当前位置:网站首页>快手实时数仓保障体系研发实践
快手实时数仓保障体系研发实践
2022-06-24 12:57:00 【InfoQ】
- 业务特点及实时数仓保障痛点
- 快手实时数仓保障体系架构
- 春节活动实时保障实践
- 未来规划
一、业务特点及实时数仓保障痛点

- 快手最大的业务特点就是数据量大。每天入口流量为万亿级别。对于这么大的流量入口,需要做合理的模型设计,防止重复读取的过度消耗。另外还要在数据源读取和标准化过程中,极致压榨性能保障入口流量的稳定执行。
- 第二个特点是诉求多样化。快手业务的需求包括活动大屏的场景、2B 和 2C 的业务应用、内部核心看板以及搜索实时的支撑,不同的场景对于保障的要求都不一样。如果不做链路分级,会存在高低优先级混乱应用的现象,对于链路的稳定性会产生很大的影响。此外,由于快手业务场景的核心是做内容和创作者的 IP,这就要求我们构建通用维度和通用模型,防止重复烟囱建设,并且通过通用模型快速支撑应用场景。
- 第三个特点是活动场景频繁,且活动本身有很高的诉求。核心诉求主要为三个方面:能够体现对公司大盘指标的牵引能力、能够对实时参与度进行分析以及活动开始之后进行玩法策略的调整,比如通过对红包成本的实时监控快速感知活动效果。活动一般都会有上百个指标,但只有 2-3 周的开发时间,这对于稳定性的要求就很高。
- 最后一个特点是快手的核心场景。一个是提供给高管的核心实时指标,另外一个是提供给 C 端的实时数据应用,比如快手小店、创作者中心等。这对数据精度的要求极其高,出现问题需要第一时间感知并介入处理。
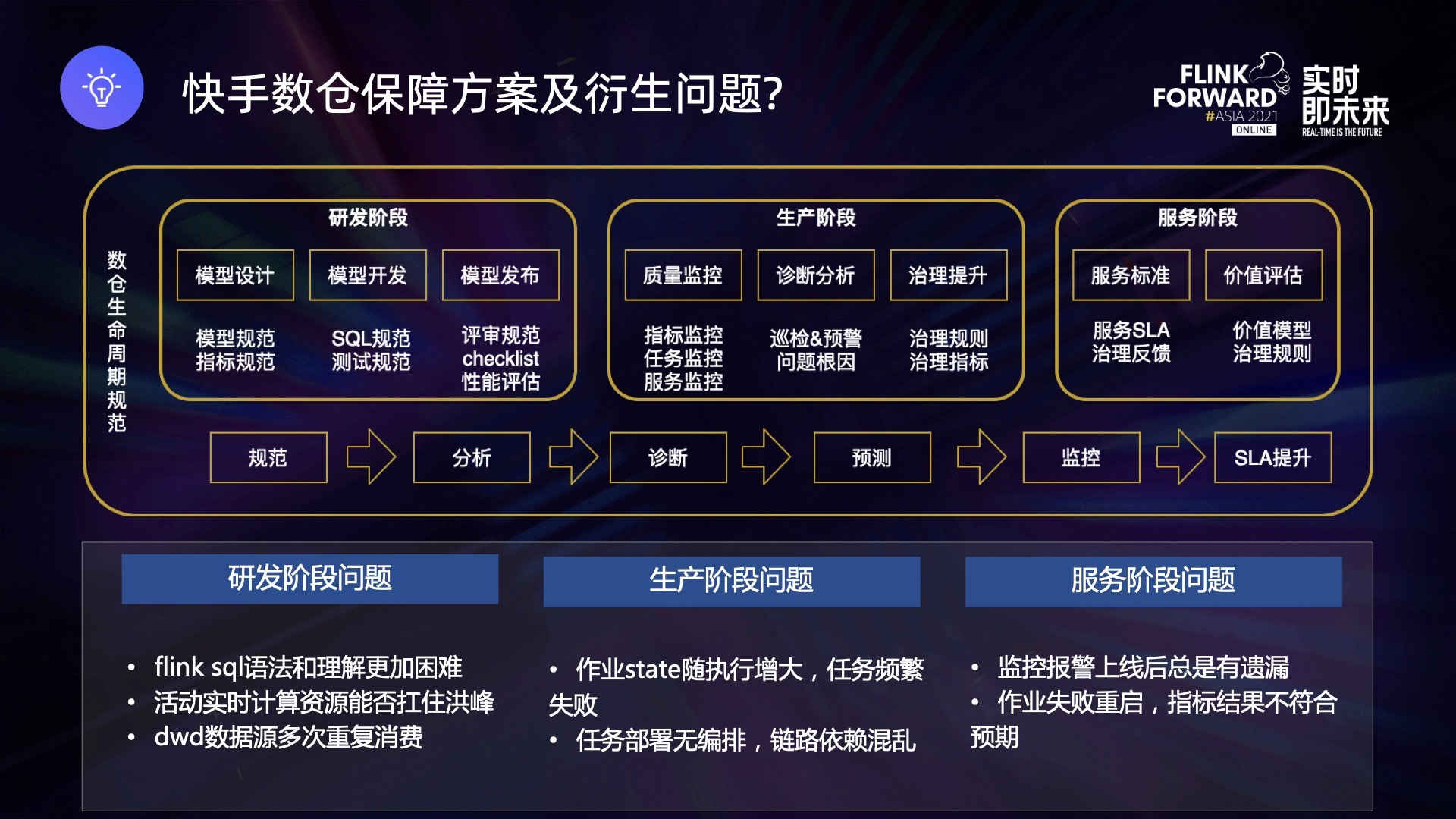
- 研发阶段构建了模型设计规范、模型开发规范以及发布的 checklist。
- 生产阶段主要构建底层监控能力,对于时效性、稳定性、准确性几个方面进行监控,并且依照监控能力进行 SLA 优化和治理提升。
- 服务阶段明确了上游对接的服务标准和保障级别,以及对于整个服务的价值评估。
- 研发阶段:Flink SQL 的学习曲线相比于 Hive SQL 更高,容易在开发阶段引入隐患。另外,实时计算场景下,活动出现洪峰时能否快速消费,也是一个未知数。最后,DWD 层的重复消费对于实时侧的资源挑战也很大,在选择数据源和依赖关系时需要考虑资源问题。
- 生产阶段: state 没有清理机制会导致状态变大、作业频繁失败。另外高优先级和低优先级部署需要机房隔离,因此需要在上线前就安排好,上线后再进行调整,成本会比离线高很多。
- 服务阶段:对于一个实时任务,最无法接受的就是作业流程失败、重启,导致数据重复或者曲线掉坑的问题。为了避免这类问题,需要有标准化的方案,而离线大概率可以保证重启后数据一致性。

- 高时效性。相比于离线的执行时间,实时情况下,延迟分钟级就要介入运维,对时效性要求很高。
- 复杂性。主要体现在两个方面:一方面数据不是导入即可查,数据逻辑验证的难度更高;另外一方面,实时大多是有状态,服务发生问题的时候状态不一定能够被完整保存,会存在很多无法复现的 bug。
- 数据流量大。整体的 QPS 比较高,入口流量级别在亿级。
- 问题随机性。实时数仓发生问题的时间点更加随机,没有规律可循。
- 开发能力良莠不齐。如何保证通用场景的开发方案统一,防止因开发方案不同而产生不可控的问题。
二、快手实时数仓保障体系架构

- 一方面是以开发生命周期为基础的正向保障思路,确保每一个生命周期都有规范和方案指导,标准化 80% 的常规需求。
- 另一方面是以故障注入和场景模拟为基础的反向保障思路,通过场景模拟和故障注入,确保保障措施真正落地并符合预期。
2.1 正向保障

- 开发阶段主要做需求调研,针对开发过程中基础层如何开发、应用层如何开发进行标准化处理,可以解决 80% 的通用需求,剩余 20% 的个性化需求通过方案评审的方式来满足,同时不断从个性化需求中沉淀标准化方案。
- 测试阶段主要做质量验证和离线侧对比以及压测资源预估。自测阶段主要通过离线实时的一致性对比、server 看板和实时结果对比来保障整体准确性。
- 上线阶段主要针对重要任务上线需要准备的预案,确认上线前动作、上线中部署方式和上线后的巡检机制。
- 服务阶段主要是针对于目标做监控和报警机制,确保服务是在 SLA 标准之内的。
- 最后是下线阶段,主要做资源的回收和部署还原工作。

- 第一,DWD 层。DWD 层逻辑侧比较稳定且很少有个性化,逻辑修改分为三种不同的格式数据:客户端、服务端和 Binlog 数据。
- 第一项操作是拆分场景,由于实时数仓没有分区表的逻辑,所以场景拆分的目的是生成子 topic,防止重复消费大 topic 的数据。
- 第二个操作就是字段标准化,其中包括纬度字段的标准化处理、脏数据的过滤、IP 和经纬度一一映射关系的操作。
- 第三是处理逻辑的维度关联,通用维度的关联尽量在 DWD 层完成,防止下游过多流量依赖导致维表压力过大,通常维表是通过 KV 存储 + 二级缓存的方式来提供服务。
- 第二,DWS 层。这里有两种不同的处理模式:一是以维度和分钟级窗口聚合为基础的 DWS 层,为下游可复用场景提供聚合层的支撑;二是单实体粒度的 DWS 层数据,比如原始日志里核心用户和设备粒度的聚合数据,可以极大地减少 DWD 层大数据量的关联压力,并能够更有效地进行复用。DWS 层数据也需要进行维度扩充,由于 DWD 层数据量过大,无法完全 cover 维度关联的场景,因此维度关联 QPS 过高并有一定延时的需求,需要在 DWS 层完成。
- 第三,ADS 层。它的核心是依赖 DWD 层和 DWS 层的数据进行多维聚合并最终输出结果。




- 活动前,部署任务确保没有计算热点、check 参数是否合理、观察作业情况以及集群情况;
- 活动中,检查指标输出是否正常、任务状态巡检以及遇到问题的故障应对和链路切换;
- 活动后,下线活动任务、回收活动资源、恢复链路部署及复盘。

- P0 任务是活动大屏,C 端应用对于 SLA 的要求是秒级延迟以及 0.5% 内误差,但是整体保障时间比较短,一般活动周期都在 20 天左右,除夕类活动 1~2 天内完成。我们应对延迟的方案是针对于 Kafka 和 OLAP 引擎都进行了多机房容灾,针对于 Flink 做了热备双机房部署。
- 针对 P1 级别的任务,我们对 Kafka 和 OLAP 引擎进行双机房部署,一方面双机房部署可以做容灾逃生,另一方面在线机房的配置比较好,很少出现机器故障导致作业重启的情况。
- 针对 P2 和 P3 级别的任务,我们在离线机房部署,如果存在一些资源空缺的情况,会先停止 P3 任务,腾挪资源给其他任务使用。

- 第一,SLA 监控主要监控整体产出指标的质量、时效性和稳定性。
- 第二,链路任务监控主要对任务状态、数据源、处理过程、输出结果以及底层任务的 IO、CPU 网络、信息做监控。
- 第三,服务监控主要包括服务的可用性和延迟。
- 最后是底层的集群监控,包括底层集群的 CPU、IO 和内存网络信息。

- 准确性报警又分成 4 个方面,准确性、波动性、一致性和完整性。准确性包括主备链路侧的一些对比,维度下钻是否准确;波动性是衡量持续指标的波动范围,防止波动大产生的异常;一致性和完整性通过枚举和指标度量保证产出一致且不存在残缺的情况。
- 时效性的目标也有 3 个,接口延迟的报警、OLAP 引擎报警和接口表 Kafka 延迟报警。拆分到链路层面,又可以从 Flink 任务的输入、处理和输出三个方面进行分析:输入核心关注延迟和乱序情况,防止数据丢弃;处理核心关注数据量和处理数据的性能指标;输出则关注输出的数据量多少,是否触发限流等。
- 稳定性的目标有 2 个,一个是服务和 OLAP 引擎的稳定性、批流延迟,另一个是 Flink 作业的恢复速度。Flink 作业 failover 之后能否快速恢复,对于链路的稳定性也是很大的考验。稳定性主要关注作业执行的负载情况,以及对应服务依赖的状态、整体集群的负载以及单个任务的负载。我们通过目标进行报警,目标拆解的子目标进行监控,构建整体的监控报警体系。
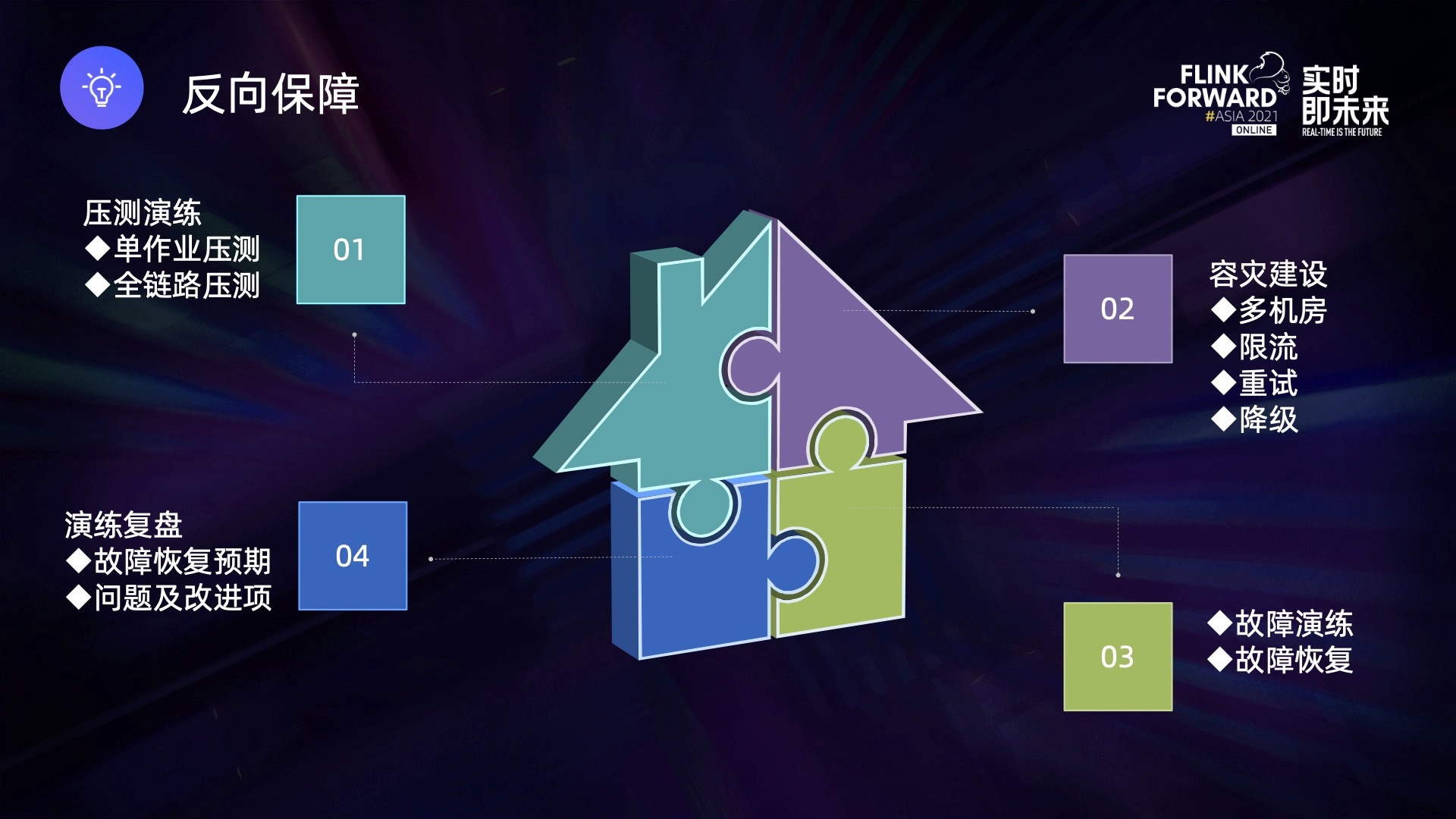
2.2 反向保障
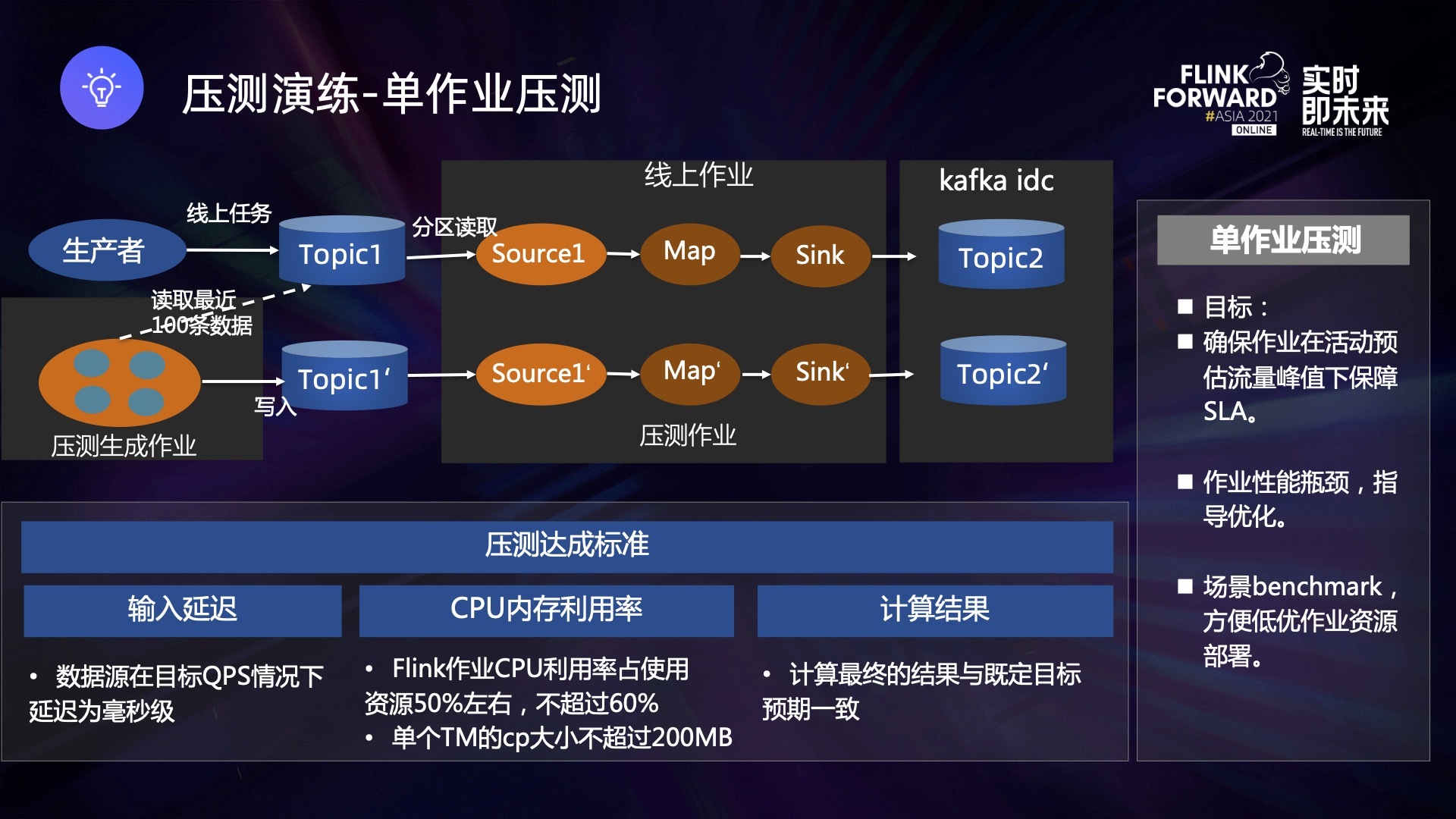
- 第一,确保作业输入读取延迟为毫秒级,且作业本身无任何反压。
- 第二,CPU的利用率不超过整体资源的 60%,保障集群有空余 buffer。
- 第三,计算结果和人群包保持一致,证明逻辑是正确的。

- 第一,确保作业输入读取延迟为毫秒级,且无反压。
- 第二,CPU利用率整体不超过 60%。
- 第三,计算结果最终和人群包保持一致。

- 一个是单作业的故障演练,包括 Kafka topic 作业故障、Flink 作业失败以及 Flink 作业 CP 失败。
- 二是更体系化的故障,比如链路故障,比如单机房故障如何保障正常产出,活动流量超过预期很多如何避免雪崩效应?某个作业 lag 超过一个小时,需要多久能恢复?

三、春节活动实时保障实践

- 高稳定性,海量数据要求链路整体保持稳定或出现故障能够快速恢复。
- 高时效性,亿级别流量下,要求大屏指标卡秒级延迟、曲线 1 分钟级别延迟。
- 高准确性,复杂链路情况下,离线和实时指标差异不超过 0.5%。
- 高灵活性,能够支持活动过程中的多维分析应用场景。


四、未来规划

- 第一,保障能力建设。针对压测和故障注入形成标准化剧本预案,预案执行通过平台能力自动化操作。压测之后,能够对问题进行智能诊断,将过往的一些专家经验进行沉淀。
- 第二,批流一体。过往的活动应用场景过程中,批和流是完全割裂的两套体系,我们在一些场景下做了流批一体的实践,并且正在推动整体平台化建设,通过统一 SQL 的方式提升整体开发效率,并且机器错峰使用可以减少作业压力。
- 第三,实时数仓建设。通过丰富实时数仓内容层面,以及开发组件的沉淀和 SQL 化的手段,达成开发效率的提升,最终达到降本提效的目的。


边栏推荐
- 10 reduce common "tricks"
- Mysql题目篇
- Process basic properties
- CVPR 2022 | 美团技术团队精选论文解读
- 【5G NR】5G NR系统架构
- These default routes and static routes can not be configured and deployed. What kind of network workers are they!
- Kotlin anonymous function and lambda
- Richard Sutton, the father of reinforcement learning, paper: pursuing a general model for intelligent decision makers
- **Unity中莫名其妙得小问题-灯光和天空盒
- Huawei PC grows against the trend, and product power determines everything
猜你喜欢

3. caller service call - dapr

hands-on-data-analysis 第三单元 模型搭建和评估
Hands on data analysis unit 3 model building and evaluation

Without home assistant, zhiting can also open source access homekit and green rice devices?
![[5g NR] 5g NR system architecture](/img/78/6db70c18887c7a3920843d1cb4bdf3.png)
[5g NR] 5g NR system architecture

每日一题day8-515. 在每个树行中找最大值

Golden age ticket: Web3.0 Security Manual
Daily question 8-515 Find the maximum value in each tree row

首席信息安全官仍然会犯的漏洞管理错误

硬件开发笔记(六): 硬件开发基本流程,制作一个USB转RS232的模块(五):创建USB封装库并关联原理图元器件
随机推荐
Kotlin initialization block
万用表的使用方法
Hands on data analysis unit 3 model building and evaluation
Android kotlin 大全
Appium installation
The introduction of MySQL memory parameters is divided into two categories: thread exclusive and global sharing
8 - Format integers and floating point numbers
Comparator sort functional interface
What is the difference between sap QM and UD for inspection lots with hum?
AGCO AI frontier promotion (6.24)
华为 PC 逆势增长,产品力决定一切
3. caller service call - dapr
真正的项目经理强者,都是闭环高手!
kotlin 初始化块
《中国数据库安全能力市场洞察,2022》报告研究正式启动
Kotlin keyword extension function
kotlin 接口 泛型 协变 逆变
Kotlin interface generic covariant inversion
美国会参议院推进两党枪支安全法案
Redis scenario