当前位置:网站首页>[2022 freshmen learning] key points of the second week
[2022 freshmen learning] key points of the second week
2022-07-23 16:28:00 【AI frontier theory group @ouc】
Video learning content discussion
1、 Why do visual tasks use Convolutional Neural Networks ?

2、 Parameter calculation of convolution ?
Formula for : k × k × C i n × C o u t k\times k\times C_{in} \times C_{out} k×k×Cin×Cout , Pay attention to this and feature map It doesn't matter the size of . Suppose the input layer is a size of 64×64 Pixels 、 Three channel color picture , Request output 4 individual Feature Map, And the size is the same as the input layer . The whole process can be described by the following figure :

The convolution layer consists of 4 individual Filter, Every Filter Contains 3 individual Kernel, Every Kernel The size is 3×3. Therefore, the parameter quantity of convolution can be calculated by the following formula :3x3x3x4=108.
3、 What do the lower and higher layers of neural networks learn respectively ?

Low level networks pay more attention to details , High level networks pay more attention to semantic concepts . meanwhile , Different convolution kernels focus on different things .
With academic stories : 2012 year ,AlexNet Great success , Companies are paying high prices for this technology .Hinton After consulting someone , Set up a company without products DNNResearch, There are only three employees . then , On 2012 year 12 A auction was organized in August , Google 、 Baidu 、 Microsoft and DeepMind Participated in the auction . In the beginning, it was 100 Million dollars increase , Later, it was completely uncontrollable , The final price is 4400 Thousands of dollars . Interested can baidu 《 The year of the rise of deep learning , Baidu almost signed Hinton》.
4、CNN The development of
2018 In the special video recorded in, only AlexNet, VGG, GoogleNet, ResNet, The latest model is not included , below PPT From Tsinghua Huang Gao 2022 Latest report in 《 Research frontier and discussion of visual backbone model 》, That's a very good summary , You can learn the models mentioned by yourself .



7、GoogleNet

2014 year ImageNet The champion of the competition , Error rate from 2013 Year of 11.7 Down to 6.7. The network contains 22 layer , The number of parameters is greatly reduced , No, FC layer .GoogleNet Yes V1、V2、V3、V4 Equal Edition , The core of the design is Inception modular (GoogleNetV1), The core idea is the parallel convolution kernel of multiple scales . among ,3X3 The branch parameter quantity of is 3x3x256x192=442,368, There is still room for optimization of parameter quantities .( The role of auxiliary classifier ? Some are like layer by layer pre training )

Google researchers also found this problem , therefore , Proposed in the second year GoogleNetV2 in , Join in 1x1 The convolution of feature map drop to 64, Solve the problem of excessive parameters . such ,3X3 The parameter quantity of the branch is 1x1x256x64+3x3x64x192 = 126, 976.
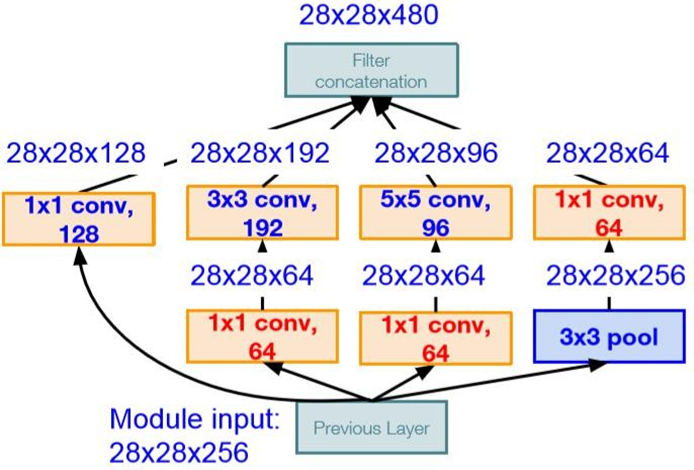
To GoogleNetV3, The main improvement is 5x5 The convolution of is decomposed into two 3x3.( The parameters are from 25 drop to 18)

8、ResNet
2015 year ImageNet The champion of the competition , Error rate from 6.7 Down to 3.57%, The Internet has 152 layer . The team from China has reached the peak of artificial intelligence for the first time , get CVPR2016 Of Best Paper. The related introduction of author he Kaiming can be found in the article 《AI genius 》, The story of young genius continues .

Residual thought : Remove the same main part , So as to focus on learning small changes , It can be used to train very deep Networks .

Code practice content discussion
1、 about MNIST data classification , Why disturb the order of pixels , The effect is very poor ? Why can fully connected networks still be classified relatively accurately ?

3、transform in , Different values are taken , What's the difference between this ?
It mainly plays the role of data normalization , The impact may not be great . Someone in code 2 is right CIFAR10 The data of , This value can normalize the data set to a mean of 0, The variance of 1.
4、epoch and batch The difference between ?
5、1x1 Convolution sum of FC What's the difference? ? What role does it play ?
In essence, it is the full connection layer on the channel , Generally, it plays the role of feature dimension reduction , Reduce the amount of network parameters .
6、Residual leanring Why can we improve the accuracy ?
This is a classic question , There are many answers on the Internet , Let's have a look for ourselves .UNet In the structure skip connection It's a principle .
7、 Code exercise 2 , The Internet and 1989 year Lecun Proposed LeNet What's the difference? ?
The size of the data is different ,CIFAR10 yes 32x32, but MNIST yes 28x28. The activation function is different ,LeNet It uses sigmoid Activation function , But what we use in our code is ReLU.
8、 Code exercise 2 , After convolution feature map It's going to get smaller , How to apply Residual Learning?

class Bottleneck(nn.Module):
def __init__(self, in_planes=256, planes=64):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, in_planes, kernel_size=1)
self.bn3 = nn.BatchNorm2d(in_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out = out + x
out = F.relu(out)
return out
9、 What methods can further improve the accuracy ?
If you're interested , Recommend students to have a look self-attention(SENet,CBAM,ECANet etc. ) Related papers .
边栏推荐
- Do you know why PCBA circuit board is warped?
- Niuke-top101-bm36
- Bean Validation入门篇----02
- Purpose of wsastartup function
- 聊一聊JVM的内存布局
- 将.calss文件转为.jar-idea篇
- Dark horse programmer - interface test - four day learning interface test - third day - advanced usage of postman, export and import of Newman case set, common assertions, assertion JSON data, working
- 24 道几乎必问的 JVM 面试题,我只会 7 道,你能答出几道?
- 【Taro】小程序picker动态获取数据
- FPGA HLS multiplier (pipeline vs. ordinary simulation)
猜你喜欢

Kubernetes 基本概念和部署

LeetCode高频题:最少经过几次操作可以使数组变为非降序状态
![[cloud native] continuous integration and deployment (Jenkins)](/img/3a/2cd6f0c768bd920b3de6d4f5b13cd5.png)
[cloud native] continuous integration and deployment (Jenkins)

Bean validation core components - 04

Mysql客户端到服务端字符集的转换
【2022新生学习】第二周要点

MySQL-字符串按照数值排序
FPGA-HLS-乘法器(流水线对比普通仿真)

The competition boss is in Huawei: network experts are from Stanford physics department, and some people "work as much as reading a doctoral degree"

Mysql—六大日志
随机推荐
2022 blue hat cup preliminary WP
JSP之自定义jstl标签
Redis installation
Flutter | 给 ListView 添加表头表尾最简单的方式
Middle aged crisis, retired at the age of 35, what do migrant workers take to compete with capitalists?
Three handling strategies of deadlock
How to solve the problem of forgetting the Oracle password
lc marathon 7.23
Talk about the memory layout of JVM
FPGA HLS multiplier (pipeline vs. ordinary simulation)
“1+1>10”:无代码/低代码与RPA技术的潜在结合
MySQL表字段数量限制以及行大小限制
Bean validation specification ----03
es6把多个class方法合并在一起
Mysql—主从复制
满足多种按键的高性价比、高抗干扰触摸IC:VK3606D、VK3610I、VK3618I 具有高电源电压抑制比
FPGA-HLS-乘法器(流水线对比普通仿真)
Oracle中实现删除指定查询条件的所有数据
20220721挨揍内容
Mysql—六大日志