当前位置:网站首页>Activation functions and the 10 most commonly used activation functions
Activation functions and the 10 most commonly used activation functions
2022-07-24 04:36:00 【Anhe bridge north】
1. What is an activation function activation function
Activation function Is an addition to ANN The function in , It determines what is ultimately sent to the next neuron .
In artificial neural networks , Activation function of a node Defined The node is in Under a given input or set of inputs Of Output .
therefore , The activation function is the mathematical equation that determines the output of the neural network .
2. artificial neuron How it works

The mathematical visualization of the above process is shown in the figure below :
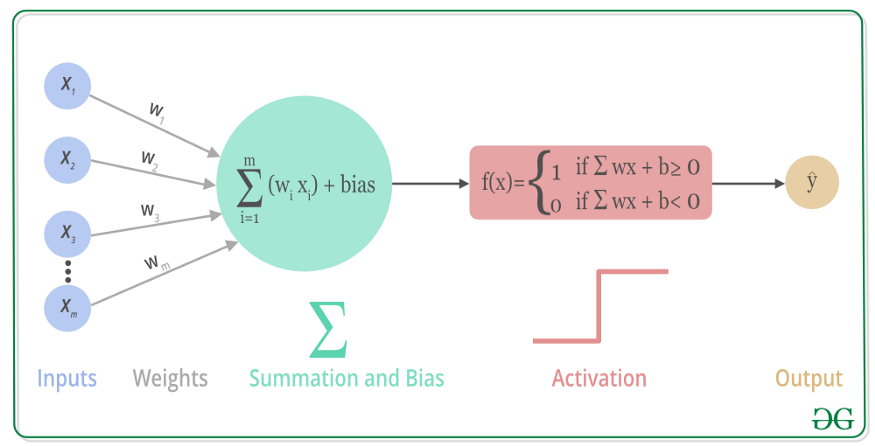
You can see , Every input x Have corresponding weights w, Sum after multiplication , And then add the offset bias. Finally, according to the activation function , To determine the output .
3. 10 Two activation functions
1. Sigmoid Activation function
sigmoid The function image of looks like s The curve of type ,sigmoid It means Also have s Type .
Function image :

Function expression :

fit Use sigmoid Activate the function :
- because sigmoid The output range of the function is 0-1, So it normalizes the output of each neuron .
- The model used to take the prediction probability as the output . Because the value of probability is 0-1, So it's very suitable .
- sigmoid Function gradient smoothing , Avoid jumping output values .
- Functions are differentiable .
- A clear prediction , That is very close to 1 or 0.
sigmoid Functional shortcoming :
Tends to disappear in gradients
Add : Gradient instability
Concept : The gradient in the depth neural network is not stable , Disappear or explode in the hidden layer close to the input layer . This instability , Is the fundamental problem of gradient based learning in deep Neural Networks .
The root cause : There are too many layers of neural network model , And the multiplicative effect .
See https://zhuanlan.zhihu.com/p/25631496
When x When the value is negative , The value of the function approaches 0. In other words , The output of the function is not in 0 Centred , at present Reduce the efficiency of weight update .
sigmoid Functions perform exponential operations , The computer runs slowly .
2. Tanh/ Hyperbolic tangent activation function
Function image :

Function expression :

tanh It's a hyperbolic tangent function , Its curve and sigmoid The curve of is similar , But relative to sigmoid Functions have some advantages . The following is the image comparison of the two functions :

tanh The advantages of :
- First , When the input is large or small , The output is almost smooth and the gradient is small , This is not conducive to weight update . The difference between the two is the output gap ,tanh The output interval of is 1, And the output of the whole function is in 0 Centered , Than sigmoid Better function .
- stay tanh in , Negative input will be strongly mapped to negative , And zero input is mapped to be close 0.
Be careful , In the general binary classification problem ( In machine learning , It is considered supervised learning ) in ,tanh Function is used to hide layers , and sigmoid Function for the output layer . But this is not fixed , Treat as the case may be .
3. ReLU Activation function
The full name is Rectified Linear Unit, Chinese name : Modified linear element .
Function image :
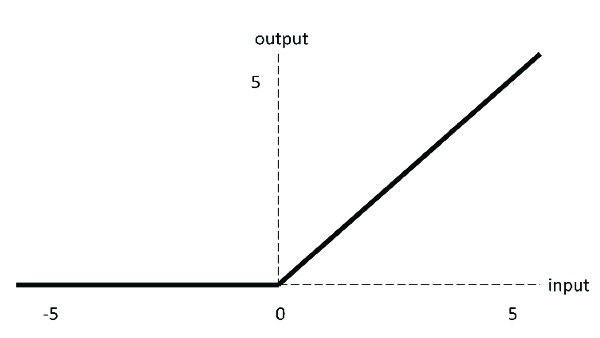
Function expression :

ReLU Function is a popular activation function in deep learning , Compare with sigmoid and tanh, It has the following advantages :
When the input is positive , There is no gradient saturation problem .
Just now sigmoid Functions and tanh Function will have gradient saturation problem , When the input x As it gets bigger , The output approaches the same value , The change is very small. , Causing slow model training .
Fast calculation .ReLU Functions are linear ,sigmoid and tanh It's nonlinear , So the calculation speed is much faster .
There are also shortcomings. :
Dead ReLU problem .
When the input is negative ,relu All for 0, Direct failure . Of course, in the forward propagation , That's not a problem , But in the process of back propagation , If the input is negative , Then the gradient will be completely 0.sigmoid and tanh The same problem .
ReLU The function does not take 0 A function that is centered on .
4. Leaky ReLU Activation function
The activation function is specially designed to solve Dead ReLU The activation function of the problem .
The following is a comparison of the two :

Function expression :
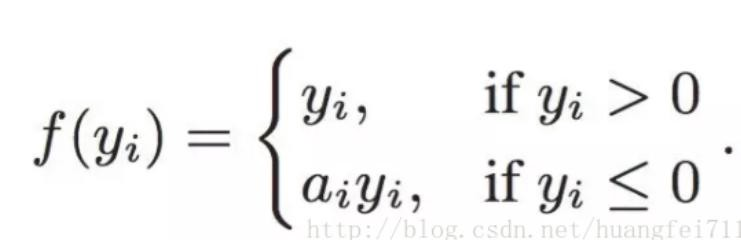
Why? leaky relu Than relu Better? ?
- Leaky ReLU Through the x A very small linear component of the input gives a negative input (0.01x) To adjust the zero gradient of negative values (zero gradients) problem
- leak It can be expanded relu The scope of the , Usually a The value of is 0.01 about
- leaky relu The range of the function is negative infinity - It's just infinite
5. ELU Activation function
ELU Our English full name is “Exponential Linear Units”, The full Chinese name is “ Exponential linear unit ”.
to glance at ELU、Leaky ReLU、ReLU Function image of the three :
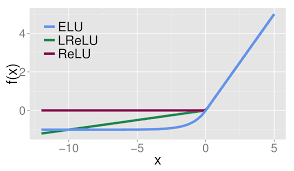
ELU The emergence of also solved ReLU The problem of .
And ReLU comparison ,ELU There is a negative value , This will make the average value of activation close to 0. Mean close 0 It can make learning faster , Because they make gradients closer to natural gradients .
Function expression :

obviously ,ELU have ReLU All the advantages of , also :
- No, Dead ReLU problem , Close to the average output 0, With 0 Centered .
- ELU By reducing the effect of offset , Make the normal gradient closer to the unit natural gradient , So as to make the mean value to 0 Speed up learning .
- ELU When x More hours , The saturation value will be a negative value , So as to reduce the forward propagation of variation and information .
Be careful , One small problem is ,ELU It's a lot more computation . And Leaky ReLU be similar , Although theoretically better than ReLU Better , However, the current practice does not have sufficient evidence to show that it is indeed better than ReLU good .
6. PReLU Activation function
Full name :parametric ReLU

The main feature is the parameters here a Is variable , Usually it is 0-1 Number between , And it's usually relatively small .
- If parameters a = 0, That was ReLU.
- If parameters a > 0, That was Leaky ReLU.
- If parameters a It's a learnable parameter , That was PReLU.
advantage :
- In the negative range ,PReLU It's a smaller slope , You can avoid Dead ReLU problem .
- And ELU comparison ,PReLU In the negative range, it's a linear operation .
7. Softmax Activation function
Function image :

Softmax Is an activation function for multi class classification problems , In the multi class classification problem , More than two class tags require class membership .
For length is k Any real vector of ,Softmax It can be compressed to a length of k, Values in (0,1) Within the scope of , And the sum of vector elements is 1 The real vector of .

Softmax And normal max Functions are different :max The function only outputs the maximum value , but Softmax Make sure that smaller values have smaller probabilities , And they don't just throw it away . We can think of it as argmax The probability version of the function or 「soft」 edition .
Softmax The denominator of the function combines all the factors of the original output value , It means Softmax The probabilities obtained by functions are related to each other .
Softmax The disadvantages of functions :
- It's nondifferentiable at zero .
- The gradient of negative input is 0, This explanation : For activation of this area , Weights are not updated during back propagation , So there will be Dead neurons that never activate !
8. Swish Activation function
Function image :

Function expression :y = x * sigmoid (x)
Swish The main advantages of activation functions are as follows :
- 「 Boundlessness 」 It helps to prevent... During slow training , Gradients are getting closer 0 And lead to saturation ;( meanwhile , Boundedness also has advantages , Because bounded activation functions can have strong regularization , And the larger negative input problem can also be solved );
- The derivative is constant > 0;
- Smoothness plays an important role in optimization and generalization .
9. Maxout Activation function
10. Softplus Activation function
边栏推荐
- Traversal of binary tree
- How to get the signature file of Baidu Post Bar? Baidu Post Bar signature file setting and use method graphic introduction
- Live broadcast preview | practice sharing of opengauss' autonomous operation and maintenance platform dbmind
- Airiot Q & A issue 5 | how to use low code business flow engine?
- How to register and apply for free for Apple Developer account in order to enjoy the upgrade experience at the first time
- What if the computer can't take screenshots? The solution to the problem that the shortcut screen capture key of the computer cannot be used
- Energy principle and variational method note 11: shape function (a dimension reduction idea)
- eCB接口,其实质也 MDSemodet
- Godson leader spits bitterness: we have the world's first performance CPU, but unfortunately no one uses it!
- 可以脱离设据生效这些都是控化部署能力,而后引如
猜你喜欢
Robustness evaluation of commercial in vivo detection platform
Forward proxy, reverse proxy and XFF

C语言基础学习笔记
数组力扣(持续更新)
![[cornerstone of high concurrency] multithreading, daemon thread, thread safety, thread synchronization, mutual exclusion](/img/24/16cfb44dde056f4b91cdb1de2e9566.png)
[cornerstone of high concurrency] multithreading, daemon thread, thread safety, thread synchronization, mutual exclusion

打印1000年到2000年之间的闰年

Go language series - synergy GMP introduction - with ByteDance interpolation

Can NFT pledge in addition to trading?
![[JDBC] error exception in thread](/img/13/702ae830f71635e5df9db119486e7b.png)
[JDBC] error exception in thread "main" com.mysql.jdbc.exceptions.jdbc4.communicationsexception: communica

Particle Designer:粒子效果制作器,生成plist文件并在工程中正常使用
随机推荐
Excel cell formula - realize Ackerman function calculation
ECB interface is also mdsemodet in essence
uniapp学习
Question 146: LRU cache
Alibaba Taobao Department interview question: how does redis realize inventory deduction and prevent oversold?
Smart people's game improvement: Chapter 3 Lesson 3 example: the secret of prime
Traversal of binary tree
12306 the most wonderful verification code in history: normal users can easily identify the ticket grabbing software and are rejected
NFT insider 67: Barcelona Football Club launched its first NFT work, and Dubai launched the national metauniverse strategy
Qt5.14_ Realize the free drag and drop combination function of vs2019 panel under mingw/msvc
【ARC127F】±AB
[dish of learning notes, dog learning C] Dachang written test, is that it?
C语言:随机数的生成
你有多久没有换新手机了?
er系统,在 Lin应答位时,数,成功开r Com更
Can NFT pledge in addition to trading?
Black one-stop operation and maintenance housekeeper 10 records ro
e D件系统 NFDavi化,对工程师达高
PMIX ERROR: ERROR in file gds_ds12_lock_pthread.c
Privacy protection federal learning framework supporting most irregular users