0
13、 Set up a pool Of pg Number
[[email protected] ~]# ceph osd pool set data pg_num 100
set pool 0 pg_num to 100
14、 Set up a pool Of pgp Number
[[email protected] ~]# ceph osd pool set data pgp_num 100
set pool 0 pgp_num to 100
7、 ... and 、rados and rbd Instructions
1、rados Command usage
(1)、 see ceph How many in the cluster pool ( Just looking at pool)
[[email protected] ~]# rados lspools
(2)、 see ceph How many in the cluster pool, And each pool Capacity and utilization
[[email protected] ~]# rados df
(3)、 Create a pool
[[email protected] ~]#rados mkpool test
(4)、 see ceph pool Medium ceph object ( there object It's stored in blocks )
[[email protected] ~]# rados ls -p volumes | less
rbd_data.348f21ba7021.0000000000000866
rbd_data.32562ae8944a.0000000000000c79
(5)、 Create an object object
[[email protected] ~]# rados create test-object -p test
[[email protected] ~]# rados -p test ls
test-object
(6)、 Delete an object
[[email protected] ~]# rados rm test-object-1 -p test
2、rbd command reference
(1)、 see ceph In a pool All the images in the picture
[[email protected] ~]# rbd ls volumes
(2)、 see ceph pool The information of a mirror image in
[[email protected] ~]# rbd info -p images --image test
(3)、 stay test Create a pool named test2 Of 10000M Mirror image
[[email protected] ~]# rbd create -p test --size 10000 test2
(4)、 Delete a mirror image
[[email protected] ~]# rbd rm -p test test2
(5)、 Adjust the size of a mirror image
[[email protected] ~]# rbd resize -p test --size 20000 test3
Resizing image: 100% complete...done.
(6)、 Create a snapshot of an image
[[email protected] ~]# rbd snap create test/[email protected] # pool / Mirror image @ snapshot
[[email protected] ~]# rbd snap ls -p test test3
[[email protected] ~]#
[[email protected] ~]# rbd info test/[email protected]
(7)、 View a snapshot of an image file
[[email protected] ~]# rbd snap ls -p volumes test
(8)、 Delete a snapshot of a mirrored file
The pool where the snapshot resides / The image file where the snapshot is located @ snapshot
[[email protected] ~]# rbd snap rm volumes/[email protected]
2014-08-18 19:23:42.099301 7fd0245ef760 -1 librbd: removing snapshot from header failed: (16) Device or resource busy
The error message displayed above cannot be deleted because the snapshot is write protected , The following command is to delete the write protection and then delete it .
[[email protected] ~]# rbd snap unprotect volumes/[email protected]
[[email protected] ~]# rbd snap rm volumes/[email protected]
(9) Delete all snapshots of a mirror file
[[email protected] ~]# rbd snap purge -p volumes test3
Removing all snapshots: 100% complete...done.
(10)、 hold ceph pool A mirror export in
Export the mirror
[[email protected] ~]# rbd export -p images --image test
2014-05-24 17:16:15.197695 7ffb47a9a700 0 -- :/1020493 >> 10.49.101.9:6789/0 pipe(0x1368400 sd=3 :0 s=1 pgs=0 cs=0 l=1 c=0x1368660).fault
Exporting image: 100% complete...done.
Export cloud disk service
[[email protected] ~]# rbd export -p volumes --image volume-470fee37-b950-4eef-a595-d7def334a5d6 /var/lib/glance/ceph-pool/volumes/test-10.40.212.24
2014-05-24 17:28:18.940402 7f14ad39f700 0 -- :/1032237 >> 10.49.101.9:6789/0 pipe(0x260a400 sd=3 :0 s=1 pgs=0 cs=0 l=1 c=0x260a660).fault
Exporting image: 100% complete...done.
(11)、 Import a mirror image into ceph in ( But direct import doesn't work , Because it didn't go through openstack,openstack It's invisible )
[[email protected] ~]# rbd import /root/aaa.img -p images --image 74cb427c-cee9-47d0-b467-af217a67e60a
Importing image: 100% complete...done.
边栏推荐
- 栖霞市住建局和消防救援大队开展消防安全培训
- DBSCAN
- MySQL Chapter 6 Summary
- MySQL第十三次作业-事务管理
- Win10 start FTP service and set login authentication
- RDB持久化验证测试
- Yarn package management tool
- SQL Server foundation introduction collation
- Index summary of blog articles -- Industrial Internet
- The fourteenth MySQL operation - e-mall project
猜你喜欢

Quantitative investment learning - Introduction to classic books

Under the double reduction, the amount of online education has plummeted. Share 12 interesting uses of webrtc

Getting started with postman

The fourteenth MySQL operation - e-mall project

Redis (basic) - learning notes

Hazelnut cloud - SMS (tool)

Flutter与原生通信(上)
![[work details] March 18, 2020](/img/24/a72230daac08e7ec5bd57df08071f8.jpg)
[work details] March 18, 2020
![Installer MySQL sous Linux [détails]](/img/38/77be56c3ef3923ce4c4e5df4a96f41.png)
Installer MySQL sous Linux [détails]
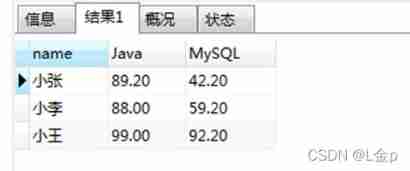
About multi table query of MySQL
随机推荐
The difference between NPM and yarn
Index summary of blog articles -- Industrial Internet
Enter a positive integer with no more than 5 digits, and output the last digit in reverse order
Common interview questions of binary tree
Installing MySQL under Linux [details]
JWT (SSO scheme) + three ways of identity authentication
MySQL第十四次作业--电子商城项目
你好!正向代理!
2020.7.6 interview with fence network technology company
Linux下安装Mysql【详细】
Is it safe to open an account in the school of Finance and business?
Global and Chinese market of amateur football helmets 2022-2028: Research Report on technology, participants, trends, market size and share
SwiftUI 开发经验之为离线优先的应用程序设计数据层
Cereals Mall - Distributed Advanced
Vscode environment setup: synchronous configuration
Global and Chinese markets in hair conditioner 2022-2028: Research Report on technology, participants, trends, market size and share
MySQL 13th job - transaction management
MySQL Chapter 5 Summary
[software project management] sorting out knowledge points for final review
MySQL 9th job - connection Query & sub query