当前位置:网站首页>[website architecture] the unique skill of 10-year database design, practical design steps and specifications
[website architecture] the unique skill of 10-year database design, practical design steps and specifications
2022-06-23 12:51:00 【Stop refactoring】

In this issue , Let's talk about database design , Before we start talking about database design , Let's make a point first , Database is the core of most business systems , Database design is also very important .
however , This does not mean that database design is a difficult thing , For our technical support team , We always insist that the back-end developers design the database directly ( No matter how much experience this developer has ) , Instead of letting experienced developers do the work of database design ( Experienced developers can do a good job of review ).
This is because :
1、 It is not necessary to design the database completely at one time In the development process , It is inevitable that the database needs to be adjusted , As long as the database skeleton is OK ( Experienced developers can do a good job of review ) , Such as adding or deleting fields 、 Add intermediate table 、 Adding views and so on will not have much impact .
2、 Database design is the process of transforming the requirements of the back-end part ( General business systems ), For example, prototype design is the requirement transformation process of the front-end part , Divide the database into databases and tables You can roughly describe the structure of the back-end functions ( General business systems ), If the back-end developer skips the database design ( Design using someone else's database ) , It is inevitable that the functional structure cannot be distinguished , You can only guess which interfaces you need from the page prototype , This working mode of seeing a function develop an interface , No matter how well the code is written , In most cases, there will be uncontrollable development progress 、 Develop redundant interfaces 、 Missing interface, etc .
therefore , Database design is a skill that every back-end developer must master , And database design is not difficult We don't want to design the database completely at once , We just need to design the skeleton ( It shall be adjusted during design review and subsequent development ) .
The database design steps we recommend are as follows 3 A step :
sub-treasury ( By the architect or technical leader )
table ( Done by developers )
Add redundant fields 、 View ( Done by developers )
1、 sub-treasury
It is often seen that some systems have only one database , There are hundreds of thousands of watches in this library , Believe no matter E-R The picture has to be more detailed , Or how well it is written No one can figure out their relationship . This is undoubtedly one of the main reasons why the system is getting worse , It is also one of the reasons why microservices can not play the role they should have ( Using the same database , It's no use expanding more servers with back-end services ).
So the purpose of the sub Treasury : One is to reduce the complexity of data tables in a single database ( Easier to understand ); The second is to expand the server later , More targeted expansion ( Only extend the parts with high request pressure ).
The principle of database distribution is very simple , generally speaking , Each subsystem corresponds to a database . Such as user system 、 The blog system 、 Mall system 、 Each process system has its own independent database , The system division is more determined by the business architecture , For business architecture design, please refer to our previous video on business architecture , in addition , For some subsystems with closely related data , Such as coupon and fund system , It is better to merge into one system .

Of course , There will be some problems after the database is independent , For most scenarios , You can integrate multiple interfaces by calling the front end , But such as some scenarios that require strong data consistency , Database distributed database transactions will be involved , The database distributed transaction will be introduced in detail in the next issue .
2、 table
The sub table depends more on the business functions of the current module , Take a blog system as an example The main business logic is , Users blog , After the administrator reviews , Other users can view , And you can comment below the blog , That is, you can create four corresponding tables . however , Because auditing is actually a status , Record with one field , So only two tables are needed , One is the blog table 、 The second is the comment form .

After defining the main tables You need to look at all the function points of this system , See if you need to add additional tables , If you find that there is a collection function in the blog system , Consider adding a collection table .
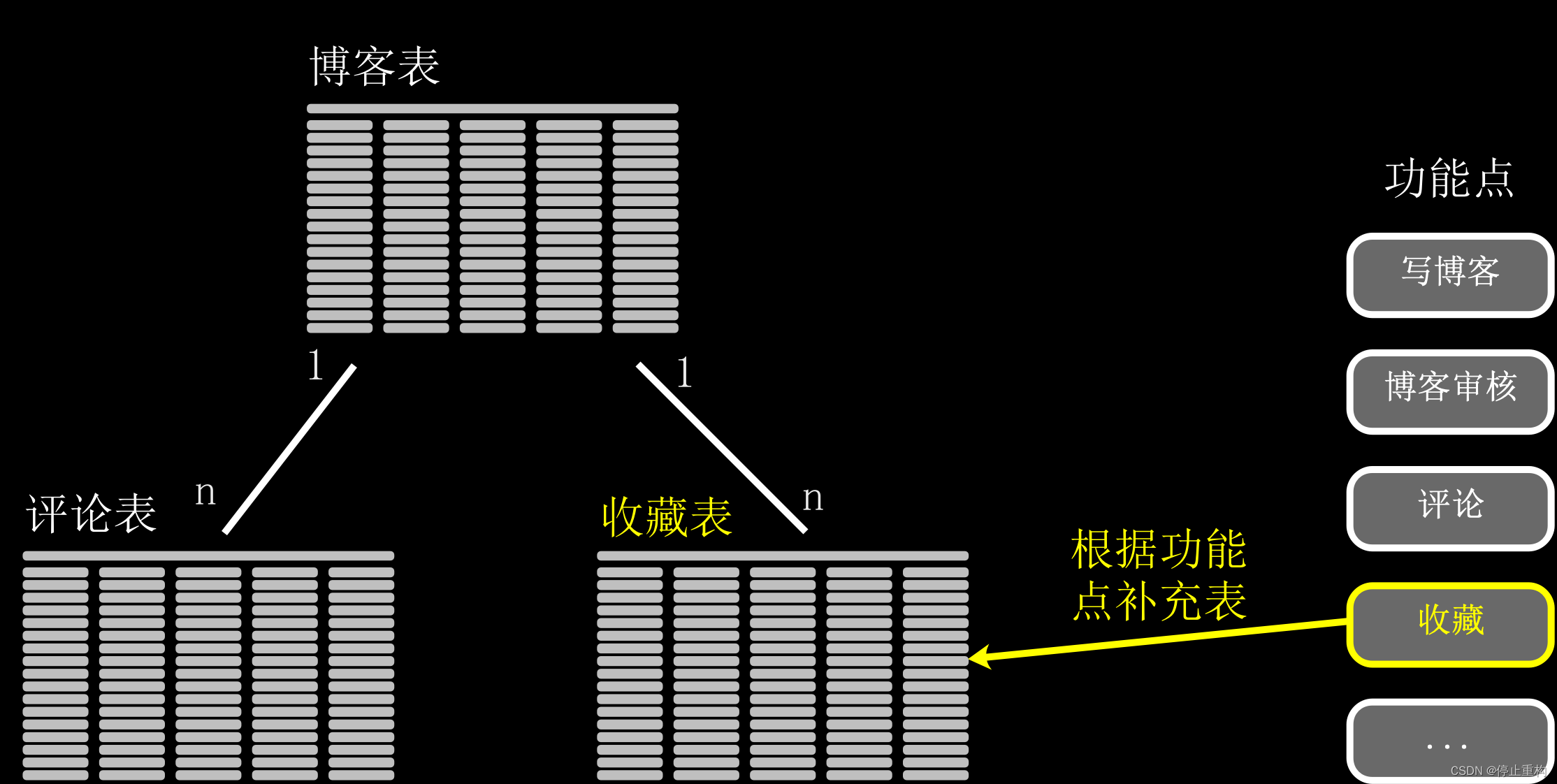
After the sub table is completed , You also need to analyze whether there is a many to many relationship between tables . For example, there are tag categories in blogs , So blog and tag are many to many .
There are two solutions to this many to many relationship :
- Create intermediate table records ;
- Record this relationship with one or more fields in one of the tables .

After the sub table is completed , The functional structure of a module is outlined , At development time , It is also obvious which functions are the main 、 Which functions are secondary So that the development plan is more clear 、 The front and rear end continuous adjustment can also be completed in stages . After tabulation , The structure of a single database is basically clear , But for some special functions , For example, in the comment list of the personal Center , In addition to displaying comments , You also need to display the name of the blog .
3、 Add redundant fields 、 View
At this point, consider adding redundant fields , That is, record the name of the blog in the comment form ( It has been recorded in the blog table ) Of course , Updating redundant fields is troublesome , Therefore, redundant fields are suitable for fields with low update frequency or fields that are not allowed to be updated .

Of course , Except for redundant fields , It can also be done through SQL Statement to implement Kwa table query , For this kind of Kwa table query , We prefer to use views , A view is simply a saved item in the database SQL Query statement , Views simplify the back end SQL Sentence complexity , You can also find out which interfaces use the view to know that it has made cross table queries ( Facilitate subsequent performance tuning ).
for example , You need to rank popular blogs by popularity , The popularity is based on the number of collections 、 Number of likes 、 The number of comments multiplied by their respective weights . Then you can create a view to create a virtual table of blog popularity , With a simple SQL Statement can be used to query the heat before 3 The blog of ( The actual project needs to add Redis cache ), You can also use a simple SQL Statement can be used to query the heat under a certain category 3 The blog of ( The actual project needs to add Redis cache ).

View in addition to the above benefits , One more benefit : Cross database query ( Although directly used SQL Statements can also do , But the view can be more structured ), If multiple databases are in the same MySQL In service , Then the view can be queried by the database ( Ordinary SQL Statement can also ), If the database is in a different MySQL In service (MySQL5.7 in the future ), You can also synchronize the data to be queried through data synchronization , Then query through the view library . Of course , Generally, this method is not commonly used for large websites , Because if the data volume of the synchronized database is too large or the update frequency is high , The gains often outweigh the losses .
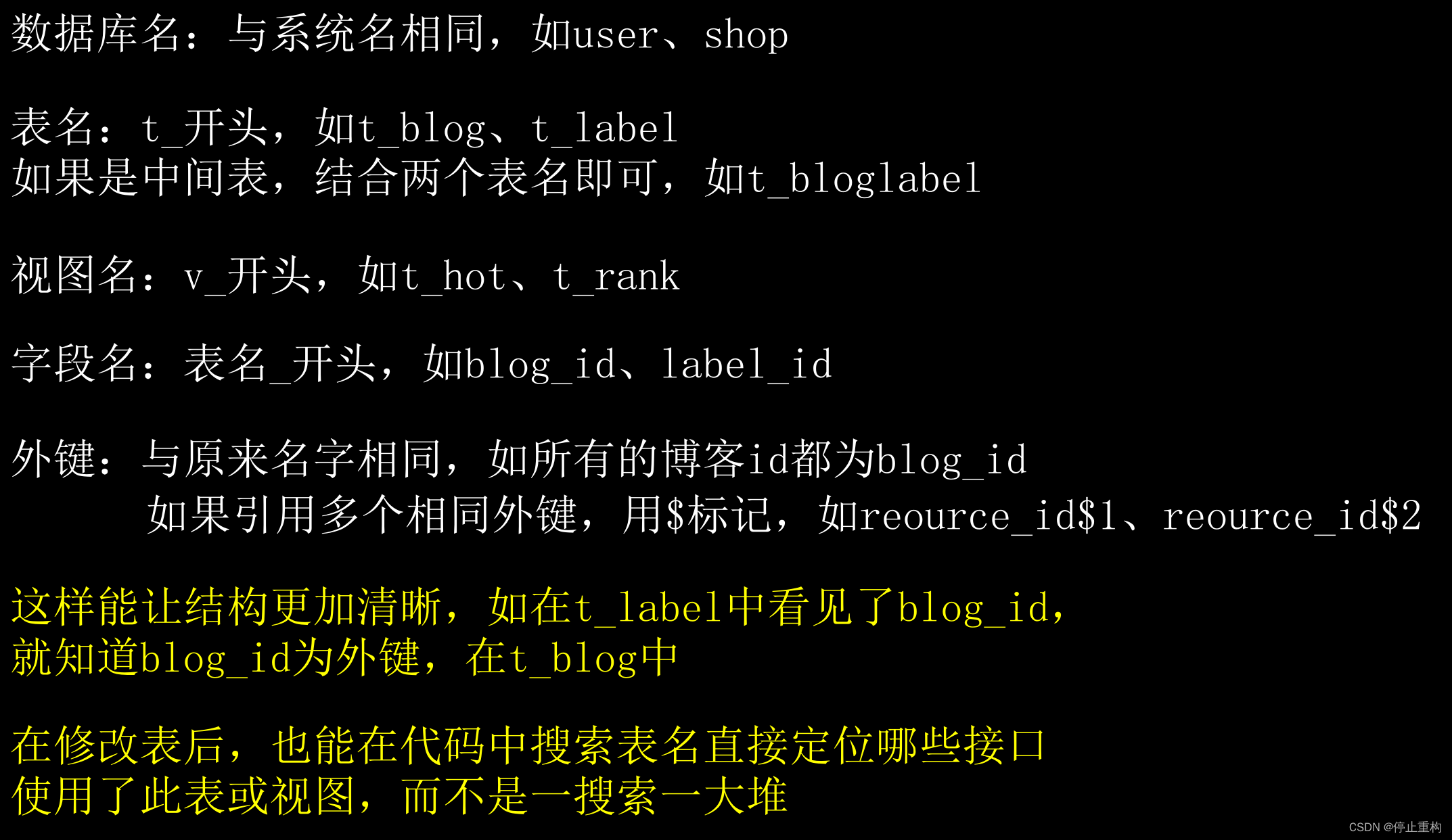
Naming specification
Our recommended database naming conventions are as follows , The name of the database is the same as the system name , Table name t_ start , View to v_ start Fields in the table , If it is unique in the table , Use table name _ start , If it's a foreign key , Use its original name , The view does not change the name of the field . such , Even without E-R chart , You can also judge the relationship between tables by field names . Although it seems simple , But it can prevent many unnecessary bug.
summary
Database design also includes indexing 、 Specific fields 、 Field type and length . However, these problems can be added in the actual development process , It is a waste of time to think about these problems too carefully at the beginning ( Unless required by Party A or the business department ).
The above is our recommended database design process Of course , There is never an absolute optimal solution for database design , Whether the database design is relatively reasonable depends on the understanding of business functions and project experience .
But don't worry about doing it well , Because if you don't do it, you can never do it well , Just do it several times and be reviewed by experienced people several times , I believe your database design will be more and more mature .
边栏推荐
- Machine Learning Series 5: distance space (1)
- DevEco Device Tool 助力OpenHarmony设备开发
- UI框架
- If there is a problem with minority browsers, do you need to do a compatibility test?
- Capacity limited facility location problem
- 09 -- palindrome pair
- 二維激光SLAM( 使用Laser Scan Matcher )
- QT knowledge: QT widgets widget function [02]
- Transformers are RNNs (linear transformer)论文阅读
- < Sicily> 1001. Rails
猜你喜欢
![Halcon principle: one dimensional function_ 1D type [2]](/img/54/570c6e739be1ab9caa9df805965b57.png)
Halcon principle: one dimensional function_ 1D type [2]

根据你的工作经历,说说软件测试中质量体系建设

Excel-vba quick start (I. macros, VBA, procedures, types and variables, functions)
二維激光SLAM( 使用Laser Scan Matcher )

CRMEB知识付费如何二开阿里云短信功能

Chinatown hiking: feel the strong Chinese flavor in the exotic New York

QT knowledge: using the qgraphicspixmapitem class
![解决“Thread 1: “-[*.CollectionNormalCellView isSelected]: unrecognized selector sent to instance 0x7f”](/img/35/65511c49eca5ae8a1896d776b479d9.jpg)
解决“Thread 1: “-[*.CollectionNormalCellView isSelected]: unrecognized selector sent to instance 0x7f”

Huawei cloud gaussdb heavily released HTAP for commercial use, defining a new paradigm of cloud native database 2.0
华为云GaussDB重磅发布HTAP商用,定义云原生数据库2.0新范式
随机推荐
sql增加表记录的重复问题。
Network foundation and framework
用户行为建模
DuPont analysis: what is the investment value of Anyang Iron and Steel Co., Ltd?
一个 BUG 开发表示用户不会这样操作,无需修复,测试人员如何应对?
kubernetes comfig subpath
Chinatown hiking: feel the strong Chinese flavor in the exotic New York
How to test the third-party payment interface?
HomeKit支持matter协议,这背后将寓意着什么?
【网站架构】10年数据库设计浓缩的绝技,实打实的设计步骤与规范
【基础知识】~ 数据位宽转换器
A bug development means that the user will not operate like this, and there is no need to repair it. How should testers respond?
Design of routing service for multi Activity Architecture Design
C# 文件下载方式
UI框架
华为云GaussDB重磅发布HTAP商用,定义云原生数据库2.0新范式
涉及第三方支付接口,怎么测?
Oracle database's dominant position is gradually eroded by cloud competitors
Synergetic process
mysql中innodb下的redo log什么时候开始执行check point落盘的?