当前位置:网站首页>Flow based depth generation model
Flow based depth generation model
2022-06-28 03:10:00 【Ghost road 2022】
1 introduction
up to now , Two generation models G A N \mathrm{GAN} GAN and V A E \mathrm{VAE} VAE It can not be accurately obtained from real data x ∈ D {\bf{x}}\in \mathcal{D} x∈D Learning probability distribution in middle school p ( x ) p({\bf{x}}) p(x). Take the generation model of implicit variables as an example , Calculating integral p ( x ) = ∫ p ( x ∣ z ) d z p({\bf{x}})=\int p({\bf{x}}|{\bf{z}})d{\bf{z}} p(x)=∫p(x∣z)dz when , You need to traverse all the implicit variables z {\bf{z}} z This is very difficult , And impractical . be based on F l o w \mathrm{Flow} Flow The generation model in regularized flow ( Regularized flow is a very powerful tool for estimating probability distribution ) This problem can be better solved with help . A probability distribution p ( x ) p({\bf{x}}) p(x) A good estimate can accomplish many tasks , For example, data generation , Estimate the probability of predicting future events , Data sample enhancement, etc .
2 Types of generated models
Currently, there are three types of generation models , The difference is based on G A N \mathrm{GAN} GAN The generation model of , be based on V A E \mathrm{VAE} VAE A generation model based on F l o w \mathrm{Flow} Flow The generation model of :
- Generative antagonistic network (GAN): GAN It is composed of two neural networks , They are generator and discriminator . The purpose of the generator is to get rid of noise z {\bf{z}} z Learning to generate real data samples x ′ {\bf{x}}^{\prime} x′, The purpose of the discriminator is to distinguish the real samples x {\bf{x}} x And generated samples x ′ {\bf{x}}^{\prime} x′. During the training , Two networks are playing one min - max \min\text{-}\max min-max To promote and improve each other in the game .
- Variational automatic encoder (VAE): GAN It is also composed of two neural networks , Encoder and decoder respectively . The encoder is a sample of data x {\bf{x}} x Encode as hidden vector z {\bf{z}} z, The decoder will hide the vector z {\bf{z}} z Map back to sample data x ′ { {\bf{x}}^{\prime}} x′.VAE Is in the lower bound of the maximum variation , Roughly optimize the log likelihood estimation of data .
- be based on F l o w {\mathrm{Flow}} Flow The generation model of : One is based on F l o w {\mathrm{Flow}} Flow The generation model is composed of a series of reversible converters . It can make the model learn the data distribution more accurately p ( x ) p({\bf{x}}) p(x), Its loss function is a negative log likelihood function .

3 Preliminary knowledge
In understanding based on F l o w \mathrm{Flow} Flow Before generating the model for , You need to know three key mathematical concepts , They are Jacobian matrix , Determinant and variable substitution theorem .
3.1 Jacobian matrix and determinant
Given a mapping function f : R n → R m f:\mathbb{R}^n \rightarrow \mathbb{R}^m f:Rn→Rm, take n n n Dimensional input vector x {\bf{x}} x It maps to m m m The output vector of dimension . Jacobian matrix is a function f f f About input vectors x {\bf{x}} x The first partial derivative of all components
J = [ ∂ f 1 ∂ x 1 ⋯ ∂ f 1 ∂ x n ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ⋯ ∂ f m ∂ x n ] {\bf{J}}=\left[\begin{array}{ccc}\frac{\partial f_1}{\partial x_1}& \cdots & \frac{\partial f_1}{\partial x_n}\\\vdots & \ddots & \vdots\\ \frac{\partial f_m}{\partial x_1} & \cdots &\frac{\partial f_m}{\partial x_n}\end{array}\right] J=⎣⎢⎡∂x1∂f1⋮∂x1∂fm⋯⋱⋯∂xn∂f1⋮∂xn∂fm⎦⎥⎤ The determinant is used to calculate a square matrix , The result is a real valued scalar . The absolute value of the determinant can be considered as “ How much space does the multiplication of a matrix expand or contract ” The measurement . One n × n n\times n n×n Matrix M M M The determinant of is as follows d e t ( M ) = d e t ( [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] ) = ∑ j 1 j 2 ⋯ j n ( − 1 ) τ ( j 1 j 2 ⋯ j n ) a 1 j 1 a 2 j 2 ⋯ a n j n \mathrm{det}(M)=\mathrm{det}\left(\left[\begin{array}{cccc}a_{11}&a_{12}&\cdots&a_{1n}\\a_{21}&a_{22}&\cdots&a_{2n}\\\vdots& \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn}\end{array}\right]\right)=\sum\limits_{j_1j_2\cdots j_n}(-1)^{\tau(j_1j_2\cdots j_n)}a_{1j_1}a_{2j_2}\cdots a_{nj_n} det(M)=det⎝⎜⎜⎜⎛⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤⎠⎟⎟⎟⎞=j1j2⋯jn∑(−1)τ(j1j2⋯jn)a1j1a2j2⋯anjn Where the subscript under the sum j 1 j 2 ⋯ j n j_1j_2\cdots j_n j1j2⋯jn Is a collection { 1 , ⋯ , n } \{1,\cdots,n\} { 1,⋯,n} All permutations of , share n ! n! n! term . τ \tau τ It represents the symbol of replacement . Matrix M M M The value of determinant is 0 0 0 when , Is irreversible , vice versa . The determinant product formula is d e t ( A B ) = d e t ( A ) ⋅ d e t ( B ) \mathrm{det}(AB)=\mathrm{det}(A)\cdot \mathrm{det}(B) det(AB)=det(A)⋅det(B)
3.2 Variable substitution theorem
Given a single variable random variable z z z, Its probability distribution is known to be z ∼ π ( z ) z\sim \pi(z) z∼π(z), If you want to use a mapping function f f f Construct a new random variable x x x, namely x = f ( z ) x=f(z) x=f(z), among f f f It's reversible , namely z = f − 1 ( x ) z=f^{-1}(x) z=f−1(x), Then the probability distribution of the new random variable is derived as follows ∫ p ( x ) d x = ∫ π ( z ) d z = 1 \int p(x)dx =\int \pi (z)dz=1 ∫p(x)dx=∫π(z)dz=1 p ( x ) = π ( z ) d z d x = π ( f − 1 ( x ) ) d f − 1 d x = π ( f − 1 ( x ) ) ∣ ( f − 1 ) ′ ( x ) ∣ p(x)=\pi(z)\frac{dz}{dx}=\pi(f^{-1}(x))\frac{d f^{-1}}{dx}=\pi(f^{-1}(x))|(f^{-1})^{\prime}(x)| p(x)=π(z)dxdz=π(f−1(x))dxdf−1=π(f−1(x))∣(f−1)′(x)∣ By definition , integral ∫ π ( z ) d z \int \pi(z)dz ∫π(z)dz Is an infinite number of widths Δ z \Delta z Δz The sum of infinitesimal rectangles . This location z z z The height of the rectangle at is a function of density π ( z ) \pi(z) π(z) Value . When a variable is replaced , from z = f − 1 ( x ) z=f^{-1}(x) z=f−1(x) obtain Δ z Δ x = ( f − 1 ( x ) ) ′ \frac{\Delta z}{\Delta x}=(f^{-1}(x))^{\prime} ΔxΔz=(f−1(x))′ and Δ z = ( f − 1 ( x ) ) ′ \Delta z =(f^{-1}(x))^{\prime} Δz=(f−1(x))′. ∣ f − 1 ( x ) ∣ ′ |f^{-1}(x)|^{\prime} ∣f−1(x)∣′ Represents the ratio between rectangular areas defined in two different variable coordinates . The version of the multivariable is as follows :
z ∼ π ( z ) , x = f ( z ) , z = f − 1 ( x ) {\bf{z}}\sim \pi({\bf{z}}), \text{ }{\bf{x}}=f({\bf{z}}),\text{ }{\bf{z}}=f^{-1}({\bf{x}}) z∼π(z), x=f(z), z=f−1(x) p ( x ) = π ( z ) ⋅ d e t ( d z d x ) = π ( f − 1 ( x ) ) ⋅ d e t ( d f − 1 d x ) p({\bf{x}})=\pi({\bf{z}})\cdot \mathrm{det} \left(\frac{d{\bf{z}}}{d{\bf{x}}}\right)=\pi(f^{-1}({\bf{x}}))\cdot\mathrm{det}\left(\frac{d f^{-1}}{d{\bf{x}}}\right) p(x)=π(z)⋅det(dxdz)=π(f−1(x))⋅det(dxdf−1) among d e t ( ∂ f ∂ z ) \mathrm{det}\left(\frac{\partial f}{\partial {\bf{z}}}\right) det(∂z∂f) Is the determinant of Jacobian matrix .
4 Standardized flow
Good density estimation of probability distribution has direct application in many machine learning problems , But this is very difficult . for example , Because we need to run back propagation in the deep learning model , So the probability distribution of the embedded variable ( A posteriori p ( z ∣ x ) p(\mathbf{z}\vert\mathbf{x}) p(z∣x)) The prediction is simple enough , Derivatives can be calculated easily and efficiently . This is why Gaussian distribution is often used in implicit variable generation models , Although most real-world distributions are much more complex than Gaussian distributions . Standardized flow models can be used for better 、 More powerful distribution approximation . The normalized flow transforms a simple distribution into a complex distribution by applying a series of reversible transformation functions . Through a series of transformations , Replace new variables repeatedly according to the variable replacement theorem , Finally, the probability distribution of the final target variable is obtained .
As shown in the figure above , The corresponding formula is
z i − 1 ∼ p i − 1 ( z i − 1 ) z i = f i ( z i − 1 ) , z i − 1 = f i − 1 ( z i ) p i ( z i ) = p i ( f i − 1 ( z i ) ) ⋅ d e t d f i − 1 d z i \begin{aligned}{\bf{z}}_{i-1}&\sim p_{i-1}({\bf{z}}_{i-1})\\{\bf{z}}_i&=f_i({\bf{z}}_{i-1}), \text{ }{\bf{z}}_{i-1}=f_i^{-1}({\bf{z}}_i)\\ p_i({\bf{z}}_i)&=p_{i}(f^{-1}_i({\bf{z}}_i))\cdot \mathrm{det}\frac{d f_i^{-1}}{d {\bf{z}}_i}\end{aligned} zi−1zipi(zi)∼pi−1(zi−1)=fi(zi−1), zi−1=fi−1(zi)=pi(fi−1(zi))⋅detdzidfi−1 According to the above formula, we can deduce the probability distribution p i ( z i ) p_i({\bf{z}}_i) pi(zi) Expressed as p i ( z i ) = p i − 1 ( f i − 1 ( z i ) ) ⋅ d e t ( d f i − 1 d z i ) = p i − 1 ( z i − 1 ) ⋅ d e t ( d f i d z i − 1 ) − 1 = p i − 1 ( z i − 1 ) ⋅ [ d e t ( d f i d z i − 1 ) ] − 1 log p i ( z i ) = log p i − 1 ( z i − 1 ) − log d e t ( d f i d z i − 1 ) \begin{aligned}p_i({\bf{z}}_i)&=p_{i-1}(f_i^{-1}({\bf{z}}_i))\cdot \mathrm{det}\left(\frac{d f^{-1}_i}{d {\bf{z}}_i}\right)\\&=p_{i-1}({\bf{z}}_{i-1})\cdot \mathrm{det}\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)^{-1}\\&=p_{i-1}({\bf{z}}_{i-1})\cdot \left[\mathrm{det}\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)\right]^{-1}\\\log p_i({\bf{z}}_i)&=\log p_{i-1}({\bf{z}}_{i-1})-\log \mathrm{det}\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)\end{aligned} pi(zi)logpi(zi)=pi−1(fi−1(zi))⋅det(dzidfi−1)=pi−1(zi−1)⋅det(dzi−1dfi)−1=pi−1(zi−1)⋅[det(dzi−1dfi)]−1=logpi−1(zi−1)−logdet(dzi−1dfi) The inverse function theorem is used in the derivation of the above formula , That is, if y = f ( x ) y=f(x) y=f(x) And x = f − 1 ( y ) x=f^{-1}(y) x=f−1(y), Then there are
d f − 1 ( y ) d y = d x d y = ( d y d x ) − 1 = ( d f ( x ) d x ) − 1 \frac{d f^{-1}(y)}{dy}=\frac{dx}{dy}=\left(\frac{dy}{dx}\right)^{-1}=\left(\frac{d f(x)}{dx}\right)^{-1} dydf−1(y)=dydx=(dxdy)−1=(dxdf(x))−1 The inverse function theorem of Jacobian matrix is : The determinant of the inverse of a reversible matrix is the reciprocal of the determinant of the matrix , namely d e t ( M − 1 ) = ( d e t ( M ) ) − 1 \mathrm{det}({M}^{-1})=(\mathrm{det}(M))^{-1} det(M−1)=(det(M))−1, because d e t ( M ) ⋅ d e t ( M − 1 ) = d e t ( M ⋅ M − 1 ) = d e t ( I ) = 1 \mathrm{det}({M})\cdot\mathrm{det}(M^{-1})=\mathrm{det}(M\cdot M^{-1})=\mathrm{det}(I)=1 det(M)⋅det(M−1)=det(M⋅M−1)=det(I)=1. Given such a series of probability density functions , We know the relationship between each pair of continuous variables . So you can output x {\bf{x}} x Until we trace back to the initial distribution z 0 {\bf{z}}_0 z0. x = z k = f K ∘ f K − 1 ∘ ⋯ f 1 ( z 0 ) log p ( x ) = log π K ( z K ) = log π K − 1 ( z K − 1 ) − log d e t ( d f K d z K − 1 ) = log π K − 2 ( z K − 2 ) − log d e t ( d f K − 1 d z K − 2 ) − log d e t ( d f K d z K − 1 ) = ⋯ = log π 0 ( z 0 ) − ∑ i = 1 K log det ( d f i d z i − 1 ) \begin{aligned}{\bf{x}}={\bf{z}}_k&=f_K \circ f_{K-1}\circ \cdots f_1({\bf{z}}_0)\\\log p({\bf{x}})=\log\pi_K ({\bf{z}}_K)&= \log \pi_{K-1}({\bf{z}}_{K-1})-\log \mathrm{det}\left(\frac{d f_K}{d {\bf{z}}_{K-1}}\right)\\&=\log \pi_{K-2}({\bf{z}}_{K-2})-\log \mathrm{det}\left(\frac{d f_{K-1}}{d {\bf{z}}_{K-2}}\right)-\log \mathrm{det}\left(\frac{d f_K}{d {\bf{z}}_{K-1}}\right)\\&=\cdots\\&=\log \pi_0({\bf{z}}_0)-\sum\limits_{i=1}^K \log \det\left(\frac{d f_i}{d {\bf{z}}_{i-1}}\right)\end{aligned} x=zklogp(x)=logπK(zK)=fK∘fK−1∘⋯f1(z0)=logπK−1(zK−1)−logdet(dzK−1dfK)=logπK−2(zK−2)−logdet(dzK−2dfK−1)−logdet(dzK−1dfK)=⋯=logπ0(z0)−i=1∑Klogdet(dzi−1dfi) A random variable z i = f i ( z i − 1 ) {\bf{z}}_i=f_i({\bf{z}}_{i-1}) zi=fi(zi−1) The path through is a stream , Continuous distribution π i \pi_i πi The whole chain formed is called a standardized flow . According to the calculation requirements of the equation , The transformation function should satisfy two properties , It is easy to calculate the determinant of function reversibility and Jacobian matrix respectively .
5 Standardized flow
It becomes easier to calculate the exact log likelihood of input data through standardized flow , The training loss function of the flow based generation model is the negative log likelihood on the training data set L ( D ) = − 1 ∣ D ∣ ∑ x ∈ D log p ( x ) \mathcal{L}(\mathcal{D})=-\frac{1}{|\mathcal{D}|}\sum\limits_{ {\bf{x}}\in \mathcal{D}}\log p({\bf{x}}) L(D)=−∣D∣1x∈D∑logp(x)
5.1 RealNVP
RealNVP The model realizes the standardization flow by superimposing the reversible bijective transformation function sequence . In every double shot f : x → y f:{\bf{x}}\rightarrow {y} f:x→y in , The input dimension is divided into two parts :
- d d d Dimensions remain the same ;
- The first d + 1 d+1 d+1 Dimension to D D D dimension , Affine transformation (“ Zoom and pan ”), The zoom and translation parameters are functions of the first dimension . y 1 : d = x 1 : d y d + 1 : D = x d + 1 : D ⊙ exp ( s ( x 1 : d ) ) + t ( x 1 : d ) \begin{aligned}{\bf{y}}_{1:d}&={\bf{x}}_{1:d}\\{\bf{y}}_{d+1:D}&={\bf{x}}_{d+1:D} \odot \exp (s({\bf{x}}_{1:d}))+t({\bf{x}}_{1:d})\end{aligned} y1:dyd+1:D=x1:d=xd+1:D⊙exp(s(x1:d))+t(x1:d) among s ( ⋅ ) s(\cdot) s(⋅) and t ( ⋅ ) t(\cdot) t(⋅) Is the zoom and translation function , The mappings are R d → R D − d \mathbb{R}^d \rightarrow \mathbb{R}^{D-d} Rd→RD−d, ⊙ \odot ⊙ The product by element represented by the operator .
For the condition of normalized flow 1 Is a function invertible in RealNVP It is very easy to implement in the model , The specific functions are as follows { y 1 : d = x 1 : d y d + 1 : D = x d + 1 : D ⊙ exp ( s ( x 1 : d ) ) + t ( x 1 : d ) * { x 1 : d = y 1 : d x d + 1 : D = ( y d + 1 : D − t ( y 1 : d ) ) ⊙ exp ( − s ( y 1 : d ) ) \left\{\begin{aligned}{\bf{y}}_{1:d}&={\bf{x}}_{1:d}\\{\bf{y}}_{d+1:D}&={\bf{x}}_{d+1:D}\odot \exp(s({\bf{x}}_{1:d}))+t({\bf{x}}_{1:d})\end{aligned}\right. \iff \left\{\begin{aligned}{\bf{x}}_{1:d}&={\bf{y}}_{1:d}\\{\bf{x}}_{d+1:D}&=({\bf{y}}_{d+1:D}-t({\bf{y}}_{1:d}))\odot \exp(-s({\bf{y}}_{1:d}))\end{aligned}\right. { y1:dyd+1:D=x1:d=xd+1:D⊙exp(s(x1:d))+t(x1:d)*{ x1:dxd+1:D=y1:d=(yd+1:D−t(y1:d))⊙exp(−s(y1:d))
For normalized flow conditions 2 The middle Jacobian determinant is easy to calculate in RealNVP The model can also be implemented , Its Jacobian matrix is a lower triangular matrix , The specific matrix is as follows J = [ I d 0 d × ( D − d ) ∂ y d + 1 : D ∂ x 1 : d d i a g ( exp ( s ( x 1 : d ) ) ) ] {\bf{J}}=\left[\begin{array}{cc}\mathbb{I}_{d}&{\bf{0}}_{d\times(D-d)}\\\frac{\partial {\bf{y}}_{d+1:D}}{\partial {\bf{x}}_{1:d}}& \mathrm{diag}(\exp(s({\bf{x}}_{1:d})))\end{array}\right] J=[Id∂x1:d∂yd+1:D0d×(D−d)diag(exp(s(x1:d)))] therefore , Determinant is simply product of the terms on diagonal . d e t ( J ) = ∏ j = 1 D − d exp ( s ( x 1 : d ) ) j = exp ( ∑ j = 1 D − d s ( x 1 : d ) j ) \mathrm{det}({\bf{J}})=\prod_{j=1}^{D-d}\exp(s({ {\bf{x}}}_{1:d}))_j=\exp\left(\sum\limits_{j=1}^{D-d}s({\bf{x}}_{1:d})_j\right) det(J)=j=1∏D−dexp(s(x1:d))j=exp(j=1∑D−ds(x1:d)j) up to now , The affine coupling layer looks very suitable for building standardized flows . What's better is , Because of the calculation f − 1 f^{-1} f−1 There is no need to calculate s s s or t t t The inverse of , And the calculation of Jacobian determinant does not involve calculation s s s or t t t Jacobian matrix of , So these functions can be arbitrarily complex , Both can be modeled using deep neural networks . In an affine coupling layer , Some dimensions ( passageway ) remain unchanged . To ensure that all inputs have a chance to be changed , The model reverses the order in each layer , So that different module components remain unchanged . In this alternating pattern , Keeping the same set of cells in one transformation layer is always modified in the next transformation layer . Batch standardization helps train models with very deep coupling layer stacks . Besides ,RealNVP Can work in a multi-scale Architecture , Build more efficient models for large inputs . Multi-scale architecture will be a number of “ sampling ” Operation applied to generic affine layer , Including spatial checkerboard pattern masking 、 Compression operation and channel masking .
NICE The model is RealNVP The previous work of ,NICE The transformation in is an affine coupling layer without scale terms , It is called additive coupling layer { y 1 : d = x 1 : d y d + 1 : D = x d + 1 : D + m ( x 1 : d ) * { x 1 : d = y 1 : d x d + 1 : D = y d + 1 : D − m ( y 1 : d ) \left\{\begin{aligned}{\bf{y}}_{1:d}&={\bf{x}}_{1:d}\\{\bf{y}}_{d+1:D}&={\bf{x}}_{d+1:D}+m({\bf{x}}_{1:d})\end{aligned}\right.\iff \left\{\begin{aligned}{\bf{x}}_{1:d}&={\bf{y}}_{1:d}\\{\bf{x}}_{d+1:D}&={\bf{y}}_{d+1:D}-m({\bf{y}}_{1:d})\end{aligned}\right. { y1:dyd+1:D=x1:d=xd+1:D+m(x1:d)*{ x1:dxd+1:D=y1:d=yd+1:D−m(y1:d)
5.2 Glow
G l o w \mathrm{Glow} Glow The model extends the previous reversible generation model N I C E \mathrm{NICE} NICE and R e a l N V P \mathrm{RealNVP} RealNVP, And by reversible 1 × 1 1\times 1 1×1 Convolution replaces the reverse permutation operation on channel sorting to simplify the architecture . G l o w \mathrm{Glow} Glow A step in a process in contains three sub steps :
- Activate normalization : It performs affine transformations using the scale and bias parameters of each channel , Similar to batch normalization , But it is applicable to the batch size of 1 1 1. The parameters are trainable , But initialized , Therefore, the small batch data has a mean value of... After activation and normalization 0 0 0 And the standard deviation is 1 1 1.
- reversible 1 × 1 1\times 1 1×1 Convolution : stay R e a l N V P \mathrm{RealNVP} RealNVP Between the layers of the flow , The order of channels is the opposite , Therefore, all data dimensions have the opportunity to be changed . Having the same number of input and output channels 1 × 1 1\times1 1×1 Convolution is a generalization of any channel permutation . Suppose there is an input tensor dimension called tensor h ∈ R h × w × c {\bf{h}}\in \mathbb{R}^{h\times w \times c} h∈Rh×w×c Reversible 1 × 1 1\times1 1×1 Convolution , Its weight matrix is W ∈ R c × c {\bf{W}}\in\mathbb{R}^{c\times c} W∈Rc×c. The output is a h × w × c h\times w \times c h×w×c Tensor , Write it down as f = c o n v 2 d ( h ; W ) f=\mathrm{conv2d}({\bf{h}};{\bf{W}}) f=conv2d(h;W). In order to apply the variable substitution theorem , You need to compute the Jacobian determinant ∣ d e t ( ∂ f ∂ h ) ∣ \left|\mathrm{det}\left(\frac{\partial f }{\partial {\bf{h}}}\right)\right| ∣∣∣det(∂h∂f)∣∣∣. h {\bf{h}} h Every element in x i j ( i = 1 , ⋯ , h , j = 1 , ⋯ , 2 ) {\bf{x}}_{ij}(i=1,\cdots,h,j=1,\cdots,2) xij(i=1,⋯,h,j=1,⋯,2) It's a c c c Vector of the number of channels , Each element is multiplied by the weight matrix to obtain the corresponding element in the output matrix y i j {\bf{y}}_{ij} yij. The derivative of each element is ∂ x i j W ∂ x i j = W \frac{\partial {\bf{x}}_{ij}{\bf{W}}}{\partial {\bf{x}}_{ij}}={\bf{W}} ∂xij∂xijW=W, And there are altogether h × w h\times w h×w Elements :
log det ( ∂ c o n v 2 d ( h ; W ) ∂ h ) = log ( ∣ d e t ( W ) ∣ h ⋅ w ) = h ⋅ w ⋅ log ∣ det ( W ) ∣ \log \det\left(\frac{\partial \mathrm{conv2d({\bf{h}};{\bf{W}})}}{\partial {\bf{h}}}\right)=\log(|\mathrm{det}({\bf{W}})|^{h\cdot w})=h\cdot w \cdot \log |\det ({\bf{W}})| logdet(∂h∂conv2d(h;W))=log(∣det(W)∣h⋅w)=h⋅w⋅log∣det(W)∣ reversible 1 × 1 1\times1 1×1 Convolution depends on inverse matrix W {\bf{W}} W. Because the weight matrix is relatively small , Therefore, the calculation of matrix determinant and inverse is still in a controllable range . - Affine coupling layer : G l o w \mathrm{Glow} Glow The structure design of affine coupling layer and R e a l N V P \mathrm{RealNVP} RealNVP The affine coupling layer is the same .
6 The model of autoregressive flow
An autoregressive constraint is a constraint on a sequence of data x = [ x 1 , ⋯ , x D ] {\bf{x}}=[x_1,\cdots,x_D] x=[x1,⋯,xD] Modeling method : Each output depends only on data observed in the past , Without relying on future data . let me put it another way , Probability of observation x i x_i xi Is dependent on sequence data x 1 , ⋯ , x i − 1 x_1,\cdots,x_{i-1} x1,⋯,xi−1, The product of these conditional probabilities provides the probability of observing the complete sequence : p ( x ) = ∏ i = 1 D p ( x i ∣ x 1 , ⋯ , x i − 1 ) = ∏ i = 1 D p ( x i ∣ x 1 : i − 1 ) p({\bf{x}})=\prod_{i=1}^D p(x_i|x_1,\cdots,x_{i-1})=\prod_{i=1}^D p(x_i|x_{1:i-1}) p(x)=i=1∏Dp(xi∣x1,⋯,xi−1)=i=1∏Dp(xi∣x1:i−1)
6.1 MADE
M A D E \mathrm{MADE} MADE Is a specially designed architecture , Autoregressive attributes can be effectively performed in the auto encoder . When using an automatic encoder to predict conditional probabilities , M A D E \mathrm{MADE} MADE It is not an input that provides different viewing window times to the automatic encoder , Instead, the contribution of some hidden units is eliminated by multiplying the binary mask matrix , So that each input dimension is only reconstructed from a given previous dimension for one-time propagation . Given a L L L A hidden layer fully connected neural network , Its weight matrix is W 1 , ⋯ W L {\bf{W}}^1,\cdots{\bf{W}}^L W1,⋯WL, And an output layer weight matrix V {\bf{V}} V, Each dimension of the output has x ^ i = p ( x i ∣ x 1 : i − 1 ) \hat{x}_i=p(x_i|x_{1:i-1}) x^i=p(xi∣x1:i−1), When there is no mask matrix , The process of neural network forward propagation is as follows : h 0 = x h l = a c t i v a t i o n l ( W l h l − 1 + b l ) x ^ = σ ( V h L + c ) \begin{aligned}{\bf{h}}^0&={\bf{x}}\\{\bf{h}}^l&=\mathrm{activation}^l({\bf{W}}^l {\bf{h}}^{l-1}+{\bf{b}}^l)\\\hat{ {\bf{x}}}&=\sigma({\bf{V}}{\bf{h}}^L+{\bf{c}})\end{aligned} h0hlx^=x=activationl(Wlhl−1+bl)=σ(VhL+c) To zero some connections between layers , Each weight matrix can be simply multiplied by a binary mask matrix by its elements . Each hidden node is assigned a random “ Concatenate integers ”, Be situated between 1 1 1 and D − 1 D-1 D−1 Between ; The first k k k In the middle of the layer l l l The assigned value of cells is expressed as m k l m^l_k mkl. The binary mask matrix is determined by comparing the values of two nodes in the two layers element by element , Then there are h l = a c t i v a t i o n l ( ( W l ⊙ M W l ) h l − 1 + b l ) x ^ = σ ( ( V ⊙ M V ) h L + c ) M k ′ , k W l = 1 m k ′ l ≥ m k l − 1 = { 1 , i f m k ′ l ≥ m k l − 1 0 , o t h e r w i s e M d , k V = 1 d ≥ m k L = { 1 , i f d > m k L 0 , o t h e r w i s e \begin{aligned}{\bf{h}}^l&=\mathrm{activation}^l(({\bf{W}}^l \odot {\bf{M}}^{ {\bf{W}}^l}){\bf{h}}^{l-1}+{\bf{b}}^l)\\\hat{ {\bf{x}}}&=\sigma(({\bf{V}}\odot{\bf{M}}^{\bf{V}}){\bf{h}}^L+{\bf{c}})\\ M_{k^{\prime},k}^{ {\bf{W}}^l}&={\bf{1}}_{m^l_{k^{\prime}}\ge m^{l-1}_k}=\left\{\begin{array}{ll}1,& \mathrm{if}\text{ }m^l_{k^{\prime}}\ge m_k^{l-1}\\0,&\mathrm{otherwise}\end{array}\right.\\M_{d,k}^{ {\bf{V}}}&={\bf{1}}_{d\ge m^L_k}=\left\{\begin{array}{ll}1,&\mathrm{if}\text{ }d>m_k^L\\0,&\mathrm{otherwise}\end{array}\right.\end{aligned} hlx^Mk′,kWlMd,kV=activationl((Wl⊙MWl)hl−1+bl)=σ((V⊙MV)hL+c)=1mk′l≥mkl−1={ 1,0,if mk′l≥mkl−1otherwise=1d≥mkL={ 1,0,if d>mkLotherwise An example is shown in the figure below , A cell in the current layer can only be connected to other cells with the same or smaller random number in the previous layer , And this type of dependency can be easily propagated to the output layer through the network . Once random numbers are assigned to all cells and layers , The order in which dimensions are entered is fixed , And relative to it, it produces a conditional probability . To ensure that all hidden cells are connected to the input and output layers through some paths , sampling m k l m^l_k mkl Equal to or greater than the smallest connected integer in the previous layer min k ′ m k ′ l − 1 \min_{k^{\prime}} m^{l-1}_{k^\prime} mink′mk′l−1
6.2 WaveNet
W a v e N e t \mathrm{WaveNet} WaveNet It consists of a stack of causal convolutions , This is a convolution operation designed to respect sorting : Prediction at a time stamp can only consume data observed in the past , Not dependent on the future . W a v e N e t \mathrm{WaveNet} WaveNet The causal convolution in just moves the output multiple timestamps into the future , So that the output is aligned with the last input element . One of the disadvantages of convolution layer is that the size of perception field is very limited . The output can hardly depend on the input hundreds or thousands of time steps ago , This may be a key requirement for long sequence modeling . therefore , W a v e N e t \mathrm{WaveNet} WaveNet Using extended convolution , The kernel is applied to the uniformly distributed sample subset in the larger perceptual field of input . W a v e N e t \mathrm{WaveNet} WaveNet The gated activation unit is used as the nonlinear layer , Because it is found to be better than in modeling one-dimensional audio data R e L U \mathrm{ReLU} ReLU Work better , Apply residual connection after gating activation , The formula is as follows z = t a n h ( W f , k ⊗ x ) ⊙ σ ( W g , k ⊗ x ) {\bf{z}}=\mathrm{tanh}({\bf{W}}_{f,k}\otimes {\bf{x}})\odot \sigma({\bf{W}}_{g,k}\otimes {\bf{x}}) z=tanh(Wf,k⊗x)⊙σ(Wg,k⊗x) among W f , k {\bf{W}}_{f,k} Wf,k and W g , k {\bf{W}}_{g,k} Wg,k They are the first k k k Layer convolution filter and gate weight matrix , Both are learnable .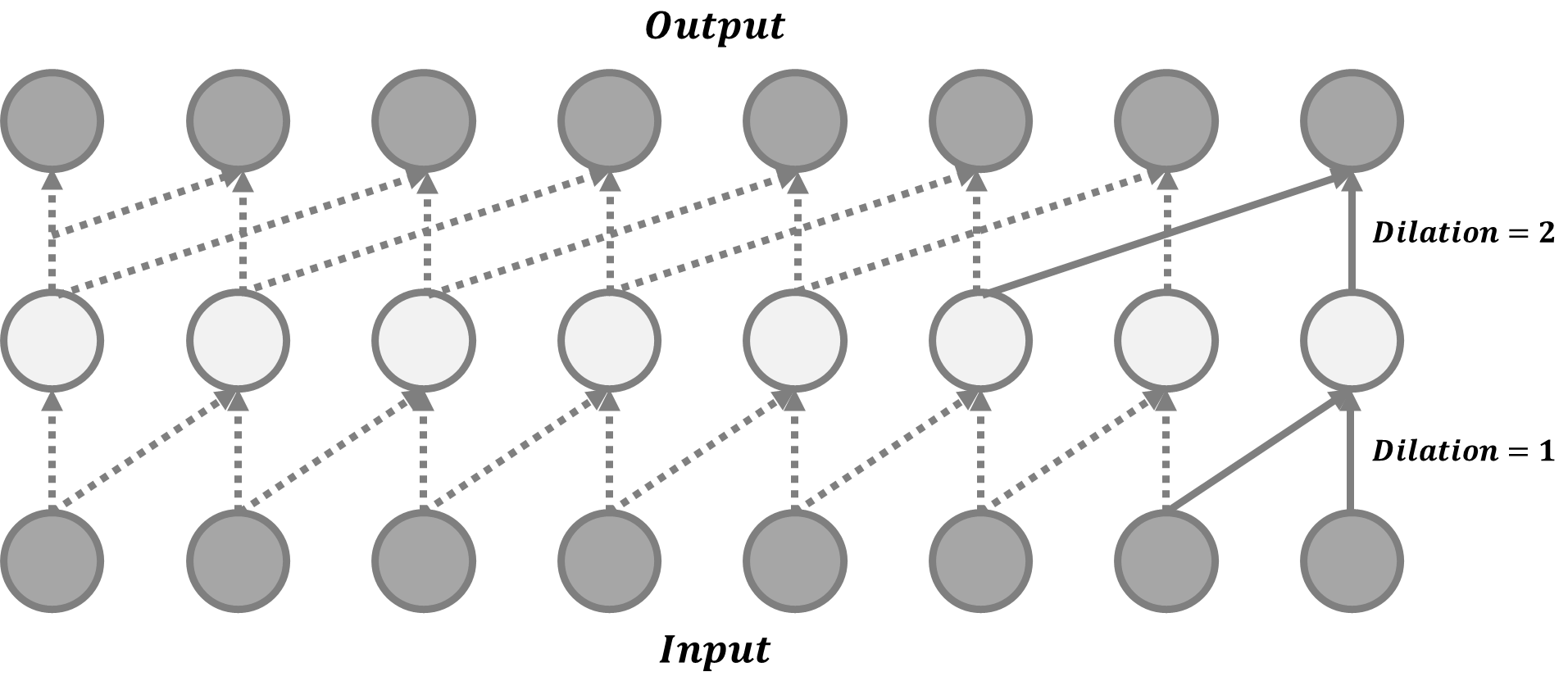
6.3 MAF
M A F \mathrm{MAF} MAF Is a standardized flow , The transformation layer is constructed as an autoregressive neural network . M A F \mathrm{MAF} MAF It's the same as the following I A F \mathrm{IAF} IAF Very similar . Given two random variables z ∼ π ( z ) {\bf{z}}\sim \pi({\bf{z}}) z∼π(z) and x ∼ p ( x ) {\bf{x}}\sim p({\bf{x}}) x∼p(x), And the probability density function π ( z ) \pi({\bf{z}}) π(z) It is known that , M A F \mathrm{MAF} MAF Aims at learning p ( x ) p({\bf{x}}) p(x). M A F \mathrm{MAF} MAF Generate each x i x_i xi In the dimension of the past x 1 : i − 1 {\bf{x}}_{1:i-1} x1:i−1 On condition that . To be exact , The conditional probability is z {\bf{z}} z The affine transformation of , Where the scale and shift terms are x {\bf{x}} x Function of the observation part of . Data generation , Will produce a new x {\bf{x}} x, The formula is as follows x i ∼ p ( x i ∣ x 1 : i − 1 ) = z i ⊙ σ i ( x 1 : i − 1 ) + μ i ( x 1 : i − 1 ) x_i\sim p(x_i|{ {\bf{x}}_{1:i-1}})=z_i\odot \sigma_i({\bf{x}}_{1:i-1})+\mu_i({\bf{x}}_{1:i-1}) xi∼p(xi∣x1:i−1)=zi⊙σi(x1:i−1)+μi(x1:i−1) Given x {\bf{x}} x when , The density is estimated to be p ( x ) = ∏ i = 1 D p ( x i ∣ x 1 : i − 1 ) p({\bf{x}})=\prod_{i=1}^D p(x_i|{\bf{x}}_{1:i-1}) p(x)=i=1∏Dp(xi∣x1:i−1) The method advantage of this framework is that the generation process is sequential , So the design speed is very slow . Density estimation only needs to use M A D E \mathrm{MADE} MADE And so on . The inverse of the transformation function is very simple , Jacobian determinant is also easy to calculate .
6.4 IAF
And M A F \mathrm{MAF} MAF similar , Inverse autoregressive flow I A F \mathrm{IAF} IAF The conditional probability of the target variable is also modeled as an autoregressive model , But with reverse flow , Thus, a very effective sampling process is realized . M A F \mathrm{MAF} MAF The affine transformation in is : z i = x i − μ i ( x 1 : i − 1 ) σ i ( x 1 : i − 1 ) = − μ i ( x 1 : i − 1 ) σ i ( x 1 : i − 1 ) + x i ⊙ 1 σ i ( x 1 : i − 1 ) z_i=\frac{x_i -\mu_i({\bf{x}}_{1:i-1})}{\sigma_i({\bf{x}}_{1:i-1})}=-\frac{\mu_i({\bf{x}}_{1:i-1})}{\sigma_i({\bf{x}}_{1:i-1})}+x_i \odot \frac{1}{\sigma_i({\bf{x}}_{1:i-1})} zi=σi(x1:i−1)xi−μi(x1:i−1)=−σi(x1:i−1)μi(x1:i−1)+xi⊙σi(x1:i−1)1 If you make
x ~ = z , p ~ ( ⋅ ) = π ( ⋅ ) , x ~ ∼ p ~ ( x ~ ) x ~ = x , π ~ ( ⋅ ) = p ( ⋅ ) , z ~ ∼ π ~ ( z ~ ) μ ~ i ( z ~ 1 : i − 1 ) = μ ~ i ( x 1 : i − 1 ) = − μ i ( x 1 : i − 1 ) σ i ( x 1 : i − 1 ) σ ~ ( z ~ 1 : i − 1 ) = σ ~ ( x 1 : i − 1 ) = 1 σ i ( x 1 : i − 1 ) \begin{aligned}&\tilde{ {\bf{x}}}={\bf{z}},\text{ }\tilde{p}(\cdot)=\pi(\cdot),\text{ }\tilde{ {\bf{x}}}\sim\tilde{p}(\tilde{\bf{x}})\\&{\tilde{\bf{x}}}={\bf{x}}\text{ },\tilde{\pi}(\cdot)=p(\cdot),\text{ }{\bf{\tilde{z}}}\sim\tilde{\pi}({\bf{\tilde{z}}})\\&\tilde{\mu}_i(\tilde{\bf{z}}_{1:i-1})=\tilde{\mu}_i({\bf{x}}_{1:i-1})=-\frac{\mu_i({\bf{x}}_{1:i-1})}{\sigma_i({\bf{x}}_{1:i-1})}\\&\tilde{\sigma}(\tilde{ {\bf{z}}}_{1:i-1})=\tilde{\sigma}({\bf{x}}_{1:i-1})=\frac{1}{\sigma_i({\bf{x}}_{1:i-1})}\end{aligned} x~=z, p~(⋅)=π(⋅), x~∼p~(x~)x~=x ,π~(⋅)=p(⋅), z~∼π~(z~)μ~i(z~1:i−1)=μ~i(x1:i−1)=−σi(x1:i−1)μi(x1:i−1)σ~(z~1:i−1)=σ~(x1:i−1)=σi(x1:i−1)1 Then there are x ~ i ∼ p ( x ~ i ∣ z ~ 1 : i ) = z ~ i ⊙ σ ~ i ( z ~ 1 : i − 1 ) + μ ~ i ( z ~ 1 : i − 1 ) , w h e r e z ~ ∼ π ~ ( z ~ ) {\tilde{x}}_i\sim p(\tilde{x}_i|{\bf{\tilde{z}}}_{1:i})=\tilde{z}_i\odot \tilde{\sigma}_i({\bf{\tilde{z}}}_{1:i-1})+\tilde{\mu}_i({\bf{\tilde{z}}}_{1:i-1}),\quad \mathrm{where}\text{ }{\tilde{\bf{z}}}\sim \tilde{\pi}({\bf{\tilde{z}}}) x~i∼p(x~i∣z~1:i)=z~i⊙σ~i(z~1:i−1)+μ~i(z~1:i−1),where z~∼π~(z~) As shown in the figure below , I A F \mathrm{IAF} IAF Intend to estimate known π ~ ( z ~ ) \tilde{\pi}(\tilde{\bf{z}}) π~(z~) Given by x ~ \tilde{\bf{x}} x~ The probability density function of . Countercurrent is also an autoregressive affine transformation , And M A F \mathrm{MAF} MAF identical , But the scale and shift terms are known distributions π ~ ( z ~ ) \tilde{\pi}(\tilde{\bf{z}}) π~(z~) The autoregressive function of the observed variable in .
Single element x ~ i \tilde{x}_i x~i The calculations of are not interdependent , So they are easy to parallelize . It is known that x ~ \tilde{\bf{x}} x~ The efficiency of density estimation is not high , Because it must be restored in sequence z ~ i \tilde{z}_i z~i Value , That is to say z ~ i = ( x ~ i − μ ~ i ( z ~ 1 : i − 1 ) ) / σ ~ i ( z 1 : i − 1 ) \tilde{z}_i=(\tilde{x}_i-\tilde{\mu}_i(\tilde{\bf{z}}_{1:i-1}))/\tilde{\sigma}_i({\bf{z}}_{1:i-1}) z~i=(x~i−μ~i(z~1:i−1))/σ~i(z1:i−1), So the total needs D D D Secondary estimate .
边栏推荐
- 业内首个!可运行在移动设备端的视频画质主观体验MOS分评估模型!
- Thesis reading: General advantageous transformers
- ByteDance Interviewer: how to calculate the memory size occupied by a picture
- 嵌入式DSP音频开发
- R语言惩罚逻辑回归、线性判别分析LDA、广义加性模型GAM、多元自适应回归样条MARS、KNN、二次判别分析QDA、决策树、随机森林、支持向量机SVM分类优质劣质葡萄酒十折交叉验证和ROC可视化
- Packet capturing and sorting out external Fiddler -- understanding the toolbar [1]
- Basic flask: template rendering + template filtering + control statement
- 您的物联网安全性是否足够强大?
- 买股票应该下载什么软件最好最安全?
- [today in history] June 11: the co inventor of Monte Carlo method was born; Google launched Google Earth; Google acquires waze
猜你喜欢

【活动早知道】LiveVideoStack近期活动一览
测试要掌握的技术有哪些?软件测试必懂的数据库设计大全篇

元宇宙标准论坛成立
![[today in history] June 20: the father of MP3 was born; Fujitsu was established; Google acquires dropcam](/img/54/df623fc1004e1dca5d369b4ed2608c.png)
[today in history] June 20: the father of MP3 was born; Fujitsu was established; Google acquires dropcam

Basic flask: template rendering + template filtering + control statement
![[kotlin] basic introduction and understanding of its syntax in Android official documents](/img/44/ec59383ddfa2624a1616d13deda4a4.png)
[kotlin] basic introduction and understanding of its syntax in Android official documents

Tips for visiting the website: you are not authorized to view the recovery method of this page

TensorRT 模型推理优化实现

分布式事务—基于消息补偿的最终一致性方案(本地消息表、消息队列)

Severe Tire Damage:世界上第一个在互联网上直播的摇滚乐队
随机推荐
TensorRT 模型推理优化实现
嵌入式DSP音频开发
没错,是水的一篇
JDBC与MySQL数据库
拾光者,云南白药!
Flask Foundation: template inheritance + static file configuration
导致系统性能失败的十个原因
面试:Bitmap像素内存分配在堆内存还是在native中
Simple elk configuration to realize production level log collection and query practice
Heartless sword Chinese English bilingual poem 004 Sword
math_(函数&数列)极限的含义&误区和符号梳理/邻域&去心邻域&邻域半径
[today in history] June 11: the co inventor of Monte Carlo method was born; Google launched Google Earth; Google acquires waze
转载文章:数字经济催生强劲算力需求 英特尔发布多项创新技术挖掘算力潜能
Initial linear regression
Why are so many people keen on big factories because of the great pressure and competition?
RichView TRVStyle ParaStyles
Packet capturing and sorting out external Fiddler -- understanding the toolbar [1]
Différences d'utilisation entre IsEmpty et isblank
将PCAP转换为Json文件的神器:joy(安装篇)
无心剑英汉双语诗004.《静心》