当前位置:网站首页>You call this shit MQ?
You call this shit MQ?
2022-06-23 13:18:00 【Programmer Xiaohui】
Happy troubles
Zhang Da Pang is both happy and worried recently , The good news is that the business volume has soared , The worry is that due to the surge in business volume , Some problems that were not problems have become big problems , For example, new member registration , The original registration is successful, just send a text message , But as the business grows , Now you need to send a message to register successfully push, Give coupons ,… etc.
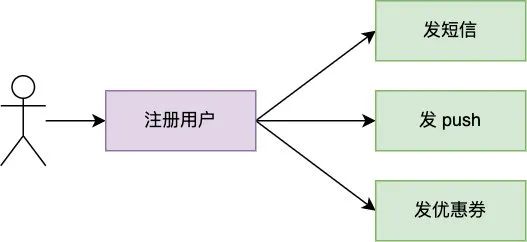
In this way, just registering users requires calling many services , As a result, user registration takes a lot of time , Suppose that each service invocation requires 50 ms, Then the above services alone need to call 200 ms, And the follow-up products may add some more Send new people red envelopes Other activities , Each additional function , In addition to introducing additional services to increase time consumption , Additional integration services are required , Retransmission code , It's really annoying , Zhang Dafan wants to solve this problem once and for all , So I found CTO Bill Let's discuss , See if you can provide some ideas
Bill You can see the problem at a glance : There are three problems with your system : Sync , coupling , The risk of system collapse in case of traffic surge
Sync: We can see that after registering users , You need to call other modules synchronously before you can return , This is the root cause of the time-consuming !coupling: Registered users are heavily coupled with other modules , Embodied in every call to a module , You need to integrate the code of other modules at the registered user code and republish it , In these processes, onlyRegistered usersThis step is the core process , Others are secondary processes , The core process should be decoupled from the secondary process , Otherwise, as long as one of the secondary process calls fails , The whole process failed , Reflected in the front end is that Mingming has registered successfully , But what is returned to the user is failureRisk of traffic surge: If one day camp activities , For example, red envelopes for newcomers after registration , Then it is likely to lead to a surge in user registered traffic , Well, because our process of registering users is too long , It is likely that the registered user's service cannot bear the corresponding traffic pressure, resulting in system avalanche
Not the kui is a CTO, See the problem at a glance ,「 So what's the solution 」 Zhang Da Pang asked
「 Big fat , You should have heard a saying : Any software problem can be solved by adding an intermediate layer , If not , Then add another layer , Similarly, we can add an intermediate layer to solve the above problems , For example, add a queue , Put the user registration event in the queue , Let other modules fetch this event from this queue, and then do the corresponding operation 」Bill While talking, he drew what he called the middle tier queue

You can see , This is a typical producer - Consumer model , After the user registers, he can return immediately as long as he throws the registration event to this queue , It realizes the transformation of synchronization into asynchrony , As long as other services pull event consumption from this queue, they can carry out subsequent operations , At the same time, it also realizes the decoupling between the registered user logic and other services , In addition, even if the traffic surge does not affect , Because the registered user sent the event to the queue and immediately returned , This message may be as long as 5 ms, In other words, the total time is 50ms+5ms = 55 ms, The original total time is 200 ms, The throughput and response speed of the system have been improved by nearly 4 times , It greatly improves the responsibility of the system , This step is what we often say Peak shaving , Put the surge traffic into the queue to achieve a smooth transition
「 Wonderful , Add a layer of queue to reach asynchronous , decouple , Peak shaving Purpose , It also perfectly solved my problem 」 Zhang Dafu said excitedly
「 Don't be happy too soon , Think about which queue to use ,JDK Whether the built-in queue is feasible , Or what kind of queue can meet our conditions 」Bill Reminders
Zhang Dafu thought about it. If you use it directly JDK Queues (Queue) There may be the following problems :
Because the queue is in the service memory of the producer , Other consumers have to take from producers , This means that producers and consumers are tightly coupled , This is obviously unreasonable
Lost message : Now it's time to store the message in the queue , The queue is in memory , If the machine goes down , The messages in the queue are lost , Obviously unacceptable
Messages in a single queue can only be consumed by one service , That is, if a service takes messages from the queue and consumes them , Other services can't get this message , There is a way to , Prepare a queue for each service , In this way, the message is sent to only one queue , Then copy the complete message to other queues through this queue

Although this practice can be done in theory , But there are obvious problems in practice , Because this means that an identical queue must be prepared for each service docking , And there are serious problems in the performance of copying multiple messages , You must also ensure that messages are not lost during replication , Undoubtedly, it increases the difficulty of technical implementation
broker
For the above problems Bill After discussing with Zhang Dafu, I decided to design a message queue independent of producers and consumers ( Let's call the component in the middle that holds the message Broker), In this way, problem one is solved , The producer sent the message to Broker, Consumers just need to send the message from Broker Just pull it out and spend it , Producers and consumers are completely decoupled , as follows

So this Broker How should we design to meet our requirements , Obviously, it should meet the following conditions :
Message persistence : Can't because Broker When it goes down, all the messages are lost , So messages can't just be saved in memory , Should persist to disk , For example, keep it in a file , In this way, because the message is persistent , It can also be consumed by multiple consumers , As long as each consumer keeps the corresponding consumption progress , It can realize the independent consumption of multiple consumers
High availability : If Broker It's down. ,producer You can't send a message ,consumer Can't consume , This is obviously unacceptable , So you have to make sure Broker High availability
High performance : Let's set an index , such as 10w TPS, Then to achieve this goal, we must meet the following three conditions :
-- producer Send messages quickly ( Or say broker Receive messages quickly )
-- It's faster to persist to files
-- consumer Pull the news quickly
Next let's look at broker The overall design of
For question one , We can store messages in files , Message through Write the file sequentially To ensure the high performance of writing files

The performance of sequential file writing is very high , Close to random writes in memory , As shown in the figure below

such consumer If you want to spend , You can read the message from the storage file . Okay , Now comes the question , We all know that the message file is stored in the hard disk , If every time broker All received messages are written to a file , Every time consumer Read messages read files from the hard disk , Because it's all disks IO, It's very time consuming , What can be done about it
page cache
disk IO Is very slow , for fear of CPU Every time you read or write a file, you have to interact with the disk , Usually first read the file into memory , And then by CPU visit , such CPU It's much faster to read and write files directly in memory , So how to read files from disk into memory , First of all, we need to understand that the document is based on block( block ) Of the form read , and Linux The kernel will be in memory in page size ( It's usually 4KB) Assign units to . When reading and writing files , The kernel will request memory pages ( Memory pages are page, Multiple page form page cache, Page cache ), And then put the block Load into page cache (n block size = 1 page size, If one block The size is equal to one page, be n = 1) As shown in the figure below

In this way, the process of reading and writing files can be understood at a glance
For reading files :CPU When reading a file , First of all, it will be in page cache Find out whether there is corresponding file data , If there is a direct response to page cache To operate , If not, a page missing exception will be triggered (fault page) Load blocks on disk into page cache in , At the same time, due to the principle of program locality , Multiple... Will be loaded at one time page( Where the data is read page And its adjacent page ) To page cache In order to ensure the reading efficiency
For writing documents :CPU First, the data will be written to page cache in , And then page cache Swipe to disk
CPU The read and write operation of the file is transformed into the read and write operation of the page cache , So just let producer/consumer Read and write message files in memory , It avoids disk IO
mmap
It should be noted that page cache It exists in kernel space , It can't be directly used by the application , Have to go through CPU Put the kernel space page cache Copy to user space to be used by the process ( Similarly, if you write a file , It is also written to the buffer of user space first , Then copy to the kernel space page cache, And then I'll brush the dishes )

Voice over : Why do you want to page cache Copy to user space , This is mainly because the page cache is in kernel space , Can't be directly addressed by user process
The figure above shows the complete process of reading files by the program :
First, the file data in the hard disk is loaded into the file in the kernel space page cache( That is what we usually call kernel buffer )
CPU Copy it to the user buffer in user space
The program maps and operates the user buffer through the virtual memory in the user space ( Both pass MMU To convert ), Then the purpose of reading and writing files in memory is achieved
Simplify the above process as follows

The above is the traditional file reading IO technological process , You can see that the program has experienced a reading of a file read System call and one time CPU Copy , So can the step of copying from kernel buffer to user buffer be cancelled , The answer is yes
Just map the virtual memory to the kernel cache , as follows
")
You can see that there are two benefits of using this method
No CPU Copy , Originally needed CPU Copy from kernel buffer to user buffer , Now this step is omitted
Half the space saved : Because there is no need to page cache Copy to user space , It can be considered that user space and kernel space share page cache
We call this method of reading and writing files in memory by mapping files to the virtual address space of the process mmap(Memory Mapped Files)
The picture above has to be a little simple , Let's take a look at mmap The details of the

First map the files on the disk to the virtual address of the process ( No physical memory has been allocated at this time ), That is to call mmap The function returns a pointer ptr, It points to an address in virtual memory , In this way, the process does not need to call read or write Read and write files , Just go through ptr You can manipulate files , So if you need to read and write the file multiple times , Obviously using mmap More efficient , Because there is only one system call , Compared with many times read or write The overhead of multiple system calls is obviously lower
But it's important to note that ptr It points to a logical address , Physical memory is not actually allocated , Only through ptr Physical memory is allocated only when reading and writing files , After allocation, the page table will be updated , Map virtual memory to physical memory , In this way, the virtual memory can pass through MMU Find physical memory , After allocating memory, the file can be loaded into page cache, So the process can happily read and write files in memory
Use mmap It effectively improves the reading and writing performance of files , It is also an implementation of what we often call zero copy , since mmap So good , Maybe someone is going to ask , Then why don't you use both reading and writing mmap Well , There is no such thing as a free lunch ,mmap There is also a cost , It has the following disadvantages
The file cannot be expanded : Because execution mmap When , The scope of your operation has been determined , Cannot increase file length
The cost of address mapping : In order to create and maintain the mapping relationship between virtual address space and file , The kernel needs a specific data structure to implement this mapping . The kernel maintains a task structure for each process task_struct,task_struct Medium mm_struct Describes information about virtual memory ,mm_struct Medium mmap Field is a vm_area_struct The pointer , Kernel vm_area_struct Objects are organized into a linked list + The structure of the red black tree . As shown in the figure below

So theoretically , Process call once mmap There will be a vm_area_struct object ( Regardless of the kernel automatically merging adjacent and qualified memory regions ),vm_area_struct The increase of the number will increase the management workload of the kernel , Increase system overhead
Missing pages interruption (page fault) The cost of : call mmap The kernel just establishes the logical address ( Virtual memory ) To the physical address ( Physical memory ) Mapping table , No data is actually loaded into physical memory , Page missing interrupt will be triggered only when the page where the data is located is not in memory when actively reading and writing files , Allocate physical memory , Missing pages interrupt reading and writing at a time, which will only trigger one page Loading , One page Only 4k, Imagine once , If a file is 1G, Then you have to trigger 256 Page missing interrupt ! The overhead of interruptions is great , So for large files , There will be many page breaks , This is obviously unacceptable , So general mmap Have to cooperate with another system call madvise, It has a Document preheating The function of can Suggest The kernel reads a large section of file data into memory at one time , This avoids multiple page breaks , At the same time, in order to avoid the file from memory swap To disk , You can also lock this memory area , Avoid swapping out
mmap Not suitable for reading very large files ,mmap need Pre allocate contiguous virtual memory space For mapping files , If the file is large , about 32 Bit address space (4 G) In terms of system , You may not find a continuous area large enough , And if a file is too big , It will squeeze other hot small files page cache Space , Affect the reading and writing performance of these files
To sum up , We set each message file as fixed 1G size , If the file is full, create another one , We call these collections of files that store messages commitlog. This design has another advantage : It's convenient to delete expired files , Just delete all the previous documents , The latest documents do not need to be changed , And if you write all the messages in one file , Obviously, deleting previous expired messages will be very troublesome
consumeQueue file
adopt mmap In this way, we greatly improve the efficiency of reading and writing files , In this way, you can commitlog use mmap Load into page cache in , And then in page cache Read and write messages in , If you are writing a message, write it directly page cache Of course, no problem. , But if it's reading messages ( Consumers pull messages according to the consumption progress ) It's not that simple , Of course, if the size of each message is the same , Then reading the file into memory is actually equivalent to an array , According to the progress of the message, you can quickly locate its location in the file ( Suppose the message progress is offset, The size of each message is size, Then the location to be consumed is offset * size), But obviously, the size of each message can't be the same , The actual situation is likely to be similar to the following

Such as graphic : Here are three messages , The message body of each message is 2kb,3kb,4kb, Message sizes vary
In this case, there will be two problems
The message boundary is unclear , Cannot distinguish between two adjacent messages
Even if the above problems are solved , Nor can it be solved according to the consumption progress Rapid positioning The corresponding message is located in the file . hypothesis broker It's restarted , Then read the consumption progress ( Consumption progress can be persisted into files ), At this time, we have to read the file from the beginning to locate the location of the message in the file , This is clearly not acceptable in terms of efficiency
Can we take advantage of the fast addressing of arrays , It can also quickly locate the location of the message corresponding to the consumption progress in the file , The answer is yes , We can create a new index file ( Let's call this consumeQueue file ), Every time you write commitlog After the document , Put this message in commitlog In the document offset( Let's call this commit offset,8 byte ) And its size (size,4 byte ) One more tag hashcode(8 byte , Its role will be mentioned later ) These three fields are written in sequence consumeQueue In file


In this way, each additional write consumeQueue The size of the file is fixed to 20 Bytes , Because of the fixed size , According to the characteristics of the array , You can quickly locate the location of consumption progress in the index file , Then you can get commitlog offset and size, And then quickly locate it in commitlog Chinese News

Here's the problem , We mentioned above commitlog Fixed file size 1G, When it is full, a new file will be created , For convenience, according to commitlog offset Where is the quick location message commitlog Which position of , We can name the file with the message offset , For example, the offset of the first file is 0, The offset of the second file is 1G(1024*1024*1024 = 1073741824 B), The offset of the third file is 2G(2147483648 B), As shown in the figure below

Empathy ,consumeQueue The file will also be full , When it is full, you should also create a new file and write it again , Our rules consumeQueue It can be saved 30w Data , That is to say 30w * 20 byte = 600w Byte = 5.72 M, In order to locate where the consumption progress is consumeQueue In file , The name of each file is also named after the offset , as follows

Know the file writing and naming rules , Let's look at the process of message writing and consumption
Message write : The first is that messages are written sequentially commitlog In file , The offset of this message in the file after writing (commitlog offset) And size (size) Will be written into the corresponding... In sequence consumeQueue In file
News consumption : Every consumer has a consumption schedule , Because each consumeQueue The file is named according to the offset , First of all, the consumption progress can be quickly located according to the binary search to find out where the progress is consumeQueue file , Further define the location of this file , From this, you can read the... Of the message commitlog offset and size, And then because of commitlog Each file is named according to the offset , So according to commitlog offset Obviously, you can quickly locate where the message is based on binary search commitlog file , Then get the specific location of the message in the file and read the message
Similarly, in order to improve performance , consumeQueue Also use the mmap To read and write
One might say that you searched the file twice , There may be some performance problems , Not really , According to the foregoing , have access to mmap + Document preheating + Lock memory to load and keep files in memory , No matter it is commitlog still consumeQueue It's all in page cache Medium , Since you are looking for files in memory, performance is not a problem
Yes ConsumeQueue Improvement -- Data fragmentation
The scenario we have discussed so far is that multiple consumers consume messages independently , This scenario we call Broadcast mode , In this case, every consumer will consume the news in full , But there is a more common scenario that we haven't considered yet , That's it Cluster pattern , In the cluster mode, each consumer will only consume Some messages , As shown in the figure below :

In the cluster mode, each consumer uses load balancing to consume part of messages in parallel , The main purpose is to accelerate message consumption to avoid message backlog , So here's the problem ,Broker Only one of them consumerQueue, Obviously, it can not meet the needs of parallel consumption in the cluster mode , What to do , We can learn from the design concept of sub database and sub table : Store the data in pieces , The specific approach is to create multiple consumeQueue, Then distribute the data evenly among these consumerQueue in , In this case, each consumer Each responsible for independent consumerQueue Can achieve parallel consumption

Such as graphic : Producer Send message load balancing to queue 0 and queue 1 In line ,consumer A be responsible for queue 0,consumer B be responsible for queue 1 Message consumption in , In this way, parallel consumption can be achieved , Greatly improved performance
topic
Now all messages are persisted to Broker In the file of , Can be consumer The consumption , But in fact, some consumer May only be interested in a certain type of message , For example, I'm only interested in order messages , And not interested in the message of user registration class , So the current design is obviously unreasonable , Therefore, the message needs to be further subdivided , We put The message set of the same business type is called Topic. In this way, consumers can only subscribe to what they are interested in Topic Consumption , So it's not hard to understand consumeQueue Is aimed at Topic In terms of the ,producer When sending a message, you will specify the of the message Topic, The news arrived Broker It will be sent to Topic Corresponding consumeQueue, In this way, consumers can only consume the news they are interested in
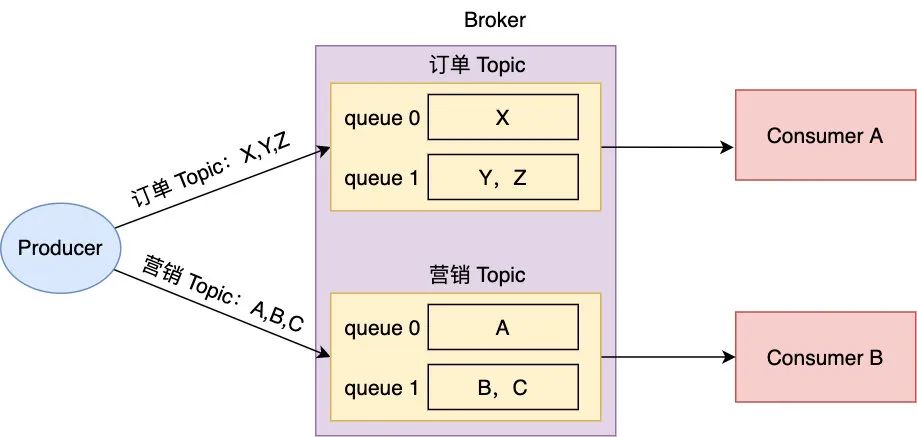
tag
Divide messages into... According to business types Topic The granularity is still a little big , Take the order message as an example , There are many states for orders , such as Order creation , Order closed , Order closed etc. , Some consumers may only be interested in certain order status , So sometimes we need to further study a certain Topic Classify the messages under , We call these categories tag, For example, order messages can be further divided into Order creation , Order closed , Order closed etc. tag

producer When sending a message, it will specify topic and tag,Broker Will also put topic, tag Persist to file , that consumer You can only subscribe to what it is interested in topic + tag The news , Now comes the question ,consumer When I came to pull the news ,Broker Why only to consumer according to topic + tag Subscribe to the news
Remember the message persistence mentioned above to commitlog Write after consumeQueue Information about

It mainly writes three fields , The last field is tag Of hashcode, In this case, because consumer When I pull news, I will put topic,tag issue Broker ,Broker You can start with tag Of hashcode Let's compare and see if this message meets the conditions , If you don't skip, continue to take it back , If it is from commitlog Get the message and send it to consumer, One might ask why the deposit is tag hashcode instead of tag, There are two main reasons
hashcode Is an integer , Integer comparison is faster
To ensure that this field has a fixed byte size (hashcode by int type , Fixed for 4 Bytes ), So every time you write consumeQueue The three fields of are fixed 20 byte , You can use the characteristics of the array to quickly locate the position of the message progress in the file , If you use tag Words , because tag Is string , It's getting longer , There is no guarantee of a fixed byte size
So far, let's briefly summarize the sending of messages , Storage and message flow

First producer send out topic,queueId,message To Broker in ,Broker Persist the message in the form of sequential writing to commitlog in , there queueId yes Topic Specified in the consumeQueue 0,consumeQueue 1,consumeQueue …, Generally, the corresponding queue is polled and written through load balancing , For example, the current message is written consumeQueue 0, The next one is written to consumeQueue 1,…, Keep cycling
After persistence, you can know that the message is in commitlog The offset in the file and the size of the message body , If consumer Specified subscription topic and tag, And figure out tag hashCode, In this way, the three can be written in order queueId Corresponding consumeQueue in
Consumer consumption : every last consumeQueue Can find the news progress of each consumer (consumeOffset), Based on this, we can quickly locate the consumeQueue File location of , Take out commitlog offset,size,tag hashcode These three values , Then first according to tag hashcode To filter messages , If it matches, then according to commitlog offset,size These two elements go to commitlog To find the corresponding message and then send it to the consumer
Be careful : all Topic All messages are written to the same commitlog file ( Not every one of them Topic Corresponding to one commitlog file ), Then the message will be written according to topic,queueId find Topic Where consumeQueue Write again
We need to pay attention to our Broker Is to be set to high performance (10 w QPS) There are two bottlenecks in the above steps
producer Send a message to persistence commitlog File performance issues . Let's take a look at the disk brushing process first
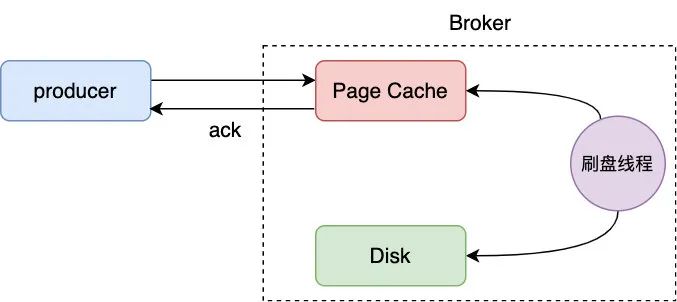
Such as graphic ,Broker After receiving the message, first write the message to the kernel buffer Of page cache in , Finally, the message will be swiped , So the message is page cache return ack, Or brush the disk and then return , It depends on the importance of your message , If it's a message like a log , It doesn't matter if you lose it , In this case, you can obviously choose to write page cache I'll be right back ,OS Will choose the machine to brush it , This way of brushing the disc is called Asynchronous brush set , This is also the disk brushing method selected in most business scenarios , This way is actually safe enough , Even if the JVM Hang up , because page cache By OS Managed ,OS It can also ensure the success of brushing the disc , Unless Broker Machine down . Of course, for financial scenarios with high security such as transfer , We may still have to get the news from page cache Brush the disc and then return to ack, This way we call it Synchronous brush set , Obviously, this approach will greatly reduce the performance , Use carefully
consumer The performance problem of pulling messages
Obviously, this is not a problem , Mentioned above , Whether it's commitlog still consumeQueue file , All exist slowly page cache in , So directly from page cache Just read the message , Because it is a memory based operation , There is no bottleneck , Of course, this is based on the premise that the consumption progress is similar to the production progress , If a consumer specifies to start consuming from a certain progress , And this progress corresponds to commitlog The file is not in page cache in , That will trigger the disk IO
Broker High availability
We are all based on a Broker To discuss , There is obviously a problem ,Broker If you hang up , Depending on it producer,consumer Don't you have a hiccup , therefore broker High availability is a must , Generally, master-slave mode is adopted to realize broker High availability

Such as graphic :Producer Send a message to Lord Broker , then consumer From the main Broker Lila news , and from Broker From the Lord Broker Sync message , In this case, once the Lord Broker It's down. ,consumer It can be downloaded from Broker Lila news , At the same time RocketMQ 4.5 in the future , Introduce a kind of dledger Pattern , This mode requires one master and many slaves ( At least 3 Nodes ), So if the Lord Broker After downtime , The other ones are from Broker Will be based on Raft The agreement elects a master Broker,Producer You can send a message to the newly elected master node
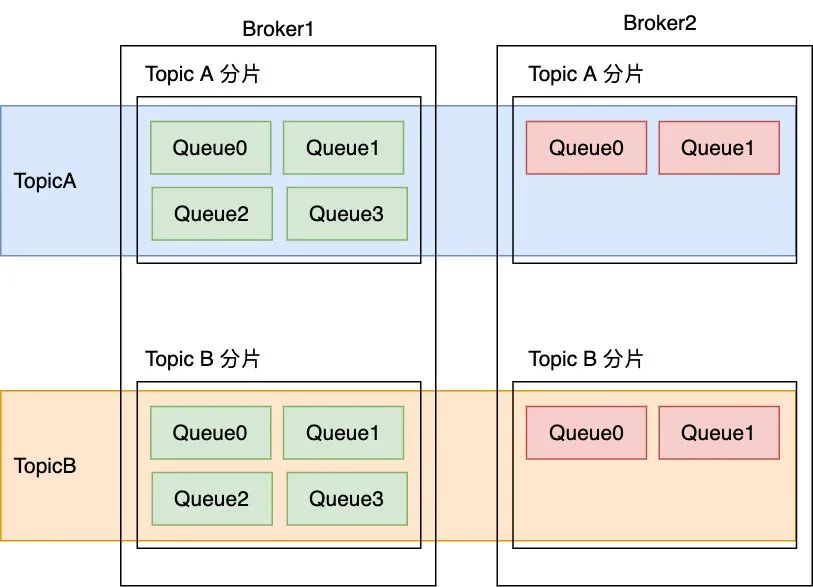
If QPS Very high, only one Lord Broker There are also performance bottlenecks , Therefore, the production generally adopts the form of multiple owners , As shown in the figure below

In this case Producer Messages can be sent to multiple servers with load balancing Broker On , The load capacity of the system is improved , It's not hard to see that this means Topic Is distributed storage in multiple Broker Upper , and Topic At every Broker The storage on is in multiple consumeQueue In the form of , This greatly improves Topic Horizontal expansion and concurrent execution ability of the system
nameserver
So far, our design seems good , Through a series of designs, let Broker It meets the requirements of high performance , High expansion requirements , But we seem to have overlooked a problem ,Producer,Consumer How to communicate with Broker Communication , One way is to Producer,Consumer Write down what you want to communicate Broker ip Address , It's possible , But doing so will obviously have a big problem , Configuration is rigid , Expandability of , Consider the following scenarios
If you expand ( newly added Broker),producer and consumer Is it necessary to follow the new Broker ip Address
Every time I add Topic You have to specify where Broker Storage , We know producer Sending a message ,consumer When subscribing to messages, you should specify the corresponding Topic , That means every time you add Topic You need to be in producer,consumer Make corresponding changes ( Record topic -> broker Address )
If broker It's down. ,producer and consumer It needs to be removed from the configuration , That means producer,consumer Need to be related to brokers Communicate through the heartbeat to know whether it is alive or not , This undoubtedly increases the complexity of the design
Under reference dubbo This kind of RPC frame , You will find that there will basically be a new one similar to Zookeeper In this way Registry Center The middle tier ( It is generally called nameserver), as follows

The main principles are as follows :
To ensure high availability , commonly nameserver In the form of clusters ( At least two. ),Broker After startup, both the master and slave will send messages to each nameserver register , What are the registration information , think about it producer To send a message to broker What information do you need to know , First send a message to specify Topic, Then specify Topic Where broker, And then you know Topic stay Broker Number of queues in ( Messages can be sent to these servers with load balancing in this way queue in ), therefore broker towards nameserver The registration information should include the following information
")
In this case producer and consumer You can communicate with nameserver Establish a long connection to schedule ( Like every other 30 s) Pull these routing information to update to the local network , send out / When consuming messages, you can send them according to these routing information / consumption
Then add one nameserver What are the advantages compared with the original scheme , It is obvious that :producer/consumer With a specific broker Decoupled , It greatly improves the scalability of the overall architecture :
producer/consumer All routing information can pass through nameserver obtain , For example, now we are going to brokers Let's go ahead and create a new one Topic, that brokers Will synchronize this information to nameserver, and producer/consumer Will go regularly nameserver Pull these routing information and update it to the local network , The automation of routing information configuration is achieved
Similarly, if some broker It's down. , because broker Will regularly report the heartbeat to nameserver To inform its survival status , once nameserver Detected broker It doesn't work ,producer/consumer It can also get its failure information , So as to eliminate it in the local route
You can see that by adding a layer nameserver,producer/consumer The routing information is configured automatically , No more manual operation , The overall structure is very reasonable
summary
The above is what we want to elaborate RocketMQ Design concept of , Basically covers the introduction of important concepts , Let's briefly review :
Firstly, according to the business scenario, we propose RocketMQ The three goals of design : Message persistence , High performance , High availability , without doubt broker The design of is the key to achieve these three goals , For message persistence , We designed commitlog file , The high performance of file writing is guaranteed by sequential writing , But if every time producer Write a message or consumer Read messages are read and written from files , Because it involves disk IO Obviously, there will be a big problem with performance , So we learned that the operating system will first load the file into memory when reading and writing files page cache in . For traditional files IO, because page cache In kernel space , It also needs to be copied into user space to be used by the process ( alike , To write a message, you also need to write the message into the user space buffer, Copy to In kernel space page cache), So we used mmap To avoid this copy , In this case producer To send a message, just write the message to page cache Then brush the disk asynchronously , and consumer As long as we keep up with the news producer Progress of message generation , You can directly from page cache Read messages for consumption , therefore producer And consumer Can be directly from page cache Read and write messages in , It greatly improves the reading and writing performance of messages , So how to guarantee consumer Spend fast enough to keep up with producer The speed at which messages are generated , obviously , Let the message be distributed , Slice storage is a general scheme , In this case, by adding consumer To achieve the purpose of concurrent consumption messages
Last , To avoid creating Topic perhaps broker Downtime has to be modified producer/consumer Configuration on , We introduced nameserver, Realize the automatic discovery function of service .
Be careful with other RPC After the horizontal comparison of the frame , You will find these RPC The ideas used in the framework are actually very similar , For example, data is stored in pieces to improve the horizontal expansion and concurrent execution ability of data storage , Use zookeeper,nameserver Wait for the registration center to achieve the purpose of service registration and automatic discovery , So master these ideas , Let's observe, study or design RPC Can achieve twice the result with half the effort
·············· END ··············
边栏推荐
- 首次曝光!唯一全域最高等级背后的阿里云云原生安全全景图
- 唐人街徒步:在异国情调的纽约感受浓厚的中式气息
- What should I do if a serious bug occurs within the scope of my own test and I am about to go online?
- Hanyuan hi tech 1-way uncompressed 4k-dvi optical transceiver 4K HD uncompressed DVI to optical fiber 4k-dvi HD video optical transceiver
- LM05丨曾经的VIX(二代产品)
- New project, how to ensure the coverage of the test?
- C#部分——值类型和引用类型
- Principle analysis of three methods for exchanging two numbers
- 64 channel PCM telephone optical transceiver 64 channel telephone +2-channel 100M Ethernet telephone optical transceiver 64 channel telephone PCM voice optical transceiver
- 20000 words + 30 pictures | MySQL log: what is the use of undo log, redo log and binlog?
猜你喜欢

2-optical-2-electric cascaded optical fiber transceiver Gigabit 2-optical-2-electric optical fiber transceiver Mini embedded industrial mine intrinsic safety optical fiber transceiver

首次曝光!唯一全域最高等级背后的阿里云云原生安全全景图

Cloud native essay deep understanding of ingress

"Developer talk" nail connector +oa approval to realize digitalization of school students' leave and work scenes

Broadcast level E1 to aes-ebu audio codec E1 to stereo audio XLR codec

User behavior modeling

Germancreditdata of dataset: a detailed introduction to the introduction, download and use of germancreditdata dataset
Dataset之GermanCreditData:GermanCreditData数据集的简介、下载、使用方法之详细攻略

16 channel HD-SDI optical transceiver multi channel HD-SDI HD video optical transceiver 16 channel 3g-sdi HD audio video optical transceiver

What should testers do if the requirements need to be changed when the project is half tested?
随机推荐
【深入理解TcaplusDB技术】单据受理之事务执行
「开发者说」钉钉连接器+OA审批实现学校学生假勤场景数字化
Architecture design methods in technical practice
Qunhui 10 Gigabit network configuration and test
R语言使用MASS包的polr函数构建有序多分类logistic回归模型、使用summary函数获取模型汇总统计信息
What is the version of version 1.54 when connecting to Oracle?
Solve "thread 1:" -[*.collectionnormalcellview isselected]: unrecognized selector sent to instance 0x7F "
Androd Gradle模块依赖替换如何使用
What should I do if a serious bug occurs within the scope of my own test and I am about to go online?
What are the criteria for judging the end of the test?
Ablebits Ultimate Suite for Excel
The GLM function of R language uses frequency data to build a binary logistic regression model. The input data for analysis is frequency data, which is transformed into normal sample data (split and s
Esp32-c3 introductory tutorial problems ⑧ - blufi_ example. c:244: undefined reference to `esp_ ble_ gap_ start_ advertising
Esp32-c3 introductory tutorial problem ⑦ - fatal error: ESP_ Bt.h: no such file or directory ESP not found_ bt.h
RestCloud ETL解决shell脚本参数化
R language uses the polR function of mass package to build an ordered multi classification logistic regression model, and uses exp function and coef function to obtain the corresponding odds ratio of
涉及第三方支付接口,怎么测?
Hanyuan hi tech 1-way uncompressed 4k-dvi optical transceiver 4K HD uncompressed DVI to optical fiber 4k-dvi HD video optical transceiver
Broadcast level E1 to aes-ebu audio codec E1 to stereo audio XLR codec
TUIKit 音视频低代码解决方案导航页